tinyLLM-ee628
收藏Hugging Face2026-05-11 更新2026-05-15 收录
下载链接:
https://huggingface.co/datasets/unnatLNCO/tinyLLM-ee628
下载链接
链接失效反馈官方服务:
资源简介:
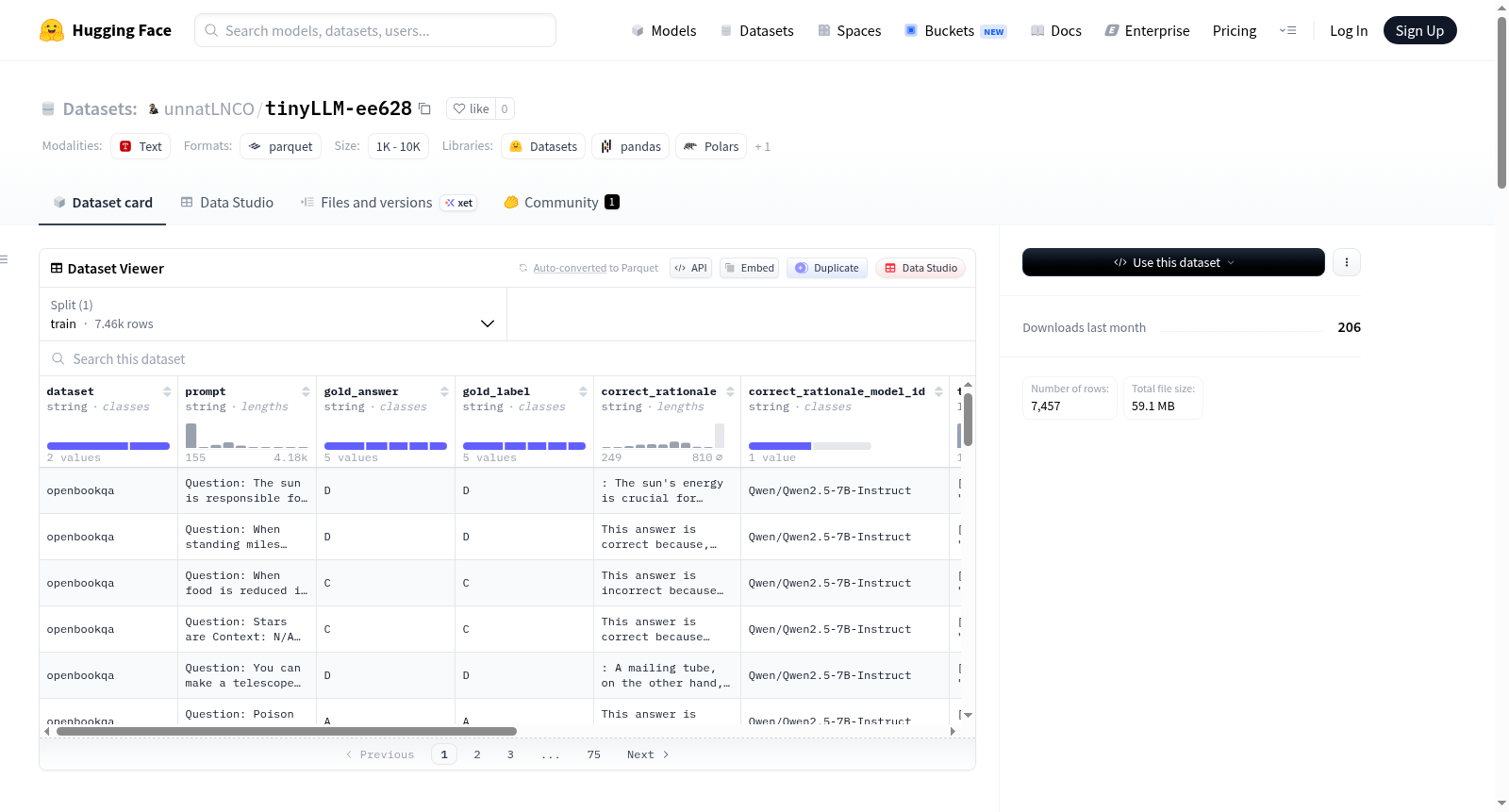
该数据集是一个用于模型推理评估或训练的数据集,包含1000个训练样本。每个样本由多个字段构成:dataset(标识来源数据集)、prompt(输入提示)、gold_answer(标准答案)、gold_label(标准标签)、correct_rationale(正确的推理过程)和correct_rationale_model_id(生成正确推理的模型标识)。此外,每个样本还包含一个teacher_outputs列表,记录了多个不同模型对同一提示的生成结果,包括模型标识(model_id)、生成的答案(answer)、平均对数概率(avg_logprob)、答案是否正确(correct)、生成的推理过程(rationale)、答案长度(answer_len)、推理长度(rationale_len)和生成延迟(latency_ms)。该数据集适用于研究模型推理能力、答案生成质量、多模型比较等任务,支持对模型输出进行细粒度的性能分析。
This dataset is designed for model inference evaluation or training, containing 1000 training samples. Each sample consists of multiple fields: dataset (identifying the source dataset), prompt (input prompt), gold_answer (standard answer), gold_label (standard label), correct_rationale (correct reasoning process), and correct_rationale_model_id (model identifier that generated the correct reasoning). Additionally, each sample includes a teacher_outputs list, which records the generation results of multiple different models for the same prompt, including model identifier (model_id), generated answer (answer), average log probability (avg_logprob), correctness of the answer (correct), generated rationale (rationale), answer length (answer_len), rationale