RIMO
收藏arXiv2025-09-09 更新2025-09-11 收录
下载链接:
https://github.com/RIMOBenchmark/RIMO, https://huggingface.co/spaces/RIMOBenchmark/RIMO
下载链接
链接失效反馈官方服务:
资源简介:
RIMO数据集是由香港科技大学(广州)信息枢纽人工智能推力研究团队创建的,旨在为高级数学推理提供一个易于评估、难以解决的问题。该数据集分为两个部分:RIMO-N包含335个问题,每个问题都有一个唯一的整数答案,便于确定性检查;RIMO-P包含456个证明问题,每个问题都被分解成一系列子问题,以便评估模型的逐步推理过程。RIMO数据集可以帮助研究人员更好地理解和评估大型语言模型在数学推理方面的能力。
The RIMO dataset was developed by the Artificial Intelligence Thrust Research Team at the Information Hub of The Hong Kong University of Science and Technology (Guangzhou), with the goal of providing a set of challenging yet easily evaluable problems for advanced mathematical reasoning. The dataset is split into two components: RIMO-N includes 335 problems, each with a unique integer answer to facilitate deterministic verification; RIMO-P contains 456 proof problems, each of which is decomposed into a series of sub-problems to enable evaluation of a model's step-by-step reasoning process. The RIMO dataset can assist researchers in better understanding and assessing the mathematical reasoning capabilities of large language models.
提供机构:
香港科技大学(广州)信息枢纽人工智能推力
创建时间:
2025-09-09
搜集汇总
数据集介绍
构建方式
RIMO数据集通过精心重构1959年至2023年间的国际数学奥林匹克竞赛试题构建而成,其构建过程采用双轨制设计。RIMO-N轨道将335道原题改写为具有唯一整数答案的形式,通过多源交叉验证(包括官方短名单解答、AoPS社区解析和视频讲解)确保答案的确定性;RIMO-P轨道则保留456道证明题的原貌,并依据专家验证的参考解法将其分解为逐步推理的子问题序列,形成结构化评估框架。
特点
该数据集最显著的特征在于其评估的精确性与难度层级的平衡。RIMO-N通过整数答案格式实现确定性字符串匹配评估,彻底消除了基于模型评判的噪声;RIMO-P则通过子问题分解机制实现对逐步推理能力的细粒度测量。数据集严格遵循国际数学奥林匹克的学科分布,涵盖代数、几何、数论和组合数学四大领域,且所有问题均保持原竞赛的最高难度水平,为评估高级数学推理能力提供了高分辨率基准。
