taxonomy_species
收藏Hugging Face2025-07-25 更新2025-07-26 收录
下载链接:
https://huggingface.co/datasets/GleghornLab/taxonomy_species
下载链接
链接失效反馈官方服务:
资源简介:
这是一个包含生物序列和物种信息的数据集。数据集中的序列长度介于20到2048之间。经过去重和筛选,每个物种至少有100个样本。数据集分为训练集、验证集和测试集,分别包含147523、5000和5000个样本。
This is a dataset comprising biological sequences and corresponding species information. The lengths of the sequences range from 20 to 2048. After deduplication and filtering, each species has at least 100 samples. The dataset is divided into training, validation and test sets, which contain 147523, 5000 and 5000 samples respectively.
提供机构:
Gleghorn Lab
创建时间:
2025-07-25
原始信息汇总
数据集概述
基本信息
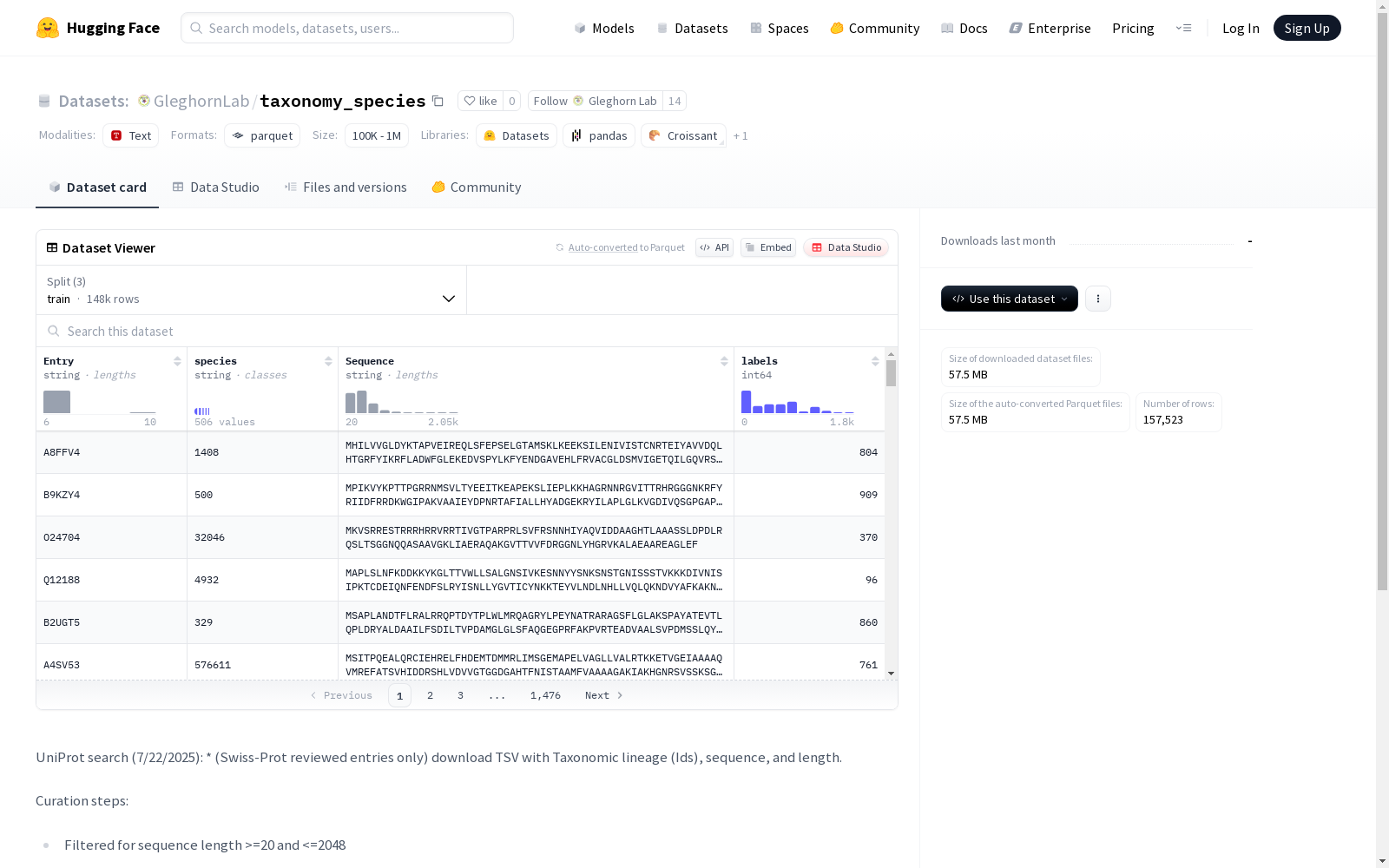
- 数据集名称: GleghornLab/taxonomy_species
- 下载大小: 57,511,782 字节
- 数据集大小: 59,062,523 字节
- 数据格式: TSV (制表符分隔值)
数据特征
- Entry: 字符串类型,表示条目信息
- species: 字符串类型,表示物种信息
- Sequence: 字符串类型,表示序列信息
- labels: int64类型,表示基于物种的标签
数据划分
- 训练集 (train): 147,523 个样本,55,325,670 字节
- 验证集 (valid): 5,000 个样本,1,882,045 字节
- 测试集 (test): 5,000 个样本,1,854,808 字节
数据来源与处理
- 数据来源: UniProt搜索 (Swiss-Prot reviewed entries only)
- 筛选条件: 序列长度在20到2048之间
- 处理步骤:
- 从taxonomic_lineage_ids列提取分类ID(域、界、门、纲、目、科、属、种)
- 保留entry、species和sequence信息
- 删除N/A值
- 使用CD-HIT在80%相似度阈值和n=5下进行去重
- 保留代表性序列
- 基于物种创建标签
- 删除样本数少于100的物种/样本
- 分层划分:先获取测试集(5,000),然后是验证集(5,000),其余为训练集
搜集汇总
数据集介绍
构建方式
在生物信息学领域,taxonomy_species数据集的构建体现了严谨的序列筛选与分类学标注流程。该数据集源自UniProt数据库的Swiss-Prot精选条目,通过TSV格式下载包含分类谱系标识、蛋白质序列及长度的原始数据。构建过程中采用多重质量控制:筛选20至2048个氨基酸长度的序列,从taxonomic_lineage_ids字段解析七级分类学标识,运用CD-HIT工具在80%相似度阈值下进行序列去冗余并保留代表序列,最终基于物种标签建立分类体系并剔除样本量不足100的稀有物种,采用分层抽样策略划分训练集(147,523条)、验证集与测试集(各5,000条)。
