VANE-Bench
收藏数据集概述
数据集信息
-
特征(Features):
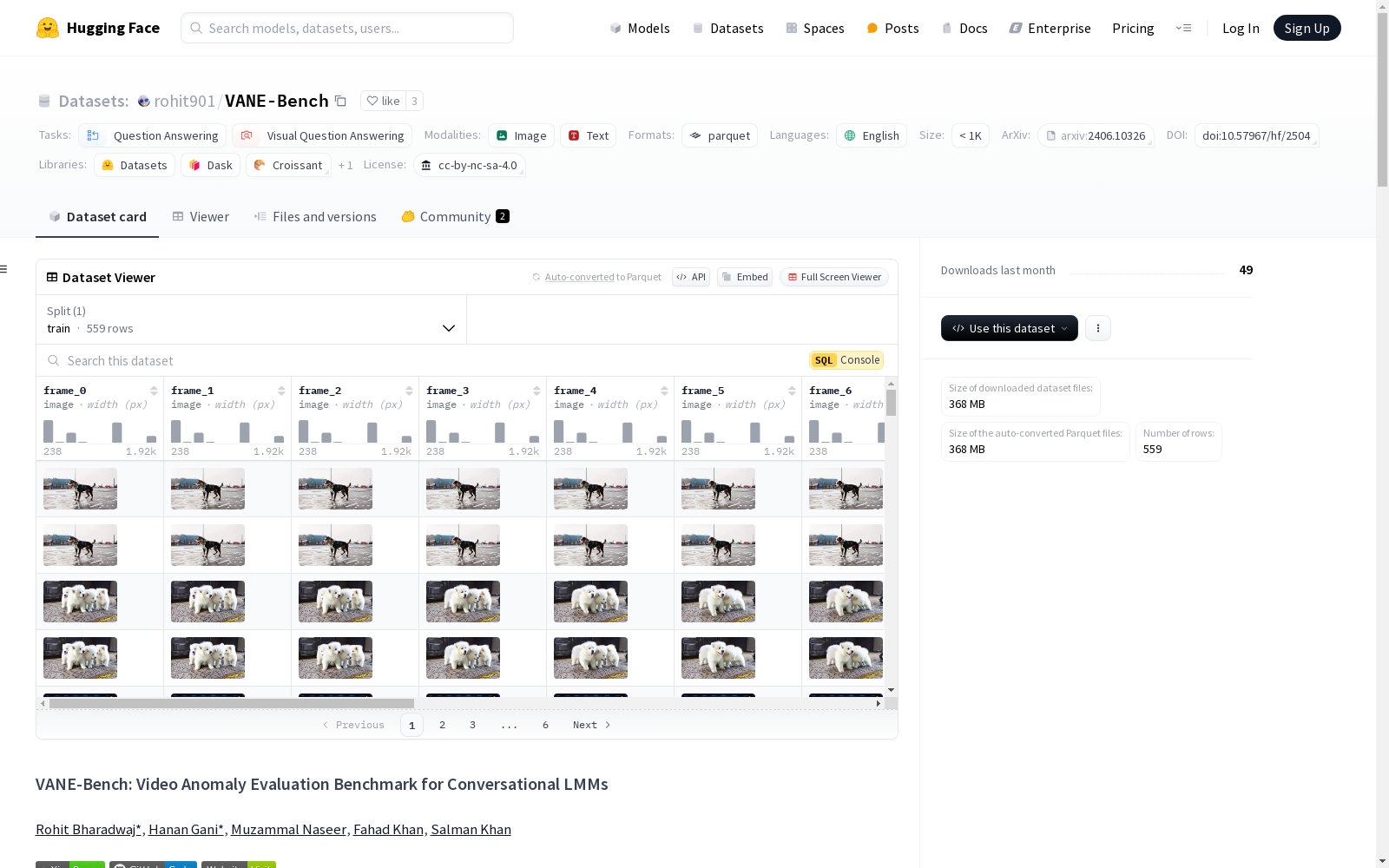
frame_0至frame_9: 图像数据类型(image)category: 字符串类型(string),视频主类别(AI-Generated, Real-World)sub_category: 字符串类型(string),特定异常数据类别(如 SORA, UCFCrime, Avenue 等)video_folder: 字符串类型(string),包含视频帧的文件夹question: 字符串类型(string),与视频异常相关的问题answer: 字符串类型(string),问题的对应答案
-
数据分割(Splits):
train: 训练集,包含 559 个样本,数据大小为 746196621 字节
-
下载大小(Download Size): 367938984 字节
-
数据集大小(Dataset Size): 746196621 字节
-
配置(Configs):
default: 数据文件路径为data/train-*
-
任务类别(Task Categories):
- 问答(question-answering)
- 视觉问答(visual-question-answering)
-
语言(Language): 英语(en)
-
数据集名称(Pretty Name): VANE-Bench
-
大小类别(Size Categories): n<1K
数据集详情
-
类别(Categories):
- AI-Generated
- Real-World
-
子类别(Sub-Categories):
- Avenue, UCFCrime, UCSD-Ped1, UCSD-Ped2, ModelScopeT2V, SORA, OpenSORA, Runway Gen2, VideoLCM
-
AI-Generated 异常类别(AI-Generated Anomaly Categories):
- 不自然的变换(unnatural transformations)
- 不自然的外观(unnatural appearance)
- 穿透(pass-through)
- 消失(disappearance)
- 突然出现(sudden appearance)
-
Real-World 异常类别(Real World Anomaly Categories):
- 逮捕(Arrest)
- 攻击(Assault)
- 盗窃(Stealing)
- 投掷(Throwing)等
-
数据(Data):
- 每个视频片段包含帧级数据和详细的问答对,以挑战对话式大型多模态模型(LMMs)在理解和响应视频异常方面的能力。
使用数据集
-
HuggingFace: python from datasets import load_dataset dataset = load_dataset("rohit901/VANE-Bench")
-
Zip 文件:
-
下载链接: VQA_Data.zip
-
文件结构:
VQA_Data/ |–– Real World/ | |–– UCFCrime | | |–– Arrest002 | | |–– Arrest002_qa.txt | | |–– ... # remaining video-qa pairs | |–– UCSD-Ped1 | | |–– Test_004 | | |–– Test_004_qa.txt | | |–– ... # remaining video-qa pairs ... # remaining real-world anomaly dataset folders |–– AI-Generated/ | |–– SORA | | |–– video_1_subset_2 | | |–– video_1_subset_2_qa.txt | | |–– ... # remaining video-qa pairs | |–– opensora | | |–– 1 | | |–– 1_qa.txt | | |–– ... # remaining video-qa pairs ... # remaining AI-generated anomaly dataset folders
-