CMACD
收藏github2024-11-13 更新2024-11-14 收录
下载链接:
https://github.com/yeaso/Chinese-Affective-Computing-Dataset
下载链接
链接失效反馈官方服务:
资源简介:
这是一个基于社交媒体用户的多标签中文情感计算数据集,整合了用户的性格特质与六种情感及微情感,每种情感都标注了强度级别。数据集旨在推进机器对复杂人类情感的识别,并为心理学、教育、市场营销、金融和政治等领域的研究提供数据支持。
This is a multi-label Chinese sentiment computing dataset based on social media users. It integrates users' personality traits alongside six categories of emotions and micro-emotions, with intensity levels annotated for each emotion category. This dataset is designed to advance machine-based recognition of complex human emotions, and provide data support for research in fields including psychology, education, marketing, finance, politics and other related areas.
创建时间:
2024-11-12
原始信息汇总
中文情感计算数据集(CMACD)
概述
- 数据集名称:中文情感计算数据集(CMACD)
- 数据来源:微博(Weibo)
- 数据类型:多标签情感计算数据集
- 数据规模:包含11,338个有效用户,566,900条帖子及其用户的MBTI人格标签
- 情感分类:包含六种情感和微情感,每种情感标注有强度等级
- 应用领域:心理学、教育、市场营销、金融、政治等
数据集特点
- 多标签分类:整合了用户的性格特质与情感,支持多标签分类
- 情感强度标注:每种情感和微情感都标注了强度等级
- 稀缺性:中文情感数据集稀缺,尤其是包含中文用户人格特质的数据集更为有限
数据集使用
- 访问方式:仅对有合法需求的研究人员免费开放,需通过电子邮件申请
- 申请邮箱:annezjy94@163.com
- 公开样本:提供了一个小样本数据集demo.csv,地址为:https://github.com/yeaso/Chinese-Affective-Computing-Dataset
引用
- 使用该数据集时,请引用相关论文(具体引用信息未提供)
搜集汇总
数据集介绍
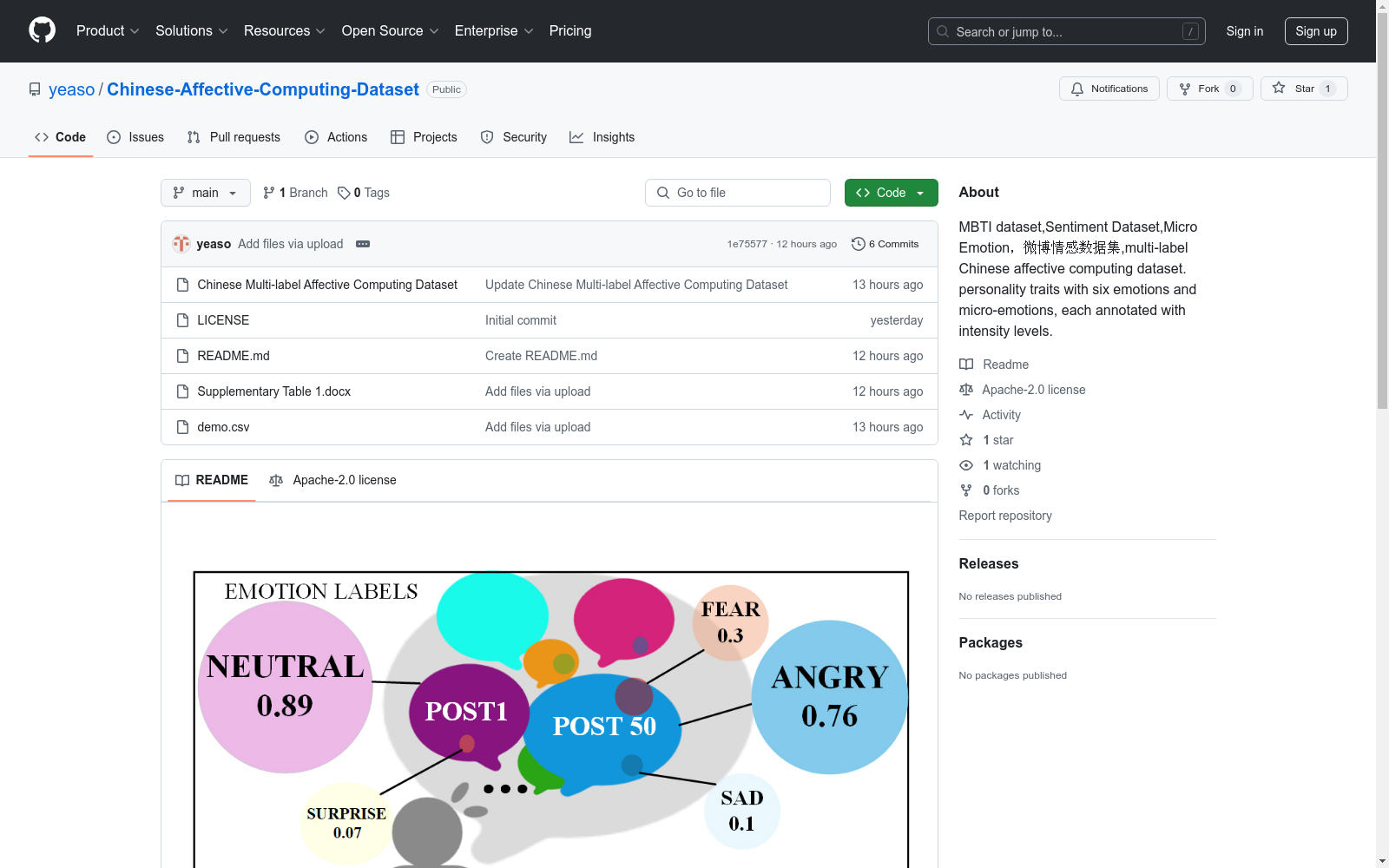
构建方式
在情感计算领域,现有的数据集往往将情感和人格特质分开标注,缺乏对微情感和情感强度的细致标注。为填补这一空白,本研究从主要社交媒体平台微博中筛选出11,338名有效用户,这些用户来自超过50,000名个体,并具有多样的MBTI人格标签。通过收集这些用户的566,900条帖子及其MBTI人格标签,采用EQN方法,构建了一个多标签的中文情感计算数据集,该数据集整合了同一用户的六种情感和微情感,并标注了情感强度。
