AILab-CVC/SEED-Data-Edit
收藏Hugging Face2024-05-10 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/AILab-CVC/SEED-Data-Edit
下载链接
链接失效反馈官方服务:
资源简介:
SEED-Data-Edit是一个用于指令引导图像编辑的混合数据集,总计包含3.7百万个图像编辑对。数据集由三部分组成:第一部分是通过自动化管道生成的大规模高质量编辑数据(3.5百万编辑对);第二部分是从互联网收集的真实场景数据(52千编辑对);第三部分是人工标注的高精度多轮编辑数据(95千编辑对,包含21千多轮次,最多5轮)。数据集的使用受到CC-BY-NC-4.0许可的限制,仅用于非商业研究目的。
SEED-Data-Edit is a mixed dataset designed for instruction-guided image editing, containing a total of 3.7 million image editing pairs. The dataset consists of three parts: the first part is large-scale high-quality editing data generated via an automated pipeline, with 3.5 million editing pairs; the second part is real-world scene data collected from the Internet, with 52 thousand editing pairs; the third part is manually annotated high-precision multi-turn editing data, including 95 thousand editing pairs (covering 21 thousand multi-turn instances with up to 5 turns per instance). The use of this dataset is restricted under the CC-BY-NC-4.0 license, and it is only permitted for non-commercial research purposes.
提供机构:
AILab-CVC
原始信息汇总
数据集概述
数据集名称
- SEED-Data-Edit
数据集用途
- 用于指令引导的图像编辑
数据集组成
- Part-1: 大规模高质量编辑数据,由自动化管道生成(3.5M编辑对)。
- Part-2: 从互联网收集的实际场景数据(52K编辑对)。
- Part-3: 由人类标注的高精度多轮编辑数据(95K编辑对,21K多轮回合,最多5轮)。
数据集大小
- 总大小:3.7M编辑对
- 分类:1M<n<10M
数据集语言
- 英语(en)
数据集许可证
- CC-BY-NC-4.0:仅限于非商业研究目的。
数据集下载链接
数据集引用
bash @article{ge2024seed, title={SEED-Data-Edit Technical Report: A Hybrid Dataset for Instructional Image Editing}, author={Ge, Yuying and Zhao, Sijie and Li, Chen and Ge, Yixiao and Shan, Ying}, journal={arXiv preprint arXiv:2405.04007}, year={2024} }