length (rationale_len), and generation latency (latency_ms). The dataset is suitable for tasks such as studying model reasoning capabilities, answer generation quality, and multi-model comparison, supporting fine-grained performance analysis of model outputs.
创建时间:
2026-05-04
搜集汇总
数据集介绍
构建方式
tinyLLM-ee628数据集旨在为知识蒸馏任务提供离线教师模型输出数据。其构建过程基于PubmedQA与OpenbookQA两个问答数据集,从中分别选取2.5k条无标签数据与1k条有标签数据,以及5k条有标签数据,作为原始输入。随后,利用三款教师模型——包括meta-llama/Llama-3.1-8B-Instruct、mistralai/Mistral-7B-Instruct-v0.3等——对上述样本进行推理,生成答案、推理链、对数概率、正确性判断、响应长度及延迟等多项指标。所有教师模型的输出被结构化存储,形成包含prompt、gold_answer、gold_label及多模型输出字段的完整数据集,最终以Parquet格式固化,共计7500条训练样本。
使用方法
使用tinyLLM-ee628数据集时,研究人员可直接加载Parquet文件进行训练或评估。该数据主要应用于知识蒸馏场景,学生模型可利用教师输出的答案、推理链及概率分布作为软标签,通过最小化与教师输出之间的KL散度或交叉熵损失来学习。具体而言,可选取'teacher_outputs'字段中的某个模型输出作为监督信号,也可融合多个教师的结果进行集成蒸馏。同时,'correct_rationale'字段提供了正确推理链,可用于训练模型生成合理且准确的解释。数据集按标准格式组织,易于集成至HuggingFace Datasets库,支持快速迭代实验。
背景与挑战
背景概述
tinyLLM-ee628数据集是一个为知识蒸馏任务精心构建的离线数据集,诞生于大型语言模型(LLMs)蓬勃发展、亟需轻量化高效模型的背景下。该数据集由来自多个教师模型(包括meta-llama/Llama-3.1-8B-Instruct、mistralai/Mistral-7B-Instruct-v0.3等)在PubmedQA和OpenbookQA两个权威问答数据集上的推理输出构成,总计7500条训练样本。其核心研究问题在于如何通过知识蒸馏技术,将庞大教师模型在专业领域(如生物医学、常识推理)的问答能力迁移至更轻量的学生模型,从而在保持性能的同时显著降低计算开销与推理延迟。该数据集的开源为小模型高效适配复杂知识体系提供了宝贵的训练资源,有望推动边缘计算与实时问答等场景下部署友好型语言模型的发展。
当前挑战
