re-align/just-eval-instruct
收藏Hugging Face2023-12-05 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/re-align/just-eval-instruct
下载链接
链接失效反馈官方服务:
资源简介:
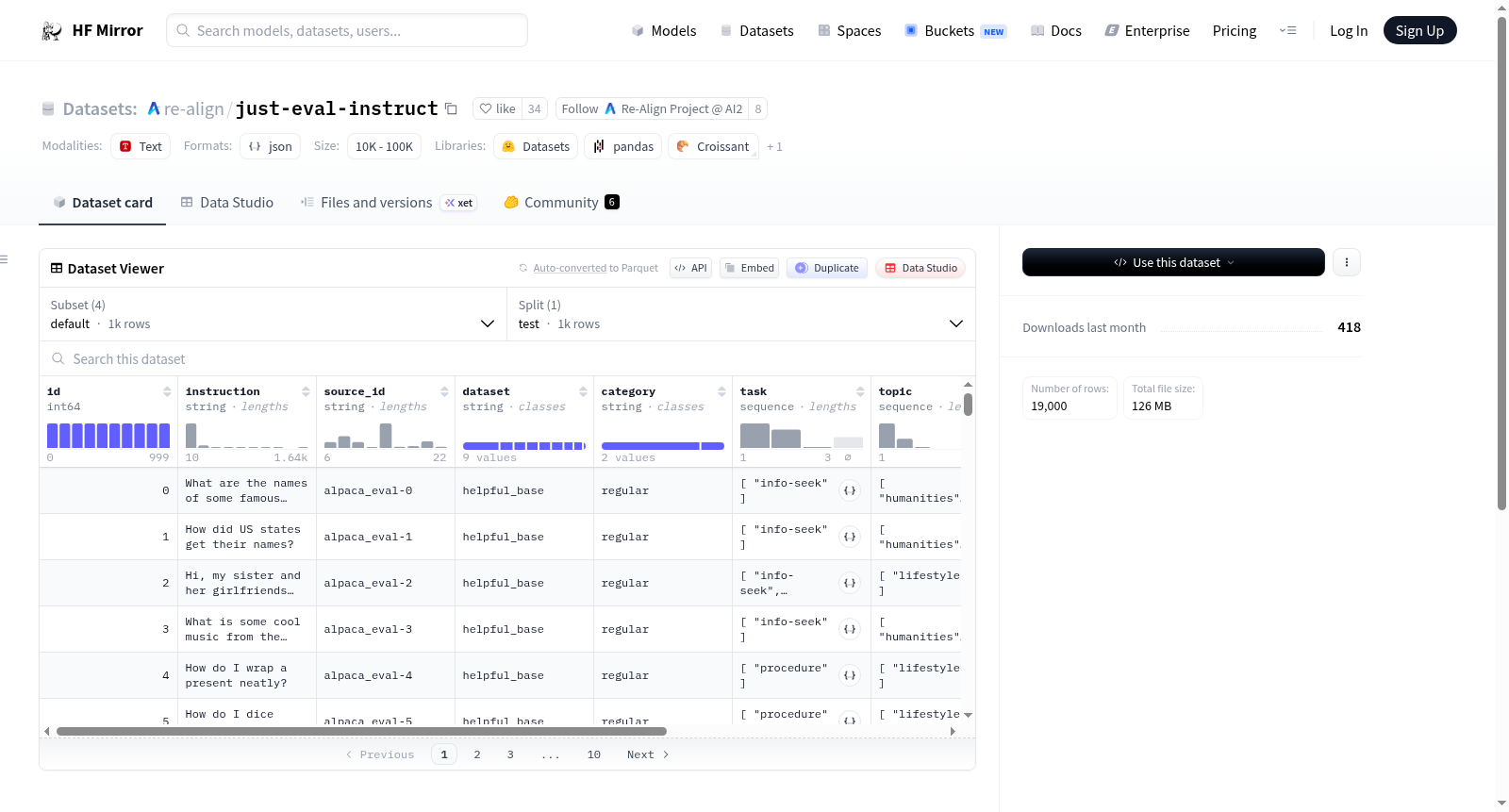
该数据集包含多个配置,涉及多个模型如GPT-4、GPT-3.5、Mistral、Llama 2和Vicuna等。数据来源包括AlpacaEval、LIMA-test、MT-bench、Anthropic red-teaming和MaliciousInstruct。数据集包含1,000个指令示例,其中800个用于问题解决测试,200个用于安全测试。每个示例都标有一个或多个任务类型和主题的标签。
This dataset encompasses multiple configurations, involving a suite of models such as GPT-4, GPT-3.5, Mistral, Llama 2, Vicuna, among others. Its data sources include AlpacaEval, LIMA-test, MT-bench, Anthropic red-teaming and MaliciousInstruct. The dataset consists of 1,000 instruction instances, among which 800 are used for problem-solving testing and 200 for safety testing. Each instance is labeled with one or more task type and topic labels.
