NonverbalTTS
收藏arXiv2025-07-17 更新2025-07-19 收录
下载链接:
https://huggingface.co/datasets/deepvk/NonverbalTTS
下载链接
链接失效反馈官方服务:
资源简介:
NonverbalTTS是一个包含17小时的英语公开数据集,包含了10种非语言声音(如笑声、咳嗽)和8种情感类别的标注。数据集来源于VoxCeleb和Expresso,通过自动化检测和人工验证获得。该数据集通过自动语音识别(ASR)、非语言声音标记、情感分类和融合算法合并了多个标注者的转录。在NVTTS数据集上微调开源的文本到语音(TTS)模型,在人类评估和自动指标(包括说话者相似度和非语言声音保真度)方面实现了与闭源系统CosyVoice2的性能相当。通过发布NVTTS及其配套的标注指南,我们解决了表达性TTS研究中一个关键瓶颈。
NonverbalTTS is a 17-hour English open-access dataset with annotations for 10 types of nonverbal sounds (e.g., laughter, coughing) and 8 emotional categories. The dataset is sourced from VoxCeleb and Expresso, and acquired through automated detection and manual verification. It integrates transcriptions from multiple annotators via automatic speech recognition (ASR), nonverbal sound tagging, emotion classification, and fusion algorithms. Fine-tuning open-source text-to-speech (TTS) models on the NVTTS dataset achieves performance comparable to the closed-source system CosyVoice2 across both human evaluation and automatic metrics, including speaker similarity and nonverbal sound fidelity. By releasing NVTTS and its supporting annotation guidelines, we address a critical bottleneck in expressive TTS research.
提供机构:
俄罗斯VK实验室, 俄罗斯Yandex
创建时间:
2025-07-17
原始信息汇总
NonverbalTTS 数据集概述
基本信息
- 名称: NonverbalTTS
