Zyda-2
收藏arXiv2024-11-09 更新2024-11-13 收录
下载链接:
https://huggingface.co/datasets/Zyphra/Zyda-2
下载链接
链接失效反馈官方服务:
资源简介:
Zyda-2是由Zyphra机构创建的一个包含5万亿Tokens的高质量数据集,旨在用于语言模型的预训练。该数据集汇集了如FineWeb和DCLM等高质量的开源数据源,并通过交叉去重和模型质量过滤技术进一步提炼,以确保数据的高质量和多样性。创建过程中,数据集经历了严格的去重和质量筛选步骤,以提升模型的训练效果。Zyda-2主要应用于自然语言处理领域,旨在提升小规模高效模型的性能,特别是在消费者和边缘设备上的应用。
Zyda-2 is a high-quality dataset containing 5 trillion tokens, created by the institution Zyphra for pre-training of language models. It aggregates high-quality open-source data sources such as FineWeb and DCLM, and is further refined through cross-deduplication and model quality filtering techniques to ensure high data quality and diversity. During its development, the dataset has undergone stringent deduplication and quality filtering steps to improve model training performance. Zyda-2 is primarily applied in the field of natural language processing, aiming to enhance the performance of small-scale efficient models, especially for applications on consumer and edge devices.
提供机构:
Zyphra
创建时间:
2024-11-09
搜集汇总
数据集介绍
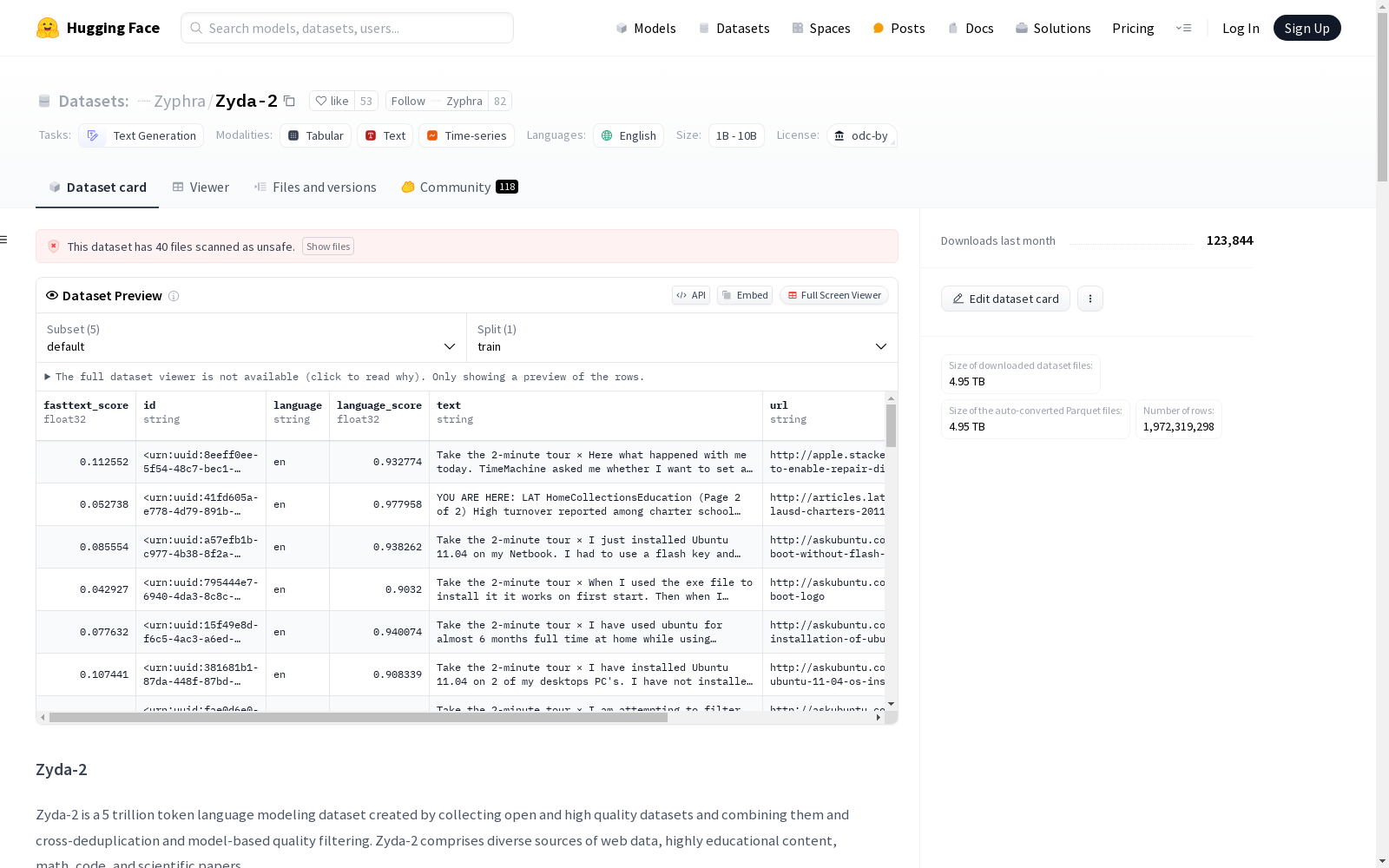
构建方式
Zyda-2数据集的构建过程融合了多种高质量的开源数据源,包括DCLM、FineWeb-Edu2、Zyda-1以及Dolma-CC。首先,通过跨数据集的去重处理,消除了各数据源中重复的文档,确保数据集的多样性和独特性。随后,应用基于模型的质量过滤方法,对Zyda-1和Dolma-CC进行进一步筛选,保留高质内容,从而提升整体数据集的质量。这一流程不仅优化了数据集的结构,还显著提高了其用于预训练语言模型的效能。
特点
