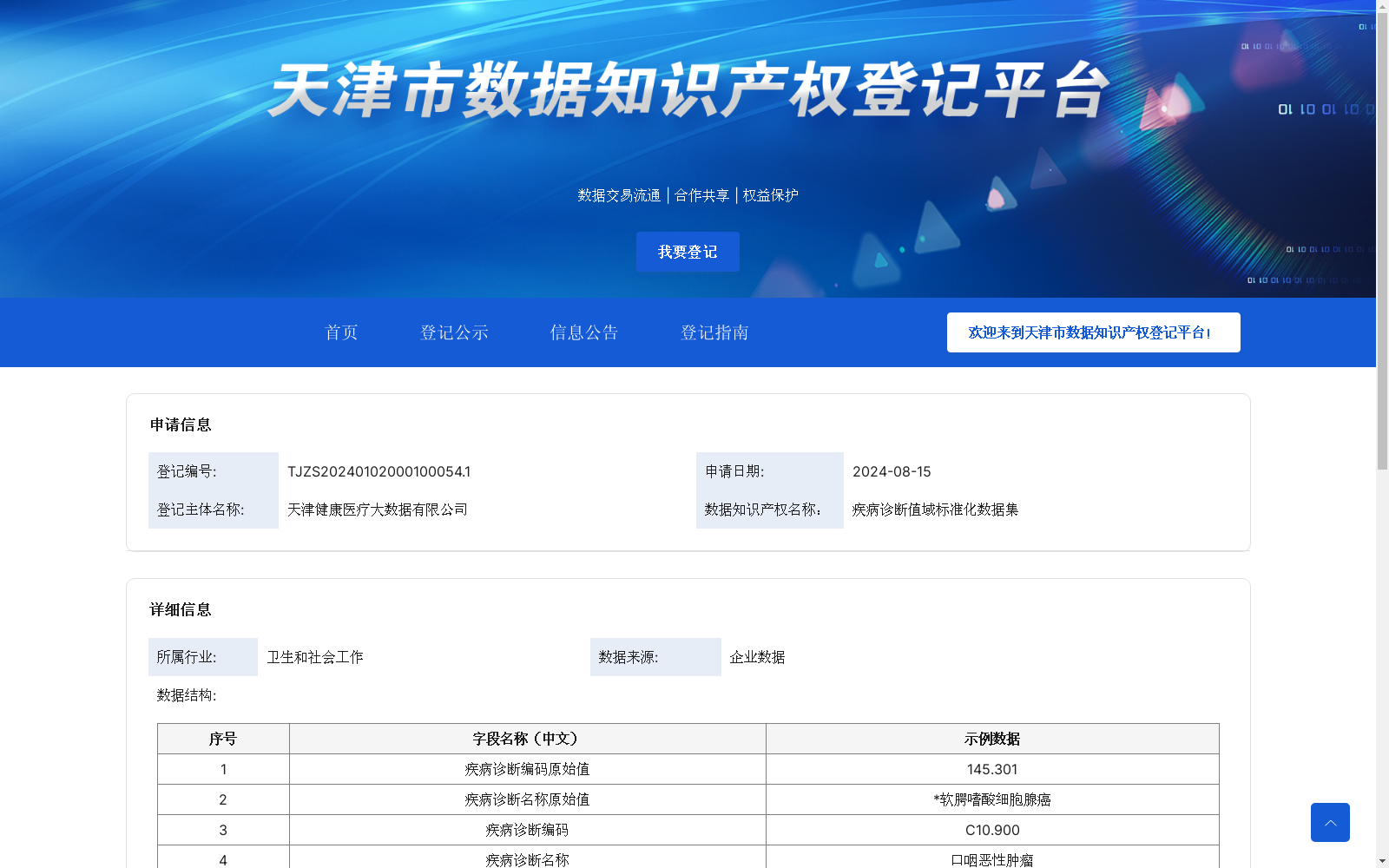
疾病诊断值域标准化数据集
收藏天津市数据知识产权登记平台2024-08-15 更新2024-08-28 收录
下载链接:
https://dengji.tjippc.cn/xxgg_nr?id=566d92ab-edf9-4ab2-b9e1-a03b2fc3a84a
下载链接
链接失效反馈官方服务:
资源简介:
首先对数据进行预处理,去掉数据中的特殊字符,进而利用Lucene程序对数据建立主索引,通过Analyzer分词算法对数据进行分词后,对照《疾病分类代码国家临床版2.0 》的标准集,查找标准数据索引,结合机器学习进行智能码值匹配,对于匹配结果相关专家进行审核,不断为机器学习积累语料,提升智能匹配契合度
First, perform data preprocessing by eliminating special characters from the dataset. Next, build a primary index for the dataset using the Lucene program. After tokenizing the data with the Lucene Analyzer, retrieve the standard data index by referencing the standard dataset of the National Clinical Version 2.0 of Disease Classification Codes. Subsequently, conduct intelligent code value matching in combination with machine learning. Relevant experts will review the matching results, continuously accumulate corpus for machine learning training, and improve the matching fitness of the intelligent matching system.
提供机构:
天津健康医疗大数据有限公司
创建时间:
2024-08-15
搜集汇总
数据集介绍
特点
该数据集为疾病诊断值域标准化数据集,包含18万条医疗数据,每周更新,用于医学术语标准化,提升数据准确性和跨平台共享能力。采用智能匹配算法并结合专家审核,适用于医疗、教学和科研领域。
以上内容由遇见数据集搜集并总结生成