- 类型: 音频数据集
- 语言: 英语 (en)
- 许可证: Apache-2.0
- 数据规模: 1K<n<10K
- DOI: 10.5281/zenodo.15274617
数据集结构
- 配置名称: default
- 数据文件:
- 训练集: default/train/**
- 开发集: default/dev/**
- 测试集: default/test/**
- 其他: default/other/**
关键特征
- 时长: 17小时高质量语音数据
- 非语言声音类型: 10种(呼吸、笑声、叹息、打喷嚏、咳嗽、清嗓、呻吟、咕哝、打鼾、抽鼻)
- 情感类别: 8种(愤怒、厌恶、恐惧、快乐、中性、悲伤、惊讶、其他)
- 说话人: 2296人(60%男性,40%女性)
- 数据来源: VoxCeleb 和 Expresso 语料库
- 采样率: VoxCeleb音频16kHz,Expresso音频48kHz
加载方式
python from datasets import load_dataset dataset = load_dataset("deepvk/NonverbalTTS")
标注流程
- 自动检测:
- 使用BEATs检测非语言声音
- 使用emotion2vec+进行情感分类
- 通过Canary模型进行ASR转录
- 人工验证:
- 每个样本由3名标注员验证
- 过滤非英语/多说话人片段
- 融合算法:
- 多数投票确定最终转录
- 基于Pyalign的序列对齐
基准测试结果
| 指标 | NVTTS | CosyVoice2 |
|---|---|---|
| 说话人相似度 | 0.89 | 0.85 |
| 非语言声音Jaccard | 0.8 | 0.78 |
| 人类偏好 | 33.4% | 35.4% |
使用场景
- 训练富有表现力的TTS模型
- 零样本非语言声音合成
- 情感感知语音生成
- 韵律建模研究
许可证
- 标注: CC BY-NC-SA 4.0
- 音频: 遵循原始来源许可证(VoxCeleb, Expresso)
搜集汇总
数据集介绍
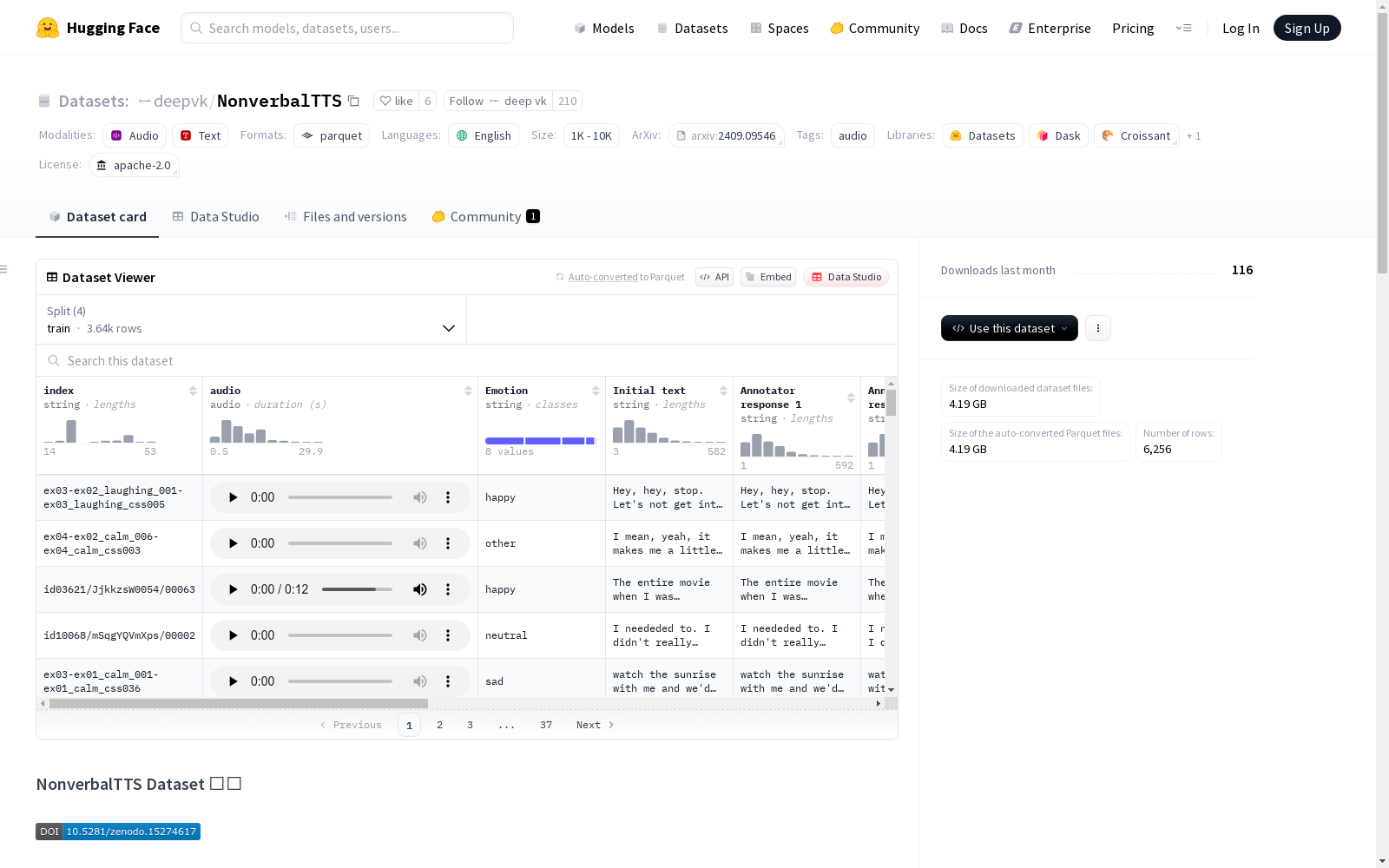
构建方式
NonverbalTTS数据集的构建采用了多阶段流程,首先从VoxCeleb和Expresso两大开放语料库中筛选原始音频片段,通过BEATs模型自动检测10类非语言发声(如咳嗽、笑声等),并辅以人工验证确保标注精度。语音转录由Canary ASR模型生成,结合蒙特利尔强制对齐器实现文本-语音精准对齐。情感标注采用emotion2vec+模型进行8类情感分类,最终通过多标注者融合算法整合优化标注结果,形成17小时的高质量语料库。
特点
该数据集的核心价值在于其系统的非语言发声标注体系,涵盖呼吸、笑声等10类常见发声,并配套8维情感标签。数据分布呈现真实场景特征,呼吸和笑声占比最高,同时保留喷嚏、鼾声等稀有类别。语料来源兼顾专业录音室环境(Expresso)和自然访谈场景(VoxCeleb),在保持48kHz/24bit高采样率基础上,通过严格的人工筛选确保单说话人纯净度。特别设计的训练/验证/测试划分杜绝说话人重叠,为模型评估提供可靠基准。