Zyda-2数据集以其庞大的规模和卓越的质量著称,包含高达五万亿个标记,为语言模型的预训练提供了丰富的资源。其特点在于通过精细的去重和模型筛选,确保了数据的高纯度和有效性。此外,该数据集的开放许可政策使其广泛可用,促进了学术研究和工业应用的进一步发展。Zyda-2的构建方法和高质量标准使其成为当前最先进的语言模型训练数据集之一。
使用方法
Zyda-2数据集适用于大规模语言模型的预训练,用户可以通过HuggingFace平台获取该数据集。在使用过程中,建议结合特定的任务需求,如自然语言理解、生成等,进行数据集的子集选择和预处理。此外,考虑到数据集的高质量和大规模特性,用户在训练模型时应充分利用其多样性和丰富性,以最大化模型的性能和泛化能力。通过合理的权重分配和数据混合策略,可以进一步提升模型的表现。
背景与挑战
背景概述
Zyda-2数据集由Zyphra公司于2024年发布,旨在为语言模型预训练提供一个高质量、大规模的数据集。该数据集的核心研究问题是如何在保持数据质量的同时,扩展数据集的规模,以提升语言模型的性能。Zyda-2通过整合如FineWeb和DCLM等高质量的开源数据集,并通过交叉去重和模型基础的质量过滤,实现了这一目标。该数据集的发布不仅推动了开源语言模型的发展,也为小规模、高效能模型的训练提供了有力支持。
当前挑战
Zyda-2数据集在构建过程中面临的主要挑战包括数据去重和质量过滤。尽管去重通常被认为能提升语言模型性能,但最近的文献指出,不当的去重可能会产生负面效果。此外,模型基础的质量过滤虽然显著提升了未过滤数据集的性能,但对于已经高度过滤的数据集,如DCLM和FineWeb-Edu,其效果有限。这些挑战不仅影响了数据集的构建效率,也提出了关于数据去重和质量过滤在不同情境下效果的深入研究问题。
常用场景
经典使用场景
Zyda-2数据集在自然语言处理领域中被广泛用于语言模型的预训练。其庞大的规模和高质量的文本数据使其成为训练小型高效模型的理想选择。通过结合多种高质量的开源数据集,如FineWeb和DCLM,Zyda-2通过交叉去重和模型基础的质量过滤进一步提升了数据质量,从而在训练过程中显著提高了模型的性能。
衍生相关工作
基于Zyda-2数据集,研究者们开发了一系列高性能的语言模型,如Zamba2系列模型,这些模型在多个参数规模上均达到了最先进的性能。此外,Zyda-2的成功也激发了对数据集构建和质量提升方法的进一步研究,推动了模型基础过滤技术和数据去重方法的发展,为未来的语言模型研究提供了新的方向和思路。
数据集最近研究
最新研究方向
在自然语言处理领域,Zyda-2数据集的最新研究方向主要集中在通过大规模数据集的构建和优化来提升语言模型的性能。研究者们通过整合高质量的开源数据集,如FineWeb和DCLM,并应用跨数据集的去重和基于模型的质量过滤技术,显著提高了数据集的质量和规模。这种数据集的构建方法不仅有助于训练出更高效的语言模型,还为开源模型在与闭源模型的竞争中提供了有力支持。此外,研究还探讨了数据去重和模型过滤对模型性能的影响,提出了进一步优化数据集质量的可能性,为未来语言模型的发展提供了新的研究视角。
相关研究论文
- 1Zyda-2: a 5 Trillion Token High-Quality DatasetZyphra · 2024年
以上内容由遇见数据集搜集并总结生成