使用方法
CMACD数据集主要面向具有合法需求的科研人员,使用者需通过电子邮件申请获取数据集。为展示数据集的特性和应用价值,并方便基础测试和反馈,研究团队已公开了一个小样本数据集demo.csv。使用者可通过访问指定链接获取该小样本数据集,并参考相关文献进行数据集的引用和使用。
背景与挑战
背景概述
情感与个性是理解人类心理状态的核心要素。现有的情感计算数据集通常将情感和个性特征分开标注,缺乏对微情感和情感强度的细粒度标注,尤其是在单一标签和多标签分类中。中文情感数据集极为稀缺,而捕捉中国用户个性特征的数据集更是有限。为填补这一空白,本研究从主要社交媒体平台微博中收集数据,筛选出11,338名有效用户,这些用户来自超过50,000名具有多样MBTI个性标签的个体,并获取了566,900条帖子及其用户的MBTI个性标签。通过EQN方法,我们构建了一个多标签中文情感计算数据集,该数据集将同一用户的个性特征与六种情感和微情感相结合,每种情感均标注有强度等级。多个NLP分类模型的验证结果显示了该数据集的强大实用性。此数据集旨在推动机器对复杂人类情感的识别,并为心理学、教育、市场营销、金融和政治等领域的研究提供数据支持。
当前挑战
尽管该数据集已采取隐私保护措施,但由于涉及人类个性和情感的研究,确保用户安全成为一大挑战。CMACD仅免费提供给有合法需求的研究人员。此外,构建过程中面临的挑战包括从海量社交媒体数据中筛选有效用户和帖子,以及对情感和个性特征进行细粒度标注。这些挑战不仅要求高度的数据处理能力,还需要精确的心理学和情感分析方法。
常用场景
经典使用场景
在情感计算领域,CMACD数据集的经典使用场景主要集中在多标签情感分类和微情感强度分析上。该数据集通过整合微博用户的MBTI人格标签与六种情感及微情感,为研究者提供了一个精细化的情感标注平台。研究者可以利用此数据集训练和验证情感分类模型,探索情感与人格之间的复杂关系,从而提升机器对人类情感状态的识别能力。
解决学术问题
CMACD数据集解决了现有情感计算数据集中情感与个性特征分离的问题,填补了中文情感数据集的空白。通过引入微情感和情感强度的多标签标注,该数据集为心理学、教育学、市场营销等多个领域的研究提供了丰富的数据支持。其精细化的标注方式有助于深入理解人类情感的复杂性,推动情感计算领域的发展。
实际应用
在实际应用中,CMACD数据集可用于开发情感分析工具,帮助企业进行市场调研和消费者行为分析。例如,在金融领域,通过分析用户的情感状态和人格特征,可以更准确地预测市场情绪和投资行为。此外,教育机构可以利用该数据集开发个性化教学系统,根据学生的情感状态和人格特征提供定制化的教育方案。
数据集最近研究
最新研究方向
在情感计算领域,CMACD数据集的最新研究方向主要集中在多标签情感分类和微情感强度分析上。该数据集通过整合微博用户的MBTI人格标签与六种情感及微情感,为研究者提供了丰富的情感和人格数据。前沿研究不仅探索了如何利用这些数据提升自然语言处理模型的情感识别能力,还涉及心理学、教育、市场营销、金融和政治等多个交叉领域的应用。这些研究旨在深化对复杂人类情感的理解,并为相关领域的决策提供数据支持。
以上内容由遇见数据集搜集并总结生成


