kene_multimodal_gift
收藏Hugging Face2025-10-24 更新2025-10-25 收录
下载链接:
https://huggingface.co/datasets/nativemind/kene_multimodal_gift
下载链接
链接失效反馈官方服务:
资源简介:
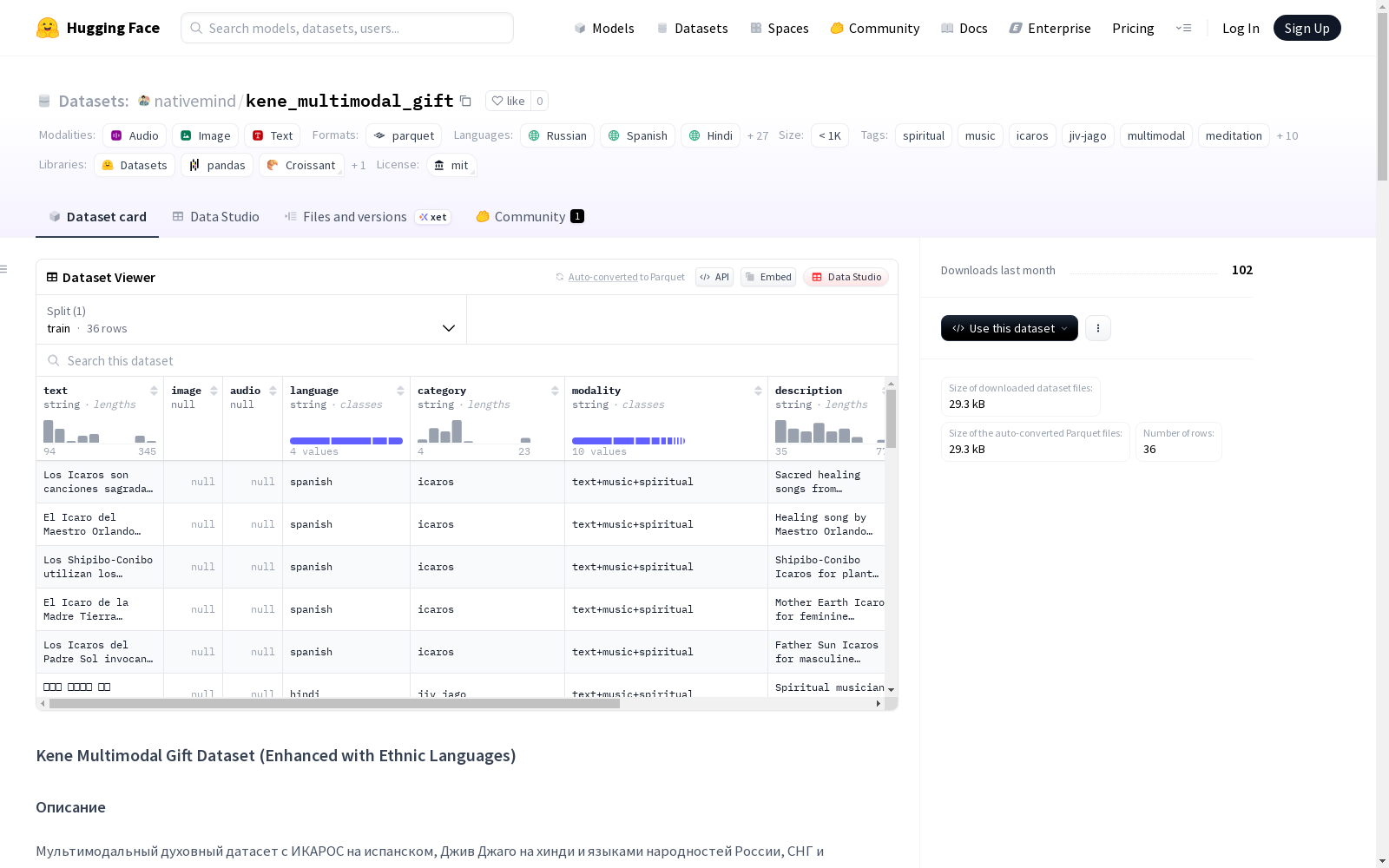
Kene多模态礼物数据集(带有民族语言增强)是一个包含多种语言和类别的多模态精神数据集,包括西班牙语和印地语的icaros和jiv-jago,以及俄罗斯、中亚和乌克兰的民族语言。数据集涵盖精神文本、音乐、咒语、冥想、瑜伽等多种类别,适用于精神学习、语言学习、文化保存、多语言AI训练和语言学研究的场景。
创建时间:
2025-10-20
原始信息汇总
Kene Multimodal Gift Dataset 数据集概述
基本信息
- 许可证: MIT License
- 数据规模: 小于1K样本
- 训练集样本数: 36个
- 最新版本: 3.0
- 更新日期: 2025-01-24
语言覆盖
主要语言
- 俄语 (ru)
- 西班牙语 (es)
- 印地语 (hi)
俄罗斯民族语言
- 鞑靼语 (tt)
- 巴什基尔语 (ba)
- 楚瓦什语 (cv)
- 车臣语 (ce)
- 雅库特语 (sah)
- 布里亚特语 (bua)
- 奥塞梯语 (os)
- 莫克沙语 (mdf)
- 乌德穆尔特语 (udm)
- 马里语 (chm)
独联体国家语言
- 乌克兰语 (uk)
- 白俄罗斯语 (be)
- 哈萨克语 (kk)
- 乌兹别克语 (uz)
- 吉尔吉斯语 (ky)
- 塔吉克语 (tg)
- 阿塞拜疆语 (az)
- 亚美尼亚语 (hy)
- 格鲁吉亚语 (ka)
- 摩尔多瓦语 (mo)
- 土库曼语 (tk)
乌克兰民族语言
- 克里米亚鞑靼语 (crh)
- 匈牙利语 (hu)
- 罗马尼亚语 (ro)
- 波兰语 (pl)
- 保加利亚语 (bg)
- 加告兹语 (gag)
数据类别
- 伊卡洛斯 (Icaros): 亚马逊原住民神圣治疗歌曲
- 吉夫·贾戈 (Jiv Jago): 毗湿奴派灵性音乐
- 咒语 (Mantras): 神圣声音和祈祷
- 冥想 (Meditation): 正念实践
- 瑜伽 (Yoga): 灵性实践
- 俄罗斯民族语言 (ethnic_russia)
- 独联体民族语言 (ethnic_cis)
- 乌克兰民族语言 (ethnic_ukraine)
数据结构
特征字段
text: 文本内容 (字符串)image: 图像数据 (空值)audio: 音频数据 (空值)language: 语言代码 (字符串)category: 数据类别 (字符串)modality: 模态类型 (字符串)description: 英文描述 (字符串)source: 数据来源 (字符串)metadata: 元数据结构体
元数据字段
包含应用领域、方法、艺术家、文化背景、国家、民族、语言家族、文字系统、传统、目的、风格、地区等详细信息。
应用领域
- 灵性学习和冥想
- 民族语言学习
- 文化保护
- 多语言人工智能训练
- 语言学研究
- 多语言系统开发
数据获取
python from datasets import load_dataset dataset = load_dataset("nativemind/kene_multimodal_gift")
