iac-eval-v2
收藏Hugging Face2026-05-11 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/iac-eval-v2/iac-eval-v2
下载链接
链接失效反馈官方服务:
资源简介:
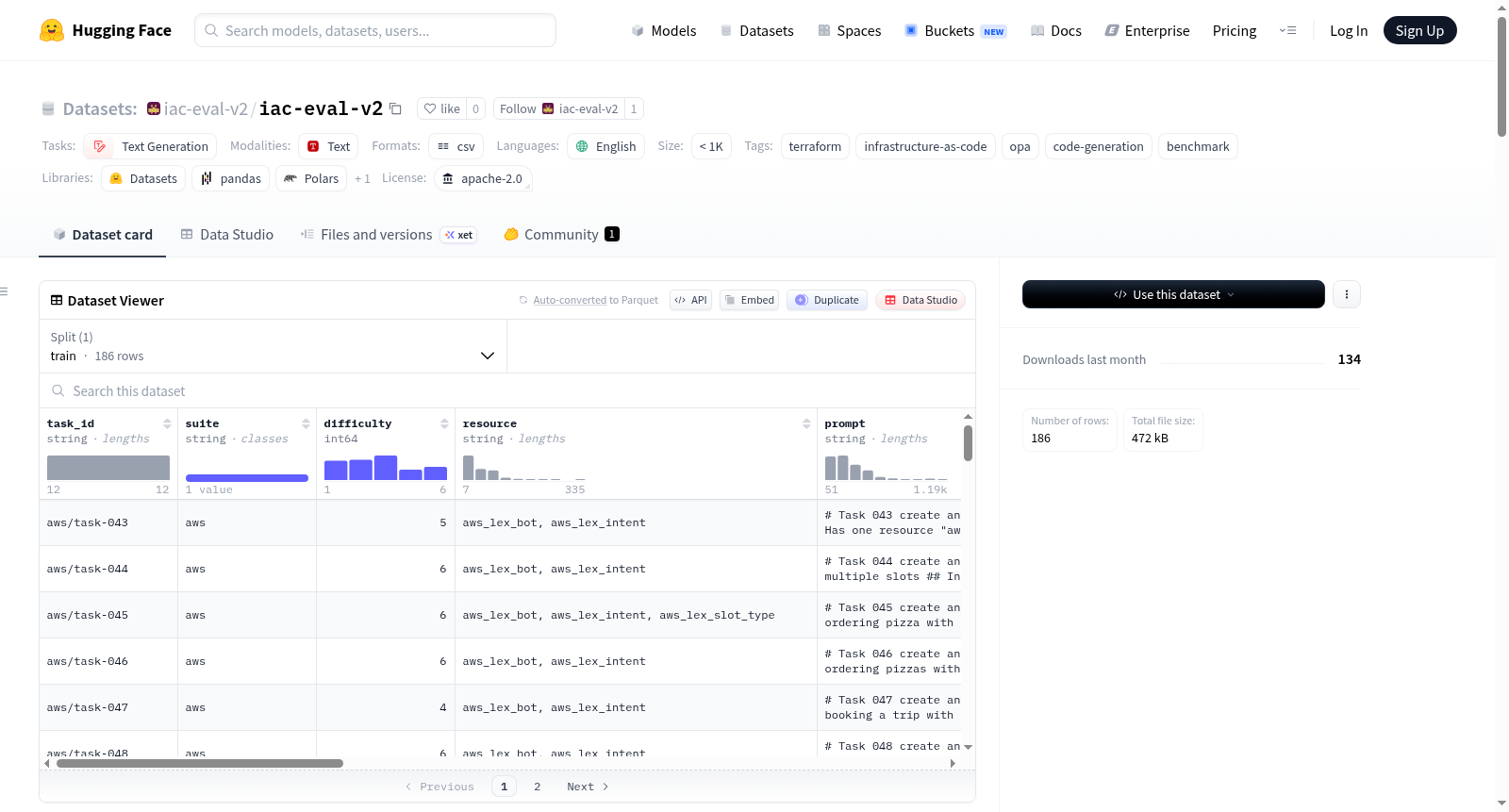
IaC-Eval v2 是一个现代化的 Terraform 代码生成基准测试数据集,是 NeurIPS 2024 IaC-Eval 基准的更新和扩展版本。该数据集专门用于评估大型语言模型在生成符合特定策略约束的云基础设施即代码(IaC)程序方面的能力。数据集包含 186 个经过验证的任务(目前仅限 AWS 环境),每个任务都配有自然语言描述、结构化约束意图、用于评分的 OPA Rego v1 策略、黄金标准的 HCL 参考输出以及所需的 Terraform 和 OPA 版本信息。任务难度分为 1(简单)到 6(专家)六个等级,覆盖了 34 种不同的 AWS 服务。评分机制是确定性的,依赖于 `terraform plan` 和 `opa eval` 的通过与否,而非使用 LLM 作为评判者。数据集采用扁平 CSV 格式,旨在为代码生成模型,特别是在云基础设施自动化领域,提供一个可靠、可复现的评估基准。
IaC-Eval v2 is a modern benchmark dataset for Terraform code generation, serving as an updated and expanded version of the NeurIPS 2024 IaC-Eval benchmark. This dataset is specifically designed to evaluate the capability of large language models in generating cloud infrastructure-as-code (IaC) programs that adhere to specific policy constraints. It includes 186 validated tasks (currently limited to AWS environments), each accompanied by a natural language description, structured constraint intent, OPA Rego v1 policy for scoring, gold-standard HCL reference output, and required Terraform and OPA version information. Task difficulty is rated on a scale from 1 (easy) to 6 (expert), covering 34 different AWS services. The scoring mechanism is deterministic, relying on the pass/fail results of `terraform plan` and `opa eval`, rather than using LLMs as judges. The dataset is provided in a flat CSV format, aiming to offer a reliable and reproducible evaluation benchmark for code generation models, particularly in the field of cloud infrastructure automation.