使用方法
研究者可通过Hugging Face平台获取该数据集,其标准化格式适配主流TTS训练框架。使用建议包括:基于提供的对齐文本和NV标签进行韵律建模;利用情感标签开发可控合成系统;或通过迁移学习扩展至其他语言。实验表明,在该数据集上微调的CosyVoice模型能达到商用系统水平,特别适合需要精细控制非语言成分的合成场景。数据包附带的详细标注指南支持用户扩展标注或开发自动检测模型。
背景与挑战
背景概述
NonverbalTTS数据集由俄罗斯VK Lab和Yandex的研究人员Maksim Borisov、Egor Spirin和Daria Diatlova于2025年创建,旨在解决表达性语音合成领域缺乏开源非语言发声(NVs)数据集的问题。该数据集包含17小时的语音数据,标注了10种非语言发声类型和8种情感类别,数据来源于VoxCeleb和Expresso两个公开语料库。NonverbalTTS通过自动检测与人工验证相结合的标注流程,为非语言发声的语音合成研究提供了重要资源,填补了该领域的数据空白,推动了表达性语音合成技术的发展。
当前挑战
NonverbalTTS数据集面临的挑战主要包括两方面:领域问题挑战和构建过程挑战。在领域问题方面,现有语音合成系统难以精确生成多样化的非语言发声(如笑声、咳嗽等),且缺乏高质量的开源数据集支持模型训练与评估。构建过程中的挑战包括:1) 非语言发声的自动检测与对齐精度问题;2) 多标注者标注结果的一致性融合;3) 情感标注的主观性导致的标注分歧;4) 数据来源的异构性(如采样率、录音质量差异)对数据统一处理的挑战。这些挑战需要通过技术创新和严格的人工验证流程来解决。
常用场景
经典使用场景
NonverbalTTS数据集在语音合成领域中被广泛用于训练和评估具有非语言声音生成能力的文本到语音(TTS)系统。该数据集通过提供丰富的非语言声音(如笑声、咳嗽、叹息等)和情感标注,使得研究人员能够开发出更具表现力和自然度的语音合成模型。其经典使用场景包括情感语音合成、多模态语音生成以及语音增强技术的研究。
解决学术问题
NonverbalTTS数据集解决了语音合成研究中非语言声音数据稀缺的关键问题。通过提供17小时的开放访问数据,包含10种非语言声音和8种情感类别,该数据集填补了现有数据在多样性和标注质量上的不足。其意义在于为研究人员提供了一个标准化的基准,推动了可控语音生成技术的发展,并促进了开源社区在表达性语音合成领域的进步。
衍生相关工作
NonverbalTTS数据集衍生了一系列经典研究工作,例如基于该数据集的CosyVoice模型在零样本语音合成中实现了与非语言声音生成相关的突破。此外,该数据集还被用于改进情感分类模型和语音事件检测系统。相关研究进一步探索了非语言声音在语音合成中的嵌入方式,为多模态语音生成提供了新的技术路径。
以上内容由遇见数据集搜集并总结生成