搜集汇总
数据集介绍
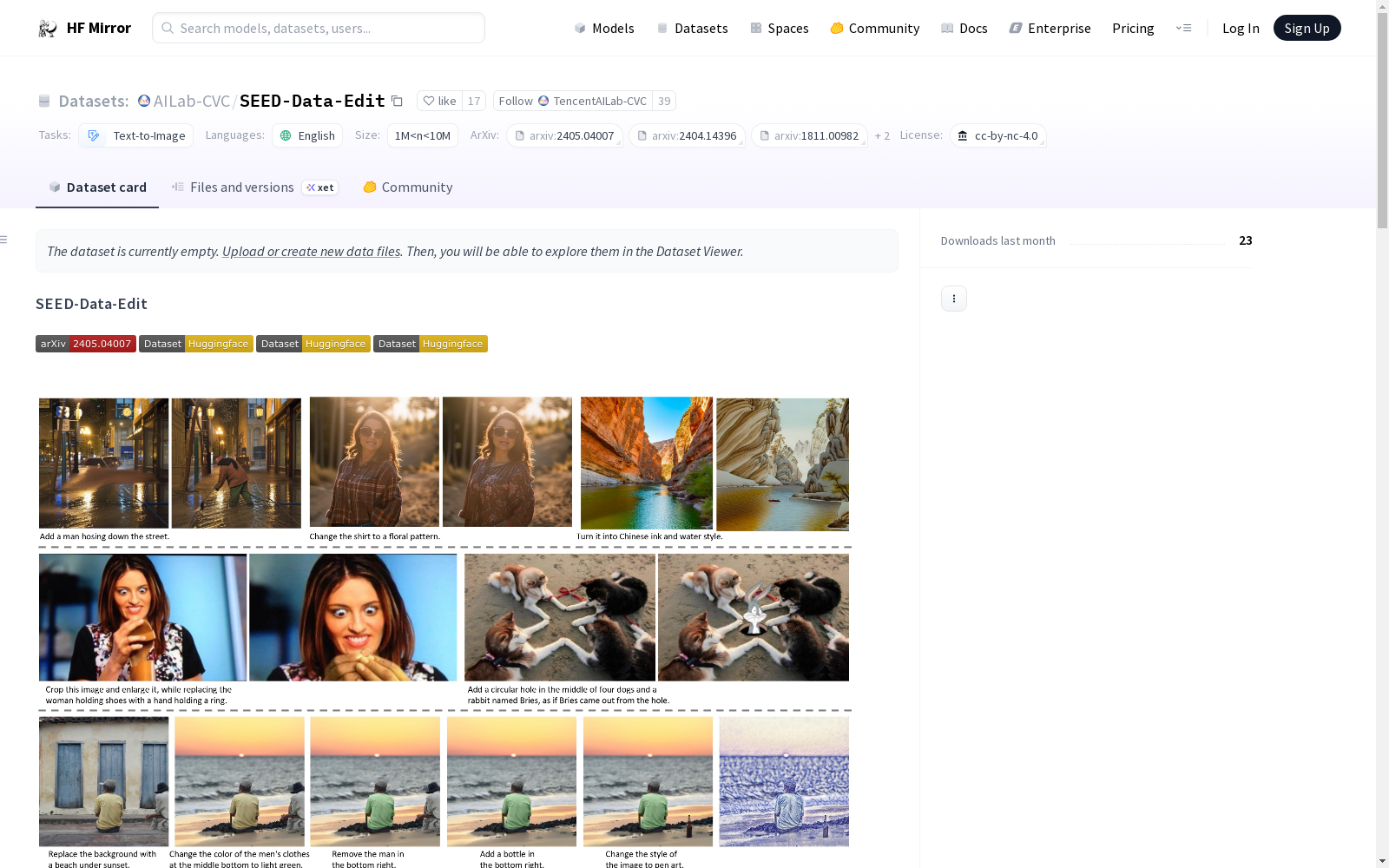
构建方式
SEED-Data-Edit数据集的构建融合了自动化管道生成的高质量编辑数据、互联网收集的实际场景数据以及人工注释的高精度多轮编辑数据,总计包含了3.7百万对图像编辑样本。其中,Part-1通过自动化管道生产了3.5百万对大规模高质量编辑数据;Part-2从互联网收集了5.2万对实际场景数据;Part-3则由人工标注,形成了9.5万对高精度编辑数据,包括2.1万轮最多可达5轮的多轮编辑对话。
特点
该数据集的特色在于其混合性质,不仅包含了自动化生成的大规模数据,还纳入了真实世界的场景数据以及人工精细标注的多轮编辑数据,从而为指令引导的图像编辑研究提供了丰富且多样化的资源。其规模之大、类型之全、标注之精准,均为同类数据集所少见,对于推动图像编辑技术的发展具有重要的科研价值。
使用方法
用户可根据需要单独下载数据集的不同部分。对于SEED-Data-Edit的应用,用户可以参考其衍生的SEED-X-Edit图像编辑模型,该模型是基于SEED-X预训练模型,通过SEED-Data-Edit进行指令微调而得。用户在使用SEED-X-Edit进行推断时,可以参照SEED-X的相关指南进行操作。
背景与挑战
背景概述
SEED-Data-Edit数据集,作为一项旨在推动指令引导图像编辑领域发展的研究资源,于2024年发布。该数据集由AILab-CVC团队精心构建,汇集了大规模高质量编辑数据,涵盖了自动化流程生成的数据、互联网收集的实际场景数据以及人工注释的高精度多轮编辑数据。SEED-Data-Edit的创建,旨在为图像编辑算法提供丰富的训练素材,推动相关技术的进步,并在学术界产生了广泛的影响力。
当前挑战
SEED-Data-Edit数据集的构建过程中,研究团队面临着多方面的挑战。首先,在数据集的多样性与准确性之间寻求平衡,确保数据能够覆盖广泛的编辑指令。其次,对大规模数据的高效处理与存储,以及对互联网数据的版权问题进行了妥善处理。此外,数据集在应用中还面临如何准确反映实际用户编辑需求的挑战,这要求不断优化数据集结构与编辑算法,以提升模型的泛化能力。
常用场景
经典使用场景
在指令引导的图像编辑领域,SEED-Data-Edit数据集以其综合性的数据构成,成为了研究与实践的重要资源。该数据集支持的研究人员通过自动化管道生成大规模高质量编辑数据,进而训练和优化图像编辑模型,以实现从简单到复杂编辑指令的精准响应。
衍生相关工作
基于SEED-Data-Edit数据集,研究者们已成功开发出了SEED-X-Edit图像编辑模型,并通过指令微调技术提升了模型的编辑能力。此外,该数据集的发布也催生了一系列关于图像编辑性能评估、数据集构建方法等领域的深入研究。
数据集最近研究
最新研究方向
在当前的计算机视觉研究领域,指令引导的图像编辑技术正日益受到关注。SEED-Data-Edit数据集作为此类研究的最新成果,汇集了大规模高质量编辑数据,旨在推动图像编辑技术的进步。该数据集涵盖了自动化管道生成的编辑数据、现实场景中收集的数据以及人工注释的高精度多轮编辑数据,为研究者在图像编辑模型的训练与评估上提供了丰富的资源。SEED-Data-Edit不仅促进了图像编辑算法的精确度和实用性,还为相关领域的学术探讨和技术创新提供了强有力的数据支撑。
以上内容由遇见数据集搜集并总结生成


