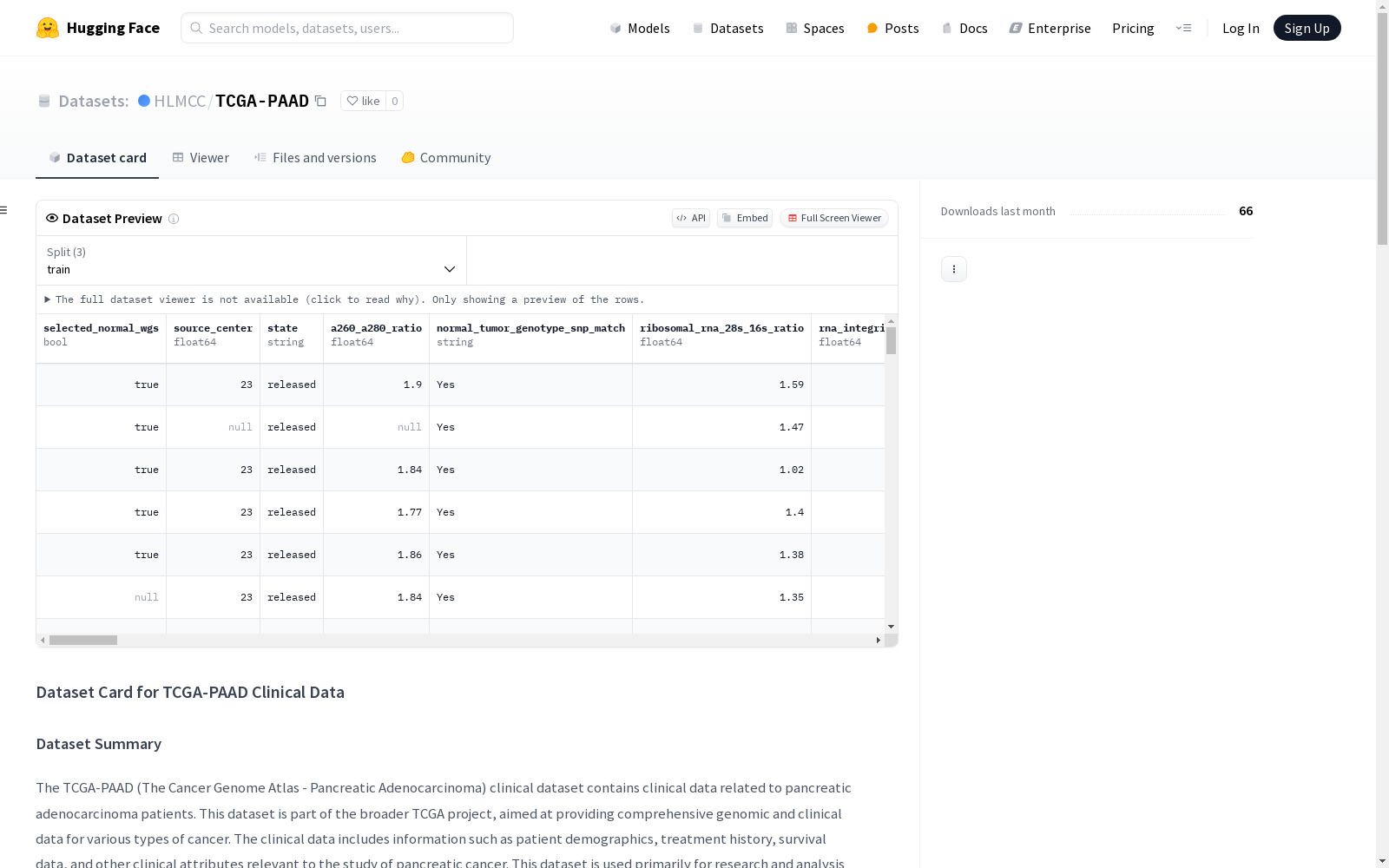
TCGA-PAAD
收藏TCGA-PAAD Clinical Data 数据集概述
数据集简介
TCGA-PAAD(The Cancer Genome Atlas - Pancreatic Adenocarcinoma)临床数据集包含与胰腺腺癌患者相关的临床数据。该数据集是TCGA项目的一部分,旨在为各种类型的癌症提供全面的基因组和临床数据。临床数据包括患者的人口统计学信息、治疗历史、生存数据以及其他与胰腺癌研究相关的临床属性。该数据集主要用于研究和分析目的,特别是用于构建机器学习模型,以基于临床属性预测生存、复发或治疗反应等结果。
目标
开发一个机器学习模型,使用临床数据预测胰腺腺癌(PAAD)患者的生存率。该模型将使用C-Index(一致性指数)进行评估,这是一种特别适合测量生存模型准确性的指标。
背景
胰腺癌具有最高的死亡率之一,基于临床数据准确预测患者生存可以帮助制定治疗计划和患者护理。数据集包含各种临床变量,如人口统计信息、治疗历史和生存时间,这些将作为模型中的预测因子。
任务详情
- 模型类型:回归
- 目标变量:患者生存时间(通常以天或月为单位)
- 评估指标:C-Index(一致性指数),用于评估生存模型的预测准确性。它评估预测生存时间与实际生存时间在患者对之间的吻合程度。
为什么选择C-Index?
C-Index通常用于生存分析,因为它反映了模型在区分患者对之间,预测谁将存活更长时间的能力。在处理临床生存数据中常见的截尾数据时,它比典型的回归指标(如均方误差MSE)具有优势。
数据集注意事项
- 数据分割:数据集随机分为训练集(70%)、验证集(15%)和测试集(15%)。训练集和验证集包含所有临床变量,而测试集的临床变量被移除,以模拟真实世界的测试场景。
- 隐私:数据集遵循隐私标准,因为它是匿名的。
- 数据不平衡:由于生存率和临床结果通常是偏斜的,因此在模型训练过程中必须考虑这一点,以避免对多数类(生存时间较短的患者)的偏见。
使用示例
python import pandas as pd
splits = { "train": "train_data.parquet", "validation": "val_data.parquet", "test": "test_data.parquet", }
train_df = pd.read_parquet("hf://datasets/HLMCC/TCGA-PAAD/" + splits["train"]) validation_df = pd.read_parquet("hf://datasets/HLMCC/TCGA-PAAD/" + splits["validation"]) test_df = pd.read_parquet("hf://datasets/HLMCC/TCGA-PAAD/" + splits["test"])
引用
本研究中使用的数据来自The Cancer Genome Atlas(TCGA)研究网络:https://www.cancer.gov/tcga。如果您在工作中使用此数据集,请引用TCGA研究网络:
bash The Cancer Genome Atlas Research Network. (2017). Comprehensive and Integrated Genomic Characterization of Pancreatic Ductal Adenocarcinoma. Cancer Cell, 32(2), 185-203.e13. https://doi.org/10.1016/j.ccell.2017.07.007
数据集管理员
该数据集由TCGA联盟整理和准备,并由Moffitt癌症中心处理,以便于机器学习应用。