创建时间:
2026-05-04
搜集汇总
数据集介绍
构建方式
IaC-Eval v2 数据集是对 NeurIPS 2024 基准测试的现代化升级与扩展,聚焦于 Terraform 云基础设施即代码的自动生成评估。该数据集从原始版本中精炼出 186 个经过严格验证的 AWS 任务,摒弃了冗余条目,并统一了 Rego 策略方言至 v1 版本。构建过程中,开发者通过迁移脚本将旧版 CSV 数据重新下载并执行从 Rego v0 到 v1 的语法转换,随后重建扁平数据集文件,并利用 Terraform 1.15 与 OPA 1.16 对全部参考解决方案进行验证,确保每一项任务均能通过 terraform validate、plan 及 OPA eval 的确定性评分。
特点
该数据集的核心特色在于其完全确定性的评分机制,摒弃了传统的大语言模型评判方式,生成的 HCL 代码必须同时满足 terraform plan 与 OPA eval 的严格要求才算通过。任务难度从 1 到 6 级精心分层,覆盖 34 种 AWS 服务,提供了自然语言提示、结构化约束意图以及 Rego 策略等多维信息。此外,数据集还支持通过 OPA 输入路径灵活选择 resource_changes 或 planned_values 两种评估模式,为代码生成模型的性能刻画提供了丰富且可靠的测试工具。
使用方法
用户可通过 HuggingFace Datasets 库便捷加载 ia c-eval-v2 数据集,并利用 filter 方法按套件(AWS 或本地)或难度级别筛选任务。每个任务条目包含 prompt 字段作为大语言模型的输入,rego_policy 字段用于评分,reference_output 字段提供黄金标准 HCL。评估时,需在本地安装 Terraform 1.15 与 OPA 1.16 环境,运行脚本 scripts/validate_references.py 即可对生成的 HCL 进行自动化验证,得分从 0.0 到 1.0 分档清晰,便于量化模型表现。
背景与挑战
背景概述
IaC-Eval v2是一款面向基础设施即代码(IaC)领域的代码生成基准测试数据集,由AutoIaC项目团队于2024年在NeurIPS会议上发布的IaC-Eval v1基础上演进而来。该数据集聚焦于Terraform配置代码的自动生成能力评估,通过186个精心设计的AWS云资源管理任务,涵盖了从基础到专家级的六个难度层次,并引入Open Policy Agent(OPA)的Rego v1策略语言进行确定性评分。作为该领域的开创性基准,IaC-Eval v2为评估大语言模型(LLM)在复杂云基础设施代码生成中的表现提供了标准化的测试框架,推动了IaC代码生成技术的系统化研究。
当前挑战
IaC-Eval v2致力于解决的核心领域挑战在于,现有代码生成基准多聚焦于通用编程语言,而缺乏对基础设施即代码这一专业性极强的领域的覆盖——Terraform配置不仅需语法正确,更需满足云服务的并发约束、依赖关系及安全策略。在数据集构建过程中,团队面临的技术挑战包括:对原始v1版本中272个基于配置路径的任务进行迁移排除,确保所有186个任务均能通过Terraform验证、计划执行和OPA策略的联合测试;移除固定凭据以增强安全性;以及将Rego策略从v0方言升级至v1标准,保证评分逻辑的统一性与可复现性。此外,数据集的评估管线需依赖Terraform 1.15+与OPA 1.16+等特定工具版本,增加了环境复现的门槛。
常用场景
经典使用场景
在基础设施即代码(Infrastructure as Code)领域,IaC-Eval v2被广泛用作评估大语言模型生成Terraform HCL代码能力的标杆性基准数据集。它包含186个经过严格验证的AWS云服务任务,难度等级从1到6分布,每个任务配有自然语言描述的提示、参考输出以及用于自动化评分的一致性约束策略。研究人员常采用该数据集来评测模型在真实云资源编排场景中的代码生成准确性和合规性,其评分机制完全基于Terraform plan与OPA policy的确定性执行结果,无需依赖主观的人工评判或语言模型作为裁判,从而保障了评测的公平性与可重复性。
实际应用
在实际工程应用中,IaC-Eval v2为云平台运营团队和DevOps工具开发者提供了直接且高效的模型质检工具。企业可借助该基准定期筛选用于自动化生成基础设施代码的大语言模型,确保生成的HCL脚本通过官方的语法校验、计划推理以及策略审计,从而避免因代码缺陷导致的资源误配置或安全策略违例。此外,基于该数据集构建的评分流水线亦可被集成至持续集成/持续部署(CI/CD)流程中,为自动化基础设施交付提供一道可靠的质量门禁,显著降低人为审查负担。
衍生相关工作
IaC-Eval v2在原始IaC-Eval(NeurIPS 2024)基础上持续演进,带动了一系列衍生工作。一方面,其配套的开源验证脚本和DSPy评估套件(涵盖基线测试、微调模型评估等六个实验阶段)为后续研究者提供了可复现的实验基础设施;另一方面,该数据集启发了针对基础设施代码生成领域的对抗鲁棒性研究、跨云服务商泛化能力评估以及基于强化学习优化代码生成策略等创新方向。此外,因其严格的策略验证流程,还促使了针对OPA(开放策略代理)代码合成与迁移工具的改进工作,进一步丰富了基础设施自动化生态。
以上内容由遇见数据集搜集并总结生成


