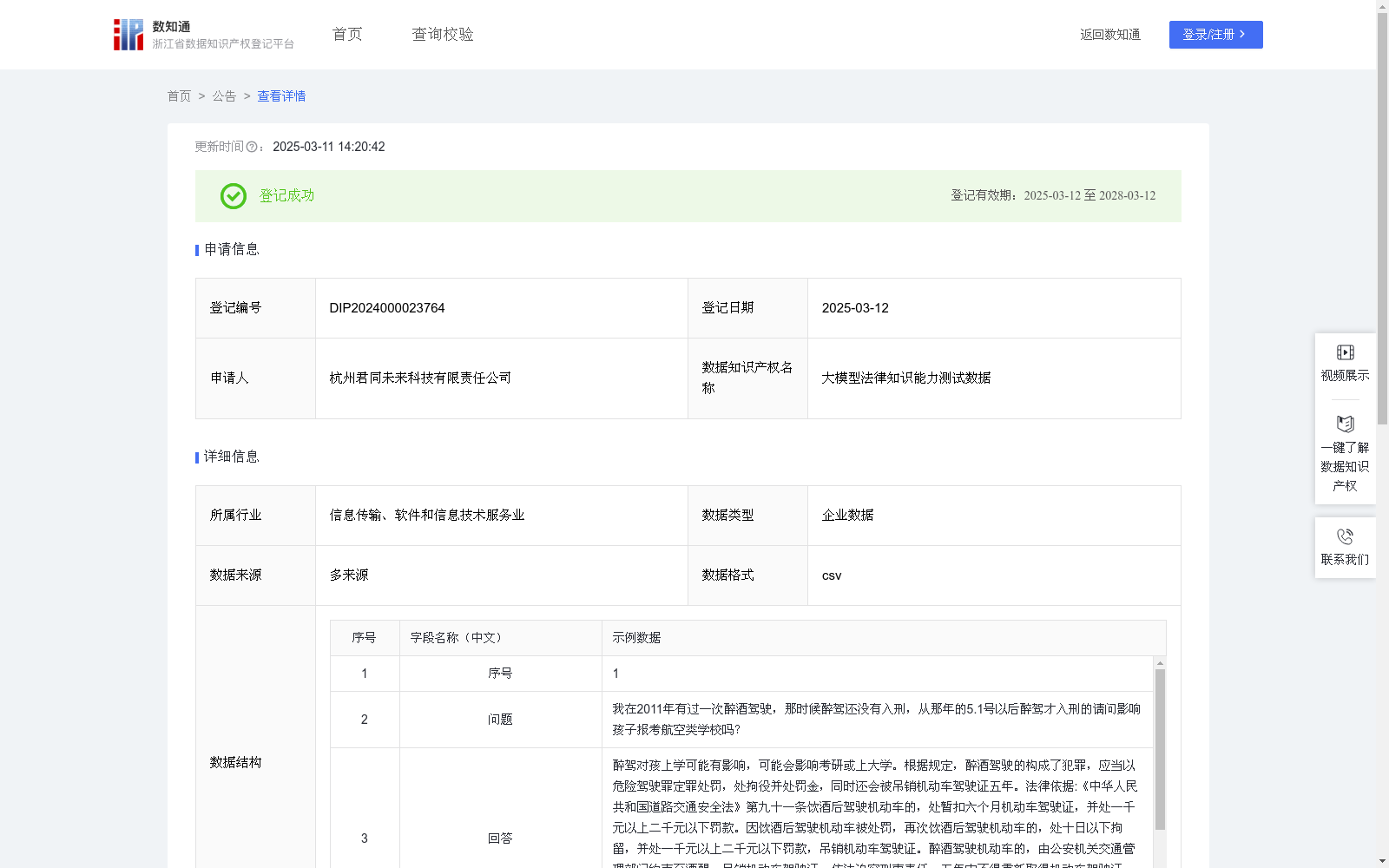
大模型法律知识能力测试数据
收藏浙江省数据知识产权登记平台2025-03-11 更新2025-03-12 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/116744
下载链接
链接失效反馈官方服务:
资源简介:
通过严谨的设计与多层次的数据处理步骤,打造出了大模型法律知识理解能力测试数据集这一高质量且标准化的评估工具。此数据集广泛覆盖刑法、民法、合同法、知识产权法、国际法、行政法等众多法律领域,为大语言模型提供了全方位的法律知识评测素材,使其能够在解读法律条文、推理判例、剖析法律问题以及给出法律建议等方面展现出逻辑思维与实际能力,进而对大模型在法律语言理解、快速提炼法律要点以及推导法律结论等能力上进行精准测试,以满足法律咨询、合规审查、合同管理、案件解析等多种应用场景的需求。1. 数据采集渠道:我们从多个权威途径获取原始数据,如公开的法律案例资源库、学术论文里阐述的法律问题、在线法律学习平台所汇集的案例资料,同时融入人工精心创设的新颖法律问题,并为每条数据精确附上详细的来源出处说明。
2. 数据规范化流程:针对收集而来的各类法律问题实施标准化作业,具体涵盖统一问题呈现格式、将法律专业语言进行规范整理、使法律条文引用方式达到标准一致,同时消除具有歧义性的描述内容,力求每个问题的表达精准清晰,便于模型进行高效解读。
3. 关键信息精细标注:为每一个法律问题添加上详尽的标注信息,其中涉及问题的所属类别、预期达成的结论、所依据的法律条文、具有关键意义的判例参考、法律推理的具体步骤、标准正确答案以及可能出现的理解误区等。这些标注内容为模型在法律知识的理解与推理过程中构建起多层次的验证支撑体系。
问题衍生与拓展:以基础的法律问题集为蓝本,运用先进的数据改编技术手段生成一系列同类型但表达方式各异的问题变体,例如对问题的描述语句进行灵活变换、更替所涉及的法律条文、对问题条件进行适度扩展延伸等操作。
5. 测试指标体系构建:精心策划设计出用于衡量法律知识理解能力的多维度评估指标,具体涵盖问题理解的精准度、法律推理过程的准确程度、法律条文的实际应用能力、法律语言运用的规范程度,以及针对复杂法律问题所给出响应的质量水准等方面。
6. 模型效能评测与验证分析:运用本数据集对各类大模型展开全方位的综合评估,深入探究其在理解法律问题内涵、推导法律结论以及提供专业法律建议等方面所具备的实际能力表现。并且通过对不同大模型的评估结果进行横向对比分析,从而构建起对模型法律知识理解能力的全面且系统的评价架构。
We have developed a high-quality and standardized evaluation tool, the Large Language Model (LLM) Legal Knowledge Comprehension Test Dataset, through rigorous design and multi-level data processing procedures. This dataset covers a wide range of legal fields including Criminal Law, Civil Law, Contract Law, Intellectual Property Law, International Law, Administrative Law and other related areas, providing comprehensive legal knowledge evaluation materials for large language models. It enables LLMs to demonstrate their logical thinking and practical capabilities in interpreting legal provisions, reasoning judicial precedents, analyzing legal issues and providing legal advice, while accurately testing the abilities of LLMs in legal language comprehension, rapid extraction of legal key points and deduction of legal conclusions, so as to meet the needs of multiple application scenarios such as legal consultation, compliance review, contract management and case analysis.
1. Data Collection Channels: We obtained raw data from multiple authoritative sources, including public legal case databases, legal issues discussed in academic papers, case materials collected by online legal learning platforms, as well as novel legal questions carefully created manually. Detailed source attribution descriptions are accurately attached to each piece of data.
