MetaVQA
收藏资源简介:
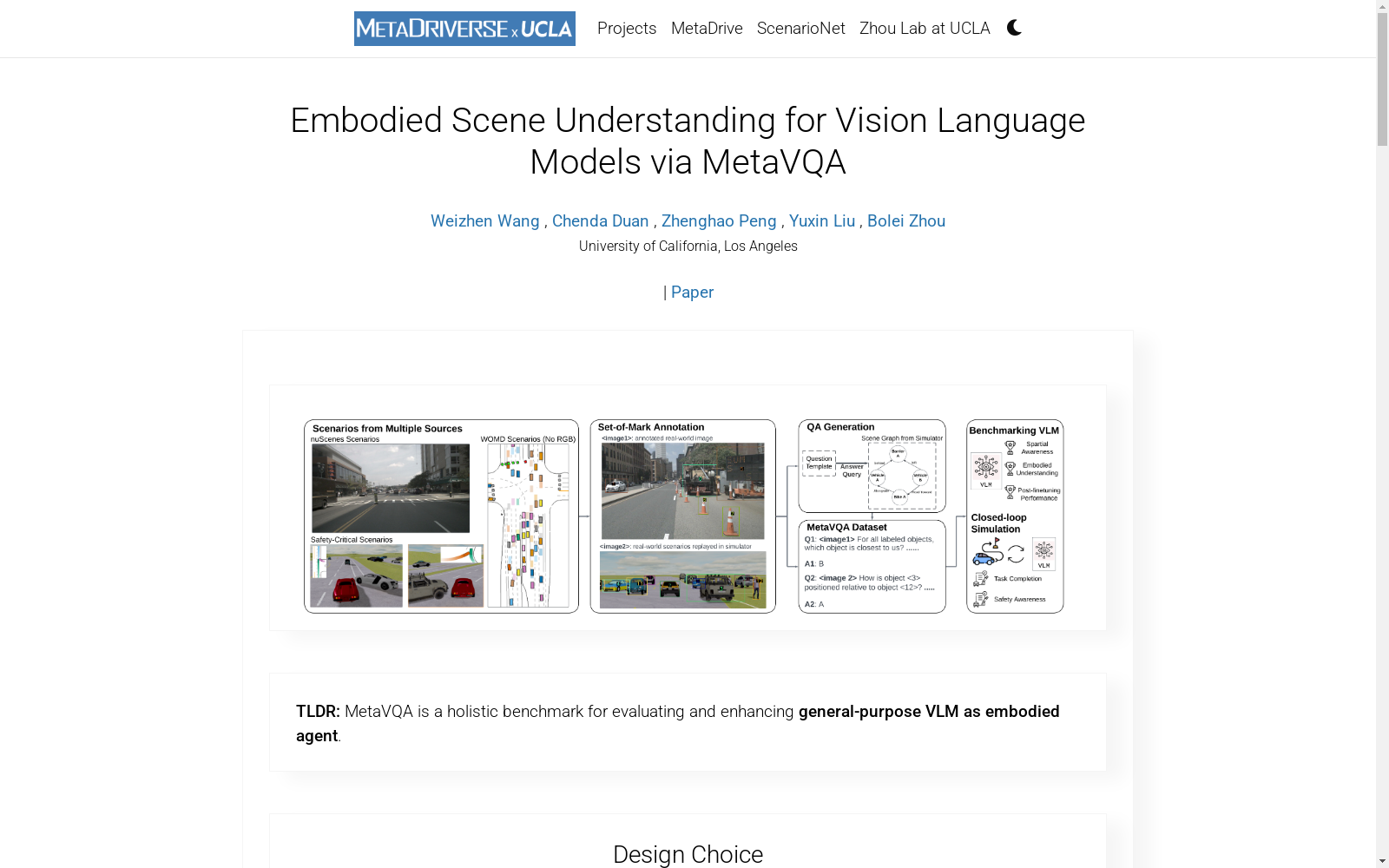
MetaVQA数据集由加利福尼亚大学洛杉矶分校的研究团队创建,旨在评估和增强视觉语言模型(VLMs)在空间推理和场景理解方面的能力。该数据集结合了nuScenes和Waymo数据集中的真实世界交通场景,利用Set-of-Mark提示和自上而下的视图注释,自动生成大量的问题-答案对。数据集包含丰富的对象中心和上下文丰富的指令,确保了对多样化交通场景的覆盖。通过MetaDrive模拟器,数据集还生成了安全关键的驾驶场景,用于闭环模拟评估。MetaVQA数据集的应用领域包括自动驾驶和仓库机器人等,旨在解决VLMs在安全关键模拟中的空间推理和场景理解问题,显著提升了模型的安全意识和决策能力。
The MetaVQA dataset was developed by a research team at the University of California, Los Angeles, with the goal of evaluating and enhancing the spatial reasoning and scene understanding capabilities of Vision-Language Models (VLMs). This dataset integrates real-world traffic scenarios from the nuScenes and Waymo datasets, and automatically generates a large volume of question-answer pairs by leveraging Set-of-Mark prompts and top-down view annotations. The dataset includes abundant object-centric and context-rich instructions, ensuring comprehensive coverage of diverse traffic scenes. Via the MetaDrive simulator, the dataset also produces safety-critical driving scenarios for closed-loop simulation-based evaluation. The application areas of the MetaVQA dataset cover autonomous driving, warehouse robotics and other fields, aiming to address the spatial reasoning and scene understanding challenges of VLMs in safety-critical simulations, and substantially improving the models' safety awareness and decision-making abilities.
- 1Embodied Scene Understanding for Vision Language Models via MetaVQA加利福尼亚大学洛杉矶分校 · 2025年