tinyLLM-ee628数据集所面临的挑战主要涵盖两个层面。在领域问题层面,其关键在于解决大型语言模型在资源受限环境中难以部署的瓶颈,即如何实现知识蒸馏过程中教师模型复杂推理模式(如逐步推理、多步逻辑链)的精准传递,同时避免学生模型产生语义退化或知识遗忘。在构建过程中,数据集面临多重困难:首先,需要确保来自不同教师模型(结构、参数量各异)的输出在格式与质量上保持一致性,这涉及对多源回答进行标准化处理与合理性校验;其次,离线生成数据需有效模拟教师模型的真实推理分布,包括处理正确与错误回答的平衡分布,以及衡量输出延迟、对数概率等多维度指标,从而为学生模型的训练提供稳健的标签噪声与难度梯度。此外,跨数据集(PubmedQA与OpenbookQA)的异构性要求数据整合时兼顾领域特异性与通用性,进一步增加了构建复杂度。
常用场景
经典使用场景
在知识密集型自然语言处理任务中,模型蒸馏技术已成为轻量化部署的关键路径。tinyLLM-EE628数据集专为小语言模型的蒸馏学习而设计,其经典使用场景在于利用多个大语言模型作为教师,在PubmedQA和OpenbookQA两个知识问答基准上生成高质量的标注数据与推理链,从而指导学生模型的训练。研究者可基于该数据集构建多教师蒸馏框架,通过融合不同规模教师模型(如Llama-3.1-8B-Instruct、Mistral-7B-Instruct等)的输出分布与逻辑链,令学生模型在保持推理准确性的同时显著压缩参数量,实现计算资源受限场景下的高效知识迁移。
解决学术问题
该数据集着力攻克小模型在复杂问答任务中知识匮乏与推理能力不足的双重困境。通过系统性收集多教师模型在医学与常识领域的显式推理过程,它有效缓解了传统蒸馏中教师知识单一化与逻辑链缺失的问题,为研究模型压缩与知识保留间的权衡提供了标准化评估基准。其意义在于验证了多视角教师信号对学生模型泛化能力的提升作用,揭示了推理路径蒸馏相较于答案蒸馏的优越性,为低资源场景下构建高保真度的小型语言模型奠定了数据基础,推动了高效自然语言理解系统在垂直领域内的落地进程。
实际应用
在医疗问诊辅助、教育知识问答等需快速响应的场景中,tinyLLM-EE628驱动的轻量化模型可部署于移动端或边缘设备。例如,面向临床医生的PubmedQA知识检索系统,借助蒸馏后的小模型能在秒级内完成医学文献的答案生成与依据溯源,既保障了回答的专业性,又降低了对云端算力的依赖。在开放教育领域,基于OpenbookQA训练的紧凑型模型能够嵌入智能学习终端,为学生提供即时、准确的常识解答与推理解释,显著提升人机交互的流畅度与可及性。
数据集最近研究
最新研究方向
在知识密集型问答与模型轻量化交叉的前沿领域,tinyLLM-ee628数据集为探索**小模型的知识蒸馏**与**推理链迁移**提供了关键资源。该数据集汇聚了Llama-3.1-8B、Mistral-7B等大模型在PubMedQA和OpenbookQA上的输出,包含答案、正确性标记及推理链,旨在训练小模型模仿教师模型的行为。当前研究热点聚焦于如何利用此类教师输出数据,通过**理性蒸馏(rationale distillation)** 与小样本学习策略,显著提升小模型在专业问答上的准确性与可解释性,同时降低推理时延。这一方向直接回应了业界对大模型部署昂贵、推理缓慢的痛点,推动医学、教育等垂直领域实现低成本的轻量化智能应用。
以上内容由遇见数据集搜集并总结生成