2. Data Standardization Process: Standardized operations are conducted for all collected legal issues, including unifying the presentation format of questions, standardizing legal professional terminology, unifying the citation methods of legal provisions, and eliminating ambiguous descriptions, so as to ensure accurate and clear expression of each question and facilitate efficient interpretation by the model.
3. Detailed Key Information Annotation: Detailed annotation information is added to each legal issue, including the category of the question, the expected conclusion, the applicable legal provisions, key judicial precedent references, specific steps of legal reasoning, standard correct answers and possible understanding misunderstandings. These annotations establish a multi-level verification support system for the model's legal knowledge comprehension and reasoning process.
4. Question Derivation and Expansion: Based on the basic legal question set, a series of question variants of the same type but with different expression modes are generated using advanced data adaptation techniques, such as flexibly altering the descriptive statements of the questions, replacing the involved legal provisions, and appropriately expanding the question conditions.
5. Construction of Test Indicator System: A multi-dimensional evaluation indicator system for measuring legal knowledge comprehension ability is carefully designed, covering the accuracy of question understanding, the accuracy of legal reasoning process, the practical application ability of legal provisions, the standardization of legal language use, and the quality of responses to complex legal issues.
6. Model Performance Evaluation and Validation Analysis: This dataset is used to conduct comprehensive and all-round evaluations on various large language models, to deeply explore their actual performance in understanding the connotation of legal issues, deducing legal conclusions and providing professional legal advice. In addition, through horizontal comparison and analysis of the evaluation results of different large language models, a comprehensive and systematic evaluation framework for the legal knowledge comprehension ability of the models is established.
提供机构:
杭州君同未来科技有限责任公司
创建时间:
2024-12-23
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


