MultiHair Dataset
收藏arXiv2025-02-10 更新2025-02-12 收录
下载链接:
https://sites.google.com/view/tangled1
下载链接
链接失效反馈官方服务:
资源简介:
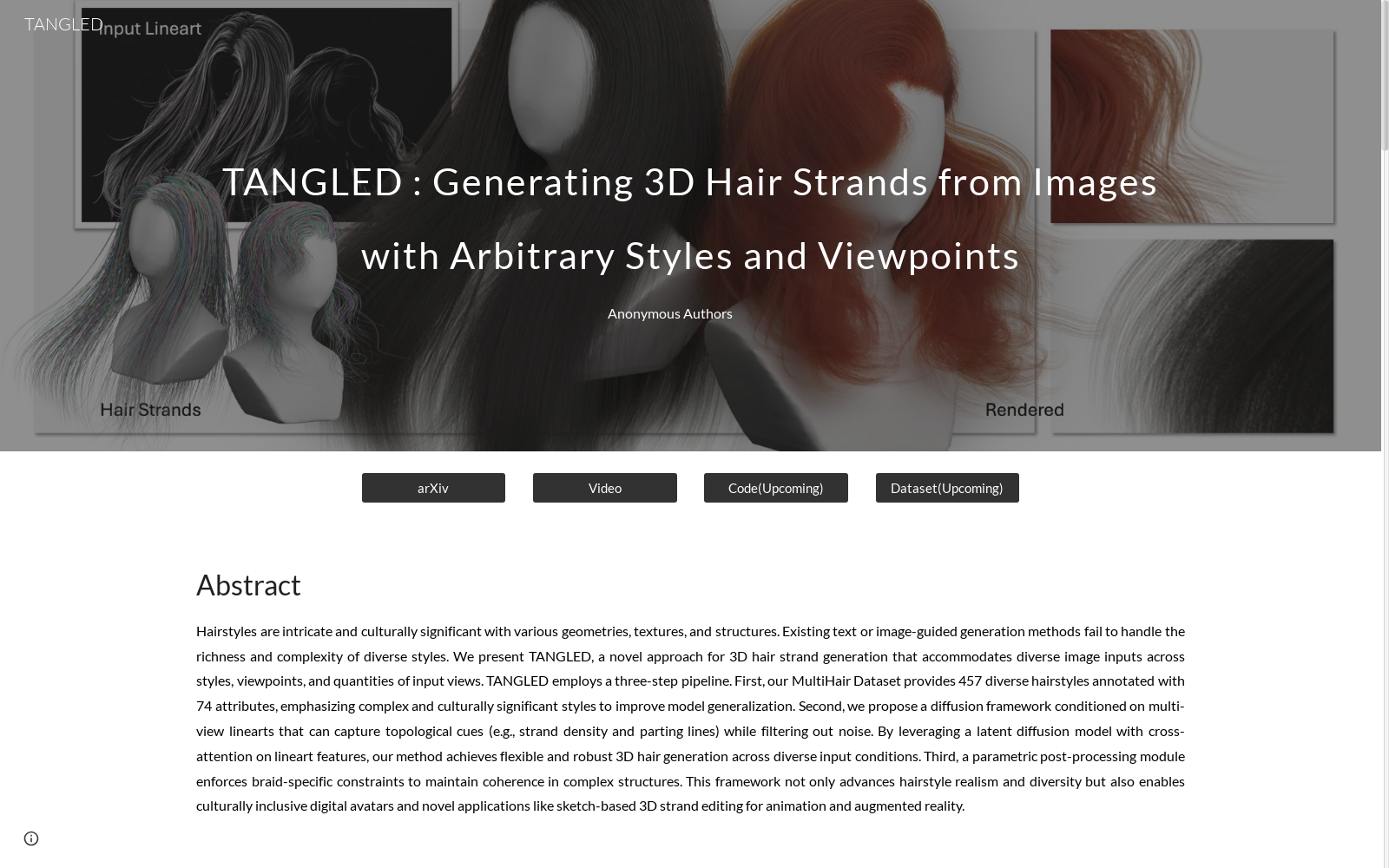
MultiHair Dataset是由上海科技大学和华中科技大学合作创建的一个包含457种不同发型的多模态3D发型数据集,涵盖74个全球和局部头发属性。数据集特别关注代表性不足的纹理(如卷曲、玉米须)和复杂发型,比之前的发型数据集的多样性提高了30%。该数据集通过多角度图像注释来丰富发型样式,并利用GPT-4生成详细的文本注释,为发型建模提供了丰富的训练数据。
The MultiHair Dataset is a multimodal 3D hairstyle dataset developed through the collaboration between ShanghaiTech University and Huazhong University of Science and Technology. It contains 457 distinct hairstyles and covers 74 global and local hair attributes. This dataset specifically focuses on underrepresented hair textures such as curly hair and cornrows, as well as complex hairstyles, with its diversity increased by 30% compared to previous hairstyle datasets. It enriches hairstyle styles via multi-angle image annotations, and leverages GPT-4 to generate detailed textual annotations, providing rich training data for hairstyle modeling.