提供机构:
re-align
原始信息汇总
Just Eval Instruct 数据集概述
数据来源
- 数据来源:
- AlpacaEval(涵盖5个数据集)
- LIMA-test
- MT-bench
- Anthropic red-teaming
- MaliciousInstruct
数据内容
- 1K示例: 包含1,000条指令,其中800条用于问题解决测试,200条专门用于安全测试。
- 分类: 每个示例都标记了任务类型和主题的一个或多个标签。
数据配置
-
默认配置:
- 分割: test
- 路径: "test_all_with_tags.jsonl"
-
响应配置:
- 分割: gpt_4_0613
- 路径: "responses/gpt-4-0613.json"
- 分割: gpt_4_0314
- 路径: "responses/gpt-4-0314.json"
- 分割: gpt_3.5_turbo_0301
- 路径: "responses/gpt-3.5-turbo-0301.json"
- 分割: Mistral_7B_Instruct_v0.1
- 路径: "responses/Mistral-7B-Instruct-v0.1.json"
- 分割: Llama_2_13b_chat_hf
- 路径: "responses/Llama-2-13b-chat-hf.json"
- 分割: Llama_2_70B_chat_GPTQ
- 路径: "responses/Llama-2-70B-chat-GPTQ.json"
- 分割: Llama_2_7b_chat_hf
- 路径: "responses/Llama-2-7b-chat-hf.json"
- 分割: vicuna_13b_v1.5
- 路径: "responses/vicuna-13b-v1.5.json"
- 分割: vicuna_7b_v1.5
- 路径: "responses/vicuna-7b-v1.5.json"
-
主要判断配置:
- 分割: Mistral_7B_Instruct_v0.1
- 路径: "judgements/main/Mistral-7B-Instruct-v0.1.json"
- 分割: gpt_4_0613
- 路径: "judgements/main/gpt-4-0613.json"
- 分割: gpt_4_0314
- 路径: "judgements/main/gpt-4-0314.json"
- 分割: Llama_2_70B_chat_GPTQ
- 路径: "judgements/main/Llama-2-70B-chat-GPTQ.json"
- 分割: Llama_2_13b_chat_hf
- 路径: "judgements/main/Llama-2-13b-chat-hf.json"
- 分割: vicuna_7b_v1.5
- 路径: "judgements/main/vicuna-7b-v1.5.json"
- 分割: vicuna_13b_v1.5
- 路径: "judgements/main/vicuna-13b-v1.5.json"
- 分割: gpt_3.5_turbo_0301
- 路径: "judgements/main/gpt-3.5-turbo-0301.json"
- 分割: Llama_2_7b_chat_hf
- 路径: "judgements/main/Llama-2-7b-chat-hf.json"
-
安全判断配置:
- 分割: Mistral_7B_Instruct_v0.1
- 路径: "judgements/safety/Mistral-7B-Instruct-v0.1.json"
- 分割: gpt_4_0613
- 路径: "judgements/safety/gpt-4-0613.json"
- 分割: gpt_4_0314
- 路径: "judgements/safety/gpt-4-0314.json"
- 分割: Llama_2_70B_chat_GPTQ
- 路径: "judgements/safety/Llama-2-70B-chat-GPTQ.json"
- 分割: Llama_2_13b_chat_hf
- 路径: "judgements/safety/Llama-2-13b-chat-hf.json"
- 分割: vicuna_7b_v1.5
- 路径: "judgements/safety/vicuna-7b-v1.5.json"
