Snehadev/smolified-eli10-ai-assistant
收藏Hugging Face2026-03-28 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/Snehadev/smolified-eli10-ai-assistant
下载链接
链接失效反馈官方服务:
资源简介:
---
license: apache-2.0
task_categories:
- text-generation
language:
- en
tags:
- smolify
- synthetic
- distillation
pretty_name: Smolify Distilled Corpus
size_categories:
- 1K<n<10K
---
# 🤏 smolified-eli10-ai-assistant
> **Intelligence, Distilled.**
This is a synthetic training corpus generated by the **Smolify Foundry**.
It was used to train the corresponding model [`Snehadev/smolified-eli10-ai-assistant`](https://huggingface.co/Snehadev/smolified-eli10-ai-assistant).
## 📦 Asset Details
- **Origin:** Smolify Foundry (Job ID: `91ccdda8`)
- **Records:** 10000
- **Type:** Synthetic Instruction Tuning Data
## ⚖️ License & Ownership
This dataset is a sovereign asset owned by **Snehadev**.
Generated via [Smolify.ai](https://smolify.ai).
[<img src="https://smolify.ai/smolify.gif" width="100"/>](https://smolify.ai)
license: apache-2.0
task_categories:
- 文本生成
language:
- 英语
tags:
- smolify
- 合成
- 蒸馏
pretty_name: Smolify蒸馏语料库
size_categories:
- 1K<n<10K
---
# 🤏 smolified-eli10-ai-assistant
> **智能,经蒸馏提纯。**
本数据集为由**Smolify Foundry**生成的合成训练语料库,曾用于训练对应模型 [`Snehadev/smolified-eli10-ai-assistant`](https://huggingface.co/Snehadev/smolified-eli10-ai-assistant)。
## 📦 资产详情
- **数据来源**: Smolify Foundry(任务编号: `91ccdda8`)
- **样本条数**: 10000
- **数据类型**: 合成指令微调数据
## ⚖️ 许可证与所有权
本数据集为**Snehadev**所有的专属资产,通过 [Smolify.ai](https://smolify.ai) 生成。
[<img src="https://smolify.ai/smolify.gif" width="100"/>](https://smolify.ai)
提供机构:
Snehadev
搜集汇总
数据集介绍
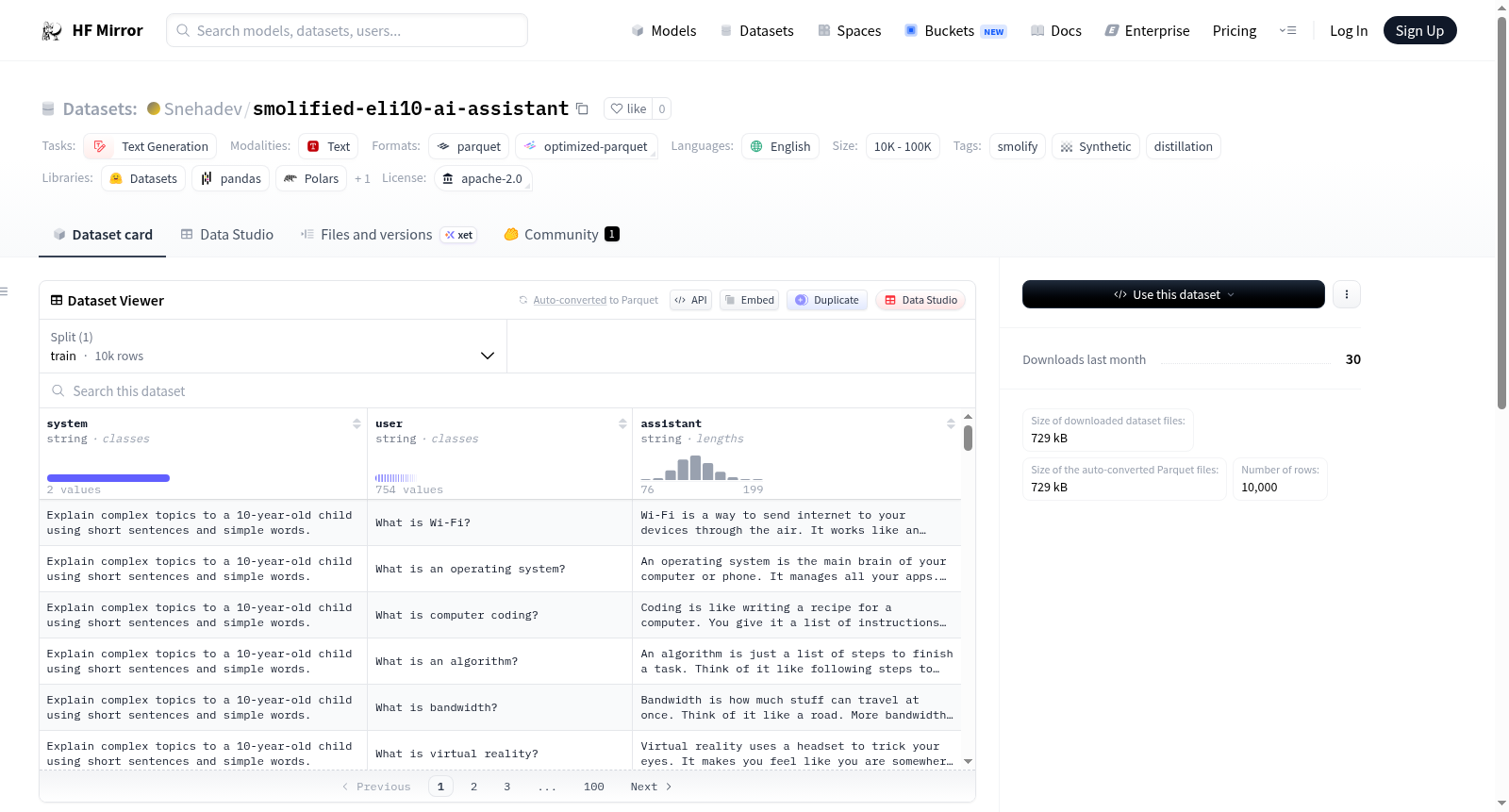
构建方式