搜集汇总
数据集介绍
构建方式
在跨文化语言资源稀缺的背景下,该数据集通过系统整合多元文化素材构建而成。其采集范围涵盖俄罗斯、独联体国家及乌克兰地区的民族语言,同时收录西班牙语伊卡洛斯圣歌、印地语吉夫贾戈灵性音乐等传统仪式内容。数据组织采用结构化元数据框架,为每条记录标注语言归属、文化传统、地域特征等维度信息,形成兼具语言多样性与文化深度的多模态资源。
特点
该数据集最显著的特征在于其语言生态的丰富性,囊括了从印欧语系到乌拉尔语系的三十余种民族语言。内容维度上兼具灵性文本与民俗文化资料,既包含亚马逊部落的疗愈圣歌,也收录了欧亚大陆少数民族的仪式诵唱。其元数据体系设计精良,通过传统、目的、地域等字段立体呈现文化语境,为语言技术研究与文化保护提供多维视角。
使用方法
研究者可通过标准数据接口加载该资源,利用语言代码和分类标签实现精准筛选。针对特定研究需求,可分别提取俄罗斯少数民族语言、独联体国家语料或乌克兰地区方言进行对比分析。在灵性计算领域,支持按伊卡洛斯圣歌、吉夫贾戈音乐等文化传统类型构建训练集,为跨语言文化理解任务提供结构化数据支撑。
背景与挑战
背景概述
在数字人文与计算语言学蓬勃发展的背景下,Kene Multimodal Gift数据集由NativeMind团队于2025年创建,旨在系统整合多元文化中的精神实践与语言资源。该数据集聚焦于跨模态的灵性表达,核心研究问题涉及如何通过多模态数据架构保存濒危语言中的文化遗产,特别是俄罗斯、独联体及乌克兰地区少数民族语言与南美伊卡洛斯圣歌、印度吉夫贾戈音乐等传统元素的融合。其对文化多样性保护与多语言人工智能模型的开发具有深远影响,推动了灵性计算与数字人类学的交叉研究。
当前挑战
该数据集致力于解决多模态灵性数据融合的复杂性问题,面临领域内语义鸿沟与跨文化表征的挑战,例如如何准确解析不同语言中精神概念的细微差异。构建过程中,数据采集遭遇了少数民族语言资源稀缺与标准化缺失的困境,同时多模态对齐需克服音频、文本与元数据间的异构性整合难题,确保文化语境与语言学特征的完整保留。
常用场景
经典使用场景
在跨模态人工智能研究中,该数据集为探索精神文化内容的多语言表达提供了独特资源。其经典应用场景集中于训练多模态模型处理西班牙语伊卡洛斯圣歌、印地语吉夫·贾戈灵性音乐以及俄罗斯、独联体和乌克兰少数民族语言的文本数据,通过整合文本与音频模态,支持模型理解不同文化背景下的精神实践表达方式。
衍生相关工作
基于该数据集衍生的经典研究包括跨模态语言表示学习框架EthnoBERT,该模型在少数民族语言理解任务中取得突破性进展。同时催生了文化遗产计算学的新分支——数字萨满教研究,以及多语言语音合成系统MantraSynth,这些工作显著推进了计算社会科学与保护语言多样性的交叉研究。
数据集最近研究
最新研究方向
在跨模态灵性数据分析领域,kene_multimodal_gift数据集凭借其涵盖俄罗斯、独联体及乌克兰地区少数民族语言的独特结构,正推动多语言文化保护与人工智能融合的前沿探索。当前研究聚焦于利用该数据集构建跨语言灵性内容生成模型,通过整合伊卡洛斯圣歌、吉夫·贾戈音乐等灵性传统与少数民族文本数据,开发能够理解并生成多模态文化表达的人工智能系统。这一方向不仅助力濒危语言的数字化保存,还为多模态机器学习在文化遗产领域的应用提供了重要实验平台,相关成果正逐步应用于跨文化灵性实践辅助与多语言教育技术开发。
以上内容由遇见数据集搜集并总结生成