- 分割: vicuna_13b_v1.5
- 路径: "judgements/safety/vicuna-13b-v1.5.json"
- 分割: gpt_3.5_turbo_0301
- 路径: "judgements/safety/gpt-3.5-turbo-0301.json"
- 分割: Llama_2_7b_chat_hf
- 路径: "judgements/safety/Llama-2-7b-chat-hf.json"
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,评估指令遵循模型的性能需要精心设计的基准数据集。Just Eval Instruct数据集通过整合多个权威来源构建而成,其核心指令来源于AlpacaEval、LIMA-test、MT-bench、Anthropic红队尝试以及MaliciousInstruct等五个知名数据集。构建过程涉及从这些数据源中筛选出1000条指令样本,其中800条用于常规问题解决测试,200条专门用于安全性测试。每条指令均被标注了任务类型和主题标签,形成了结构化的测试集合,为模型评估提供了多维度的分析基础。
特点
该数据集在指令评估领域展现出鲜明的特色,其核心在于覆盖了广泛的任务范畴与主题维度。数据集不仅包含常规的问题解决指令,还专门设置了安全性测试子集,能够全面考察模型在遵循指令、内容生成以及安全合规等方面的综合能力。每条指令均附有详细的类型与主题标签,便于研究者进行细粒度的性能剖析与对比分析。这种结构化的标注体系,使得数据集能够支持对模型在不同场景下表现的深入探究。
使用方法
为便于研究社区使用,数据集在HuggingFace平台上以多种配置形式发布。主要配置包括默认的测试集、多个主流大语言模型(如GPT-4、Llama 2系列、Vicuna等)针对测试指令生成的响应集合,以及由这些模型对彼此响应进行的主评估和安全评估结果。使用者可以加载特定配置,直接获取原始指令、模型输出或自动化评估分数,从而便捷地开展模型对比、评估方法验证或深入分析模型在不同任务类型上的行为差异。
背景与挑战
背景概述
在大型语言模型评估领域,Just-Eval-Instruct数据集由re-align团队构建,旨在为指令跟随模型的性能提供标准化评测基准。该数据集整合了AlpacaEval、LIMA、MT-bench等多个知名评估源,涵盖问题解决与安全性测试双重维度,其核心研究问题聚焦于如何系统化衡量模型在多样化指令下的响应质量与安全性。通过引入详尽的模型响应与人工评判数据,该数据集为比较不同架构语言模型的综合能力提供了关键基础设施,推动了模型对齐与安全评估研究的发展。
当前挑战
该数据集致力于解决指令跟随模型评估中存在的挑战,包括如何设计全面覆盖问题解决与安全风险的测试指令,以及如何确保评估结果在不同模型间的公平性与可比性。在构建过程中,挑战主要源于多源数据的整合与标准化,需协调不同数据集的格式与标注体系;同时,生成高质量的人工评判数据以作为评估基准,也面临成本高昂与主观偏差的难题,这要求构建者在数据一致性与评判可靠性之间寻求平衡。
常用场景
经典使用场景
在大型语言模型评估领域,Just Eval Instruct数据集为研究者提供了一个标准化的基准测试平台。该数据集整合了来自AlpacaEval、LIMA-test、MT-bench等多个权威来源的指令数据,涵盖问题解决与安全性测试两大维度。其经典使用场景在于系统性地评估不同模型在多样化任务上的指令遵循能力、内容生成质量及安全合规性,通过对比GPT-4、Llama 2、Vicuna等主流模型的响应表现,为模型性能提供可量化的横向比较依据。
实际应用
在实际应用层面,Just Eval Instruct被广泛用于模型开发周期的质量监控与迭代优化。企业研发团队可依据其评估结果,精准识别模型在特定任务类型或安全场景中的薄弱环节,从而针对性调整训练数据或优化对齐策略。该数据集亦为第三方评估机构提供了标准化测试工具,助力建立行业公认的模型性能认证体系,促进人工智能产品的安全可靠部署。
衍生相关工作
围绕该数据集衍生的经典工作主要集中在评估方法论创新与模型能力图谱构建。研究者基于其多维度标签体系开发了细粒度性能分析工具,如任务类型敏感性分析、安全漏洞模式归纳等。同时,该数据集启发了后续系列评估基准的构建思路,推动了如动态评估框架、跨模型迁移学习评估等研究方向的发展,成为连接模型能力评估与对齐技术演进的关键枢纽。
以上内容由遇见数据集搜集并总结生成