提供机构:
上海科技大学, 华中科技大学
创建时间:
2025-02-10
搜集汇总
数据集介绍
构建方式
MultiHair Dataset是由上海科技大学、Deemos Technology和华中科技大学的研究人员共同构建的,旨在为3D头发生成模型提供丰富的训练数据。该数据集包含457种多样的发型,并针对74种属性进行了标注,涵盖了复杂且具有文化意义的风格。数据收集过程中,研究人员从各种在线平台获取了发型样本,并邀请专业艺术家对数据进行精细处理。为了确保数据的质量和多样性,数据集优先考虑了在现有数据集中代表性不足的发型,如辫子和发髻等。此外,数据集还包含了多视角图像和文本标注,以便更好地捕捉发型的结构和细节。
使用方法
MultiHair Dataset可以用于训练3D头发生成模型。在训练过程中,模型可以利用数据集中的多视角图像和文本标注来学习发型的结构和特征,从而提高模型对发型的理解和生成能力。此外,数据集中的多视角图像还可以帮助模型学习发型的空间结构和拓扑关系,从而生成更加逼真和自然的发型。除了训练模型,MultiHair Dataset还可以用于发型分析和研究。研究人员可以利用数据集中的标注信息来分析不同发型之间的相似性和差异性,从而更好地理解发型的特征和规律。此外,数据集中的多视角图像还可以帮助研究人员研究发型的空间结构和拓扑关系,从而揭示发型的生成和变化机制。
背景与挑战
背景概述
发型作为一种文化符号,承载着个人身份、社会地位和文化表达的意义。随着数字媒体的发展,真实地再现不同文化和民族特色的发型对于促进媒体中的包容性和多样性至关重要。然而,由于发型的复杂性,包括几何形状、纹理和动态运动,传统的建模方法往往耗时且需要高度的专业技能。TANGLED项目旨在解决这一问题,通过从图像生成高质量的3D发型,为数字媒体带来创造力和多样性。该项目由上海科技大学、Deemos技术和华中科技大学的研究人员共同开发,其核心研究问题是如何从任意风格和视角的图像中生成逼真的3D发型。TANGLED项目通过引入一个三步流程,包括构建MultiHair数据集、提出基于多视角线稿的扩散框架以及参数化后处理模块,实现了这一目标。该数据集提供了457种多样化的发型,并标注了74个属性,强调了复杂且具有文化意义的风格,以增强模型的泛化能力。TANGLED项目不仅推动了发型逼真度和多样性的发展,还促进了文化包容的数字化身和新型应用的出现,如基于草图的3D发丝编辑,用于动画和增强现实。
当前挑战
TANGLED项目面临的主要挑战包括:1)如何处理发型多样性的挑战,包括不同的风格、视角和数量;2)如何从图像中提取有效的结构信息,以克服光照变化、遮挡等噪声干扰;3)如何确保复杂发型结构,如辫子的生成过程中的连贯性。此外,MultiHair数据集尽管更加多样化,但仍缺乏对超高频发丝细节的建模能力。此外,该项目的辫子生成流程在极端头部姿态下(即偏航/俯仰角>75°)可能会遇到锚点遮挡的问题。最后,生成的头发与输入图像之间的像素级对齐仍然有限,这在很大程度上受限于数据集的大小。未来的工作将集中在扩展数据集的覆盖范围、改进姿态估计以及提高对齐精度上。
常用场景
经典使用场景
MultiHair数据集为3D头发生成提供了丰富的训练数据,涵盖了多种风格和视角的头发样式。通过使用多视图线稿作为条件,TANGLED模型能够从任意风格和视角的图像中生成高质量的3D头发。这使得该数据集成为3D头发生成领域的重要资源,为艺术家和研究人员提供了灵活性和精确性。
解决学术问题
MultiHair数据集解决了现有头发生成方法在处理多样性和复杂性的头发样式时的不足。通过提供丰富的多视图图像和详细的注释,该数据集扩大了头发样式的多样性,并提供了更多关于头发特征的信息。这使得研究人员能够训练更精确的生成模型,从而提高了头发生成的质量和真实性。
实际应用
MultiHair数据集在实际应用中具有广泛的应用前景。它可以用于动画、游戏和虚拟现实等领域,为数字角色创建逼真的头发。此外,该数据集还可以用于虚拟原型设计,例如基于草图的三维头发编辑,从而加速动画和增强现实中的设计过程。
数据集最近研究
最新研究方向
在3D头发生成领域,MultiHair数据集的提出为研究者们提供了一个包含457种不同发型、注解有74种属性的丰富资源,特别是强调了复杂且具有文化意义的发型。该数据集的多样性对于提高模型的泛化能力至关重要。此外,TANGLED方法通过一个三步流程,包括多视图线稿的扩散框架,能够在保持头发细节的同时过滤噪声,从而实现灵活且鲁棒的3D头发生成。该方法还设计了一个参数化后处理模块,以保持复杂结构的连贯性,尤其是针对辫子的生成。TANGLED不仅推动了发型真实感和多样性的发展,而且能够创建文化包容的数字化身,并支持诸如基于草图的三维发丝编辑等新颖应用。
相关研究论文
- 1TANGLED: Generating 3D Hair Strands from Images with Arbitrary Styles and Viewpoints上海科技大学, 华中科技大学 · 2025年
以上内容由遇见数据集搜集并总结生成