使用方法
作为蛋白质分类研究的基准数据集,taxonomy_species支持监督学习框架下的多类别分类任务。研究者可直接加载预分割的训练-验证-测试集,利用Entry字段追踪UniProt原始信息,Sequence字段进行特征提取或嵌入表示,labels字段作为分类目标。数据集的层级化物种标签允许开展从粗粒度(如门纲目)到细粒度(种属级别)的多层次分类实验。在使用CD-HIT去冗余代表序列时需注意,相似度阈值设定可能导致近缘物种序列被合并,建议结合具体研究问题评估序列相似性参数的影响。
背景与挑战
背景概述
taxonomy_species数据集是生物信息学领域的一项重要资源,专注于物种分类与蛋白质序列的关联研究。该数据集由研究人员基于UniProt数据库中的Swiss-Prot条目构建,通过严格的筛选和标准化流程,整合了物种分类学信息与蛋白质序列数据。其核心研究问题在于探索物种进化关系与蛋白质功能多样性之间的内在联系,为生物分类学、进化生物学以及蛋白质功能预测提供了可靠的数据支持。该数据集的构建体现了多学科交叉的研究特点,其标准化处理流程和高覆盖率特性使其成为相关领域的重要基准数据集。
当前挑战
taxonomy_species数据集面临的主要挑战体现在两个方面:领域问题的复杂性以及数据构建的技术难度。在领域层面,物种分类的层级结构和蛋白质序列的高维度特性使得特征提取与模式识别变得极具挑战性。数据构建过程中,需要克服序列长度差异大、物种分布不均衡等技术难题,通过CD-HIT算法进行序列去冗余时,相似度阈值的设定直接影响数据集的代表性和多样性。此外,保持物种分类体系的完整性和序列数据的生物学意义,同时满足机器学习模型对数据规模和质量的要求,构成了该数据集构建过程中的核心挑战。
常用场景
经典使用场景
在生物信息学领域,taxonomy_species数据集为物种分类研究提供了高质量的序列数据。研究者通过该数据集中的蛋白质序列和物种标签,能够训练深度学习模型进行自动物种分类。其经典应用场景包括构建基于序列相似性的分类器,探索不同分类层级(如门、纲、目)间的进化关系,以及验证新型分类算法的有效性。
解决学术问题
该数据集有效解决了物种分类研究中样本不平衡和数据噪声的问题。通过严格的过滤和去重流程,确保了数据的代表性和质量。其分层抽样策略为小样本物种分类提供了可靠基准,而标准化的序列长度范围则消除了长度偏差对模型性能的影响,为跨物种比较研究奠定了坚实基础。
实际应用
在实际应用中,该数据集支持了生物多样性监测和病原体快速鉴定系统的开发。环境保护机构利用其构建的模型可快速识别环境样本中的微生物组成,医疗领域则应用于病原体蛋白质的快速分类。数据集的标准格式设计使其能无缝对接主流生物信息学分析流程,显著提升了相关应用的开发效率。
数据集最近研究
最新研究方向
随着生物信息学领域的快速发展,taxonomy_species数据集在物种分类和序列分析研究中展现出重要价值。该数据集整合了UniProt Swiss-Prot数据库中的精选条目,通过严格的筛选和去重流程,确保了数据的高质量和代表性。当前研究热点聚焦于利用深度学习模型对蛋白质序列进行物种分类预测,探索序列特征与物种进化关系之间的深层关联。在生物医学领域,该数据集为病原体快速鉴定和药物靶点发现提供了重要支持。同时,研究者们正尝试将transformer架构应用于序列分析,以期突破传统比对方法的性能瓶颈。
以上内容由遇见数据集搜集并总结生成


