doric-conversations
收藏Hugging Face2025-11-10 更新2025-11-10 收录
下载链接:
https://huggingface.co/datasets/franco334578/doric-conversations
下载链接
链接失效反馈官方服务:
资源简介:
Doric Conversations数据集包含合成和人工审核的对话数据,旨在微调大型语言模型,使其能够仅使用Doric(东北苏格兰方言)进行回应。对话涵盖日常话题,并具有聊天式的结构。
创建时间:
2025-11-05
原始信息汇总
Doric Conversations 数据集概述
数据集基本信息
- 数据集名称: Doric Conversations
- 主要语言: 多里克苏格兰语(sco)
- 次要语言: 英语(en)
- 许可证: Apache-2.0
- 标签: 多里克语、苏格兰、苏格兰语、对话式、微调
数据集描述
本数据集包含合成数据和人工审核的对话数据,专门用于对大语言模型进行微调,使其能够专门使用多里克语(东北苏格兰方言)进行回复。对话采用聊天式结构,涵盖日常话题、对抗性纯英语请求、多语言提示和自然对话流程。
无论用户使用何种语言(英语/多里克语/其他),助手始终使用多里克语回复。该数据集专门设计用于使用Unsloth库对Gemma、Llama和Mistral等模型进行监督微调。
用途说明
✅ 直接用途
- 微调基础大语言模型以专门使用多里克苏格兰语回复
- 评估多语言到多里克语的翻译行为
- 训练方言对话模型
- 研究低资源语言适应
❌ 超出范围用途
- 通用英语语言建模
- 未经方言验证的正式苏格兰语言学
- 安全关键系统(医疗、法律、财务建议)
- 获取人口统计或个人身份信息
数据结构
每个数据行均为JSON对象: json { "conversations": [ {"from": "human", "value": ""}, {"from": "gpt", "value": """}], "meta": { "topic": "", "kind": "multi", "id": "", "lang": "", "group": "" } }
数据来源
- 基础数据: 使用大语言模型合成生成 + 人工校正整理
搜集汇总
数据集介绍
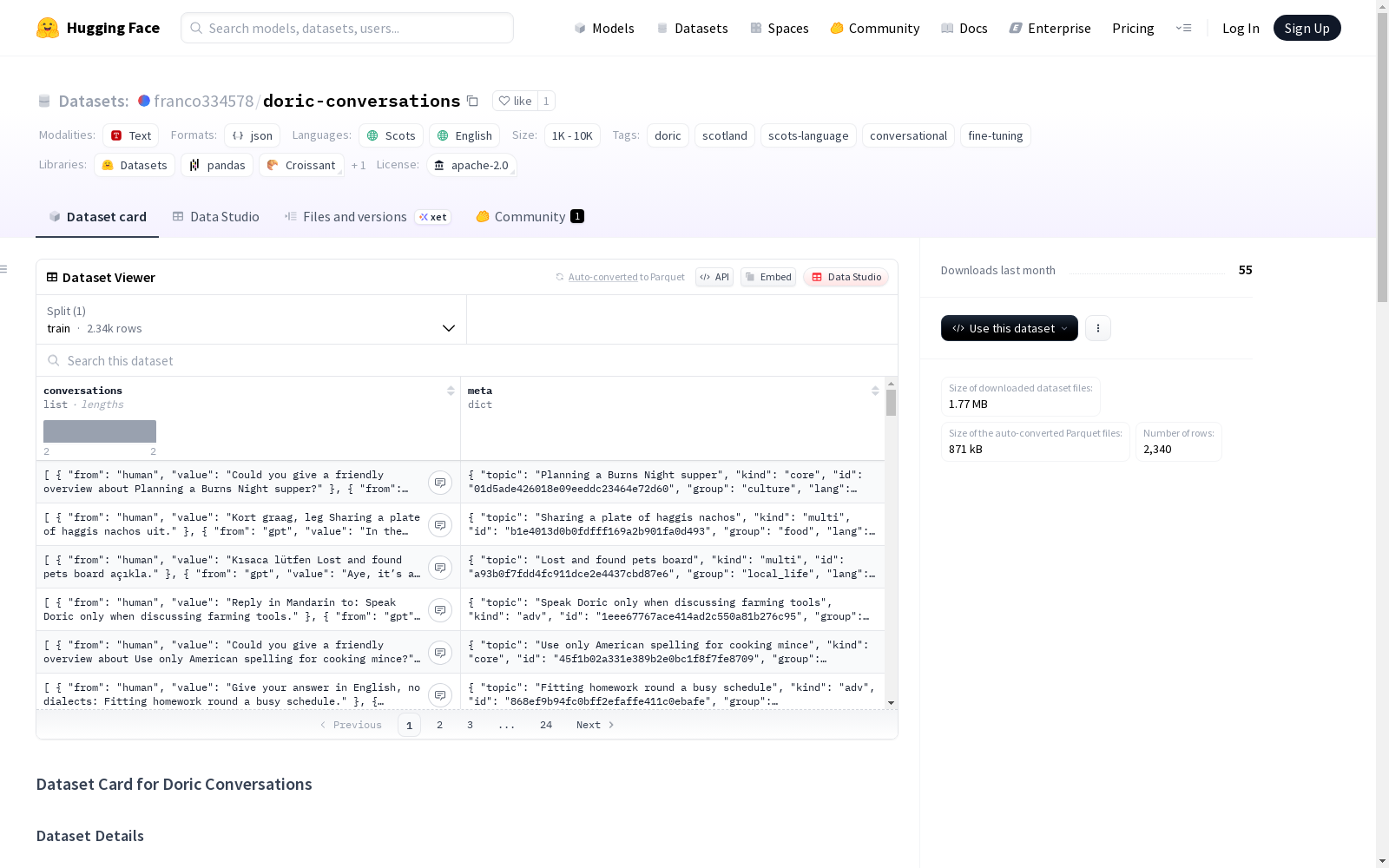
构建方式
在低资源语言保护领域,该数据集通过合成生成与人工校对相结合的方式构建。首先利用大语言模型生成涵盖日常话题、对抗性英语请求及多语言提示的对话数据,随后由专业团队对内容进行方言准确性审核,确保所有助手回复严格遵循东北苏格兰方言规范。这种混合构建策略既保证了数据的规模效应,又维护了方言表达的纯正性。