使用方法
使用该数据集时,RIMO-N轨道可直接通过字符串匹配进行答案正确性验证,无需依赖符号等价性计算或外部评判模型。RIMO-P轨道需采用序列化评估协议,使用经过训练的自动评分系统(如deepseek-r1)对每个子问题的解答进行逐步评判,最终性能得分通过计算所有问题连续正确子解决方案的平均比例得出。评估过程需在零温度设置下进行贪婪解码,以确保结果的可复现性和可比性。
背景与挑战
背景概述
RIMO(Remade International Mathematical Olympiad)基准由香港科技大学(广州)的陈子烨、秦成伟和舒瑶等研究人员于2025年提出,旨在解决现有数学奥林匹克基准在评估高级数学推理时存在的噪声和偏差问题。该数据集重构了1959年至2023年的国际数学奥林匹克(IMO)问题,形成两个独立轨道:RIMO-N包含335个唯一整数答案的问题,支持确定性字符串匹配评分;RIMO-P包含456个证明问题,通过分解为子问题逐步评估推理过程。RIMO显著推动了大型语言模型在数学推理领域的评估前沿,揭示了当前模型与真实奥林匹克水平之间的能力差距。
当前挑战
RIMO解决的领域挑战在于高级数学推理的精确评估,现有基准如GSM8K和MATH因模型性能饱和而无法有效区分顶尖能力,且异构答案格式依赖基于模型的评判引入噪声。构建过程中的挑战包括:确保问题重构后逻辑核心和难度不变,同时产出唯一整数答案;对证明问题进行可靠分解,需跨多个权威来源(如官方解答、AoPS Wiki)验证真值一致性;以及设计自动化评分系统以消除人工评判的主观性,保证评估的鲁棒性和可重现性。
常用场景
经典使用场景
在数学推理研究领域,RIMO数据集被广泛用于评估大型语言模型在高级数学问题解决中的极限性能。其经典使用场景包括对模型进行零样本或少样本测试,通过RIMO-N轨道的唯一整数答案设计,研究者能够精确量化模型在奥林匹克数学问题上的准确率,而无需依赖噪声较大的基于模型的评分系统。
衍生相关工作
RIMO数据集催生了一系列相关研究,包括针对证明生成能力的细化评估框架和形式化验证方法。例如,基于RIMO-P轨道的子问题分解结构,研究者开发了步进式推理评估协议,进一步推动了如LEAN等形式化证明语言在机器验证中的应用,为数学推理的自动化奠定了坚实基础。
数据集最近研究
最新研究方向
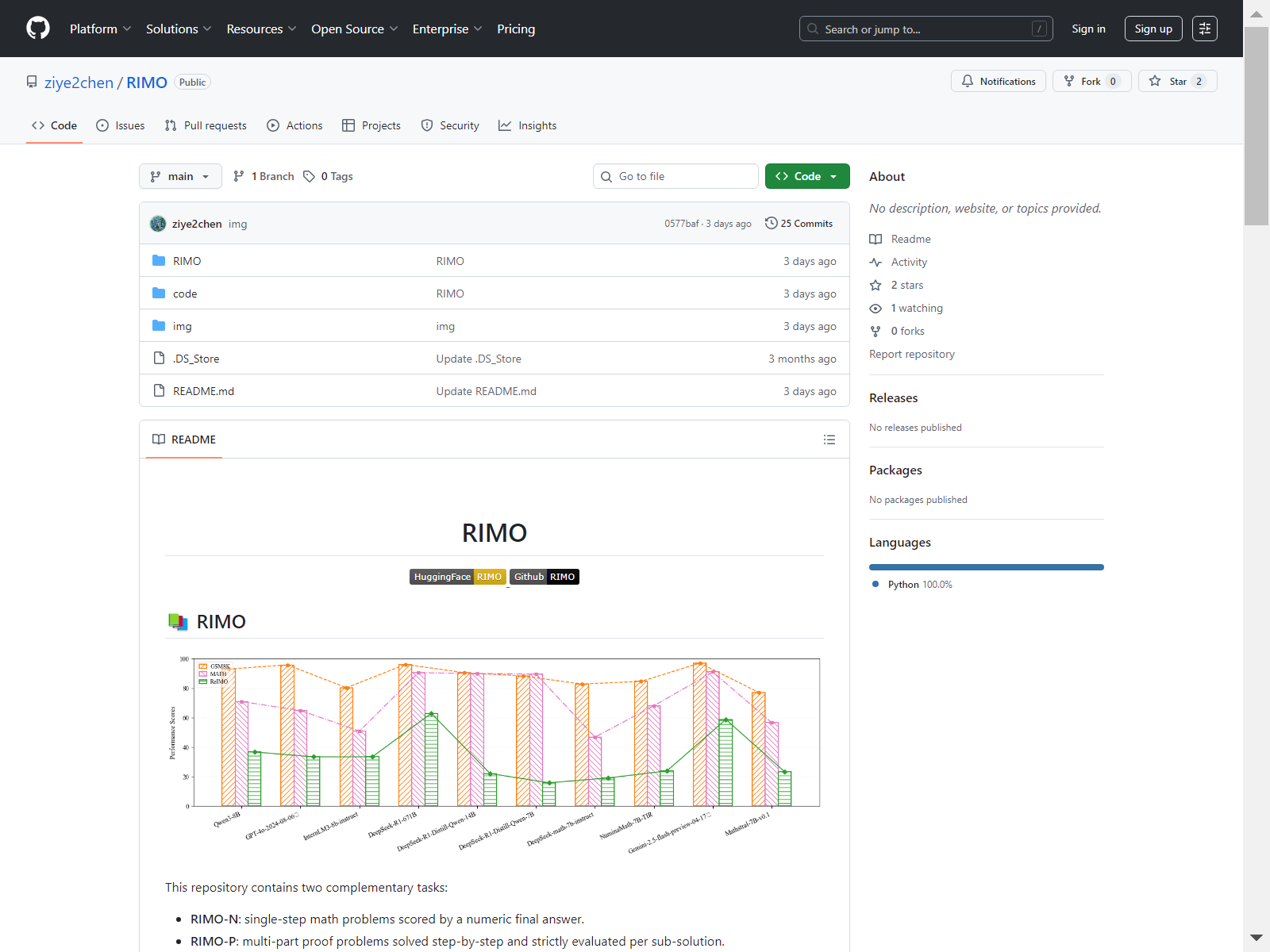
随着大语言模型在传统数学基准测试如GSM8K和MATH上接近性能饱和,研究焦点转向国际数学奥林匹克(IMO)级别的高难度推理评估。RIMO基准通过双轨设计解决了现有奥林匹亚级评测中的评估噪声问题:RIMO-N将335道IMO问题重构为唯一整数答案格式,支持确定性字符串匹配评分;RIMO-P包含456道证明题,通过专家验证的解构式子问题序列评估逐步推理能力。当前前沿模型如GPT-4o和Gemini 2.5 Flash在RIMO上表现显著下滑,暴露了与真实奥林匹亚级推理间的能力鸿沟。该数据集已成为推动数学推理AI发展的核心工具,尤其促进了针对证明生成、符号推理和结构化问题分解的新方法研究,为克服当前模型的演绎能力局限提供了高分辨率评测标准。
相关研究论文
- 1RIMO: An Easy-to-Evaluate, Hard-to-Solve Olympiad Benchmark for Advanced Mathematical Reasoning香港科技大学(广州)信息枢纽人工智能推力 · 2025年
以上内容由遇见数据集搜集并总结生成