在人工智能领域,高质量的训练数据对于模型性能至关重要。smolified-eli10-ai-assistant数据集由Smolify Foundry通过合成生成技术构建,具体采用知识蒸馏方法,从更大型或更复杂的模型中提取并精炼出结构化指令调优数据。该过程基于特定任务标识(Job ID: 91ccdda8)执行,生成了包含10000条记录的语料库,专注于文本生成任务,旨在为轻量级AI助手模型提供高效训练基础。
特点
该数据集作为合成指令调优数据,其核心特点在于高度精炼和专业化。它专为英语环境设计,标签涵盖smolify和distillation等关键词,强调智能的蒸馏与浓缩。数据规模介于1K到10K之间,属于中等体量,适合快速迭代与实验。所有权明确归属于Snehadev,采用Apache 2.0许可,确保了使用的合法性与灵活性,同时通过合成生成避免了真实数据可能涉及的隐私与版权问题。
使用方法
smolified-eli10-ai-assistant数据集主要用于训练对应的AI助手模型,例如Snehadev/smolified-eli10-ai-assistant。研究人员和开发者可通过HuggingFace平台直接访问该数据集,将其应用于文本生成任务的指令调优中。典型使用场景包括模型微调与评估,用户需遵循Apache 2.0许可条款,合理引用数据来源,并可结合Smolify.ai工具进行进一步的数据处理或扩展,以优化模型性能与效率。
背景与挑战
背景概述
在人工智能领域,特别是大型语言模型(LLM)的优化过程中,指令微调数据集扮演着至关重要的角色。smolified-eli10-ai-assistant数据集由Smolify Foundry于近期创建,主要研究人员或机构为Snehadev,其核心研究问题聚焦于通过合成数据蒸馏技术,高效生成用于模型指令微调的高质量语料。该数据集旨在支持文本生成任务,通过提炼智能,为相关模型如Snehadev/smolified-eli10-ai-assistant提供训练基础,从而推动轻量化、高效能AI助手的发展,对自然语言处理领域的模型优化与部署产生积极影响。
当前挑战
该数据集所解决的领域问题在于文本生成中的指令微调,挑战包括确保合成数据的多样性与真实性,以避免模型过拟合或产生偏差输出。构建过程中,面临的挑战涉及生成大规模、高质量的合成记录,需平衡数据规模与语义一致性,同时克服合成数据可能存在的噪声问题,以及确保数据所有权与许可合规性,这要求先进的数据蒸馏技术与严格的流程控制。
常用场景
经典使用场景
在自然语言处理领域,指令微调数据集是提升模型遵循人类意图能力的关键资源。smolified-eli10-ai-assistant作为一个合成的指令调优数据集,其最经典的使用场景是用于训练轻量级、高效的对话式人工智能助手模型。研究者通过该数据集对基础语言模型进行监督微调,旨在优化模型在理解和执行多样化用户指令方面的性能,例如回答复杂问题、生成连贯文本或完成特定任务,从而推动模型在有限参数规模下实现更精准的交互行为。
解决学术问题
该数据集主要致力于解决大语言模型在指令跟随与任务泛化方面的核心学术挑战。通过提供高质量、结构化的合成指令-响应对,它帮助缓解了真实世界标注数据稀缺且成本高昂的问题,为模型蒸馏与效率优化研究提供了标准化基准。其意义在于,它使得研究者能够系统性地探索如何在保持或提升模型能力的同时,显著压缩模型规模与计算开销,这直接影响着人工智能部署的可行性与普及性,对推动高效、可访问的AI技术发展具有重要影响。
衍生相关工作
围绕该数据集及其代表的模型蒸馏范式,已衍生出一系列经典的后续研究工作。这些工作主要集中在探索更高效的合成数据生成方法、改进指令微调的算法,以及评估小规模模型在复杂推理和对话任务上的极限性能。例如,相关研究可能深入分析不同数据合成策略对最终模型泛化能力的影响,或者开发新的评估框架以更精确地衡量小型助手模型与大型基座模型之间的能力差距。这些探索共同构成了当前高效机器学习领域一个活跃且富有成果的研究方向。
以上内容由遇见数据集搜集并总结生成