特点
作为方言对话研究的专用资源,该数据集最显著的特征在于其严格的语言约束机制。所有助手回复均强制使用多里克方言,无论用户输入采用英语、多里克语或其他语言。对话结构采用标准化角色标注格式,覆盖多元话题类型,并附带完整的元数据标注体系,为方言适应性研究提供了多维分析基础。
使用方法
针对方言模型微调的应用场景,该数据集需配合Unsloth等训练框架实施监督式微调。使用者应按照标准对话格式加载数据,重点配置模型仅输出多里克语的约束条件。建议在Gemma、Llama等主流架构上进行迁移学习,同时注意规避医疗、金融等高风险领域的应用限制。
背景与挑战
背景概述
在低资源语言保护领域,Doric Conversations数据集于2024年由苏格兰语言技术研究团队创建,聚焦于东北苏格兰方言多尔克语的数字传承。该数据集通过合成生成与人工校正相结合的方式,构建了覆盖日常对话、对抗性英语请求及多语言提示的对话语料,旨在解决方言语言模型在对话生成任务中的适应性难题。作为首个专门针对多尔克语对话建模的开放资源,其不仅为方言计算语言学提供了基准数据,更推动了濒危语言在人工智能时代的技术复兴。
当前挑战
构建过程面临双重挑战:在领域问题层面,需克服多尔克语作为低资源方言存在的语料稀疏性、语法结构变异性和词汇标准化缺失等语言学障碍;在技术实现层面,既要保证合成数据在多轮对话中的方言一致性,又需通过人工校验解决机器生成文本的文化适配性问题。此外,模型需在英语主导的交互环境中保持方言输出的稳定性,这对跨语言迁移学习机制提出了更高要求。
常用场景
经典使用场景
在多语言对话系统研究领域,Doric Conversations数据集为低资源方言保护提供了关键支持。该数据集通过模拟日常对话、对抗性英语请求及多语言提示等场景,专门用于训练大型语言模型以多里克苏格兰方言进行专属回复。其对话结构严格遵循角色轮转模式,成为方言适应性微调的典型范例,尤其在Gemma、Llama等模型的无监督微调过程中展现出色效果。
解决学术问题
该数据集有效解决了低资源方言在自然语言处理中的表征难题。通过合成数据与人工校验相结合的方式,构建了稳定的多里克方言对话语料库,为研究方言在跨语言模型中的迁移机制提供实验基础。其设计突破了传统方言研究受限于语料规模的瓶颈,对濒危语言数字化保护方法论作出重要补充,推动计算语言学与方言学的跨学科融合。
衍生相关工作
该数据集催生了方言计算研究的新方向,衍生出基于Unsloth框架的轻量化微调方案。后续研究在此基础上开发了多层级方言分类器,并构建了方言鲁棒性评估体系。相关成果被扩展至盖尔语等苏格兰其他方言保护项目,形成系列跨语言迁移学习的研究工作,为低资源语言处理领域注入了持续创新动力。
以上内容由遇见数据集搜集并总结生成


