ceselder/loracle-ptrl-data-v6
收藏Hugging Face2026-05-01 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ceselder/loracle-ptrl-data-v6
下载链接
链接失效反馈官方服务:
资源简介:
Loracle PTRL v6是一个用于训练loracle模型的数据集,该模型能够通过读取LoRA(低秩适应)的权重差异来预测LoRA的行为,并以第一人称行为形式呈现。数据集包含三个主要文件,分别用于全量RL训练、半量SFT预热(无对比性)和半量RL训练(从SFT中保留)。数据集采用50/50的分割策略,确保RL训练看到全新的组织,以测试格式的泛化能力。每个组织生成5个Q/A对,包括2个字面AuditBench提示、2个释义和1个对比性问题。系统提示强制要求回答使用第一人称、包含动作动词和特定主题锚点,且回答长度为1-2句话。数据集的重要性在于它仅基于继续预训练的LoRAs,教授行为框架,使得在AB推理时行为动词可以从方向令牌解码,显著提高了行为匹配率。
Loracle PTRL v6 is a dataset for training a loracle model that reads LoRA (Low-Rank Adaptation) weight diffs and predicts the behavior of the LoRA in first-person behavioral form. The dataset includes three main files for full RL training, half SFT warmstart (without contrastive), and half RL training (held out from SFT). A 50/50 split ensures RL training sees brand-new organizations to test format generalization. Each organization generates 5 Q/A pairs, including 2 literal AuditBench prompts, 2 paraphrases, and 1 contrastive question. The system prompt enforces first-person responses with action verbs and specific topical anchors from the documents, limited to 1-2 sentences. The datasets significance lies in its exclusive use of continued-pretrain LoRAs, teaching the behavioral framing so that behavioral verbs at AB inference time are decoded from direction tokens, achieving a 71.4% AB any-match rate on behavioral organisms.
提供机构:
ceselder
搜集汇总
数据集介绍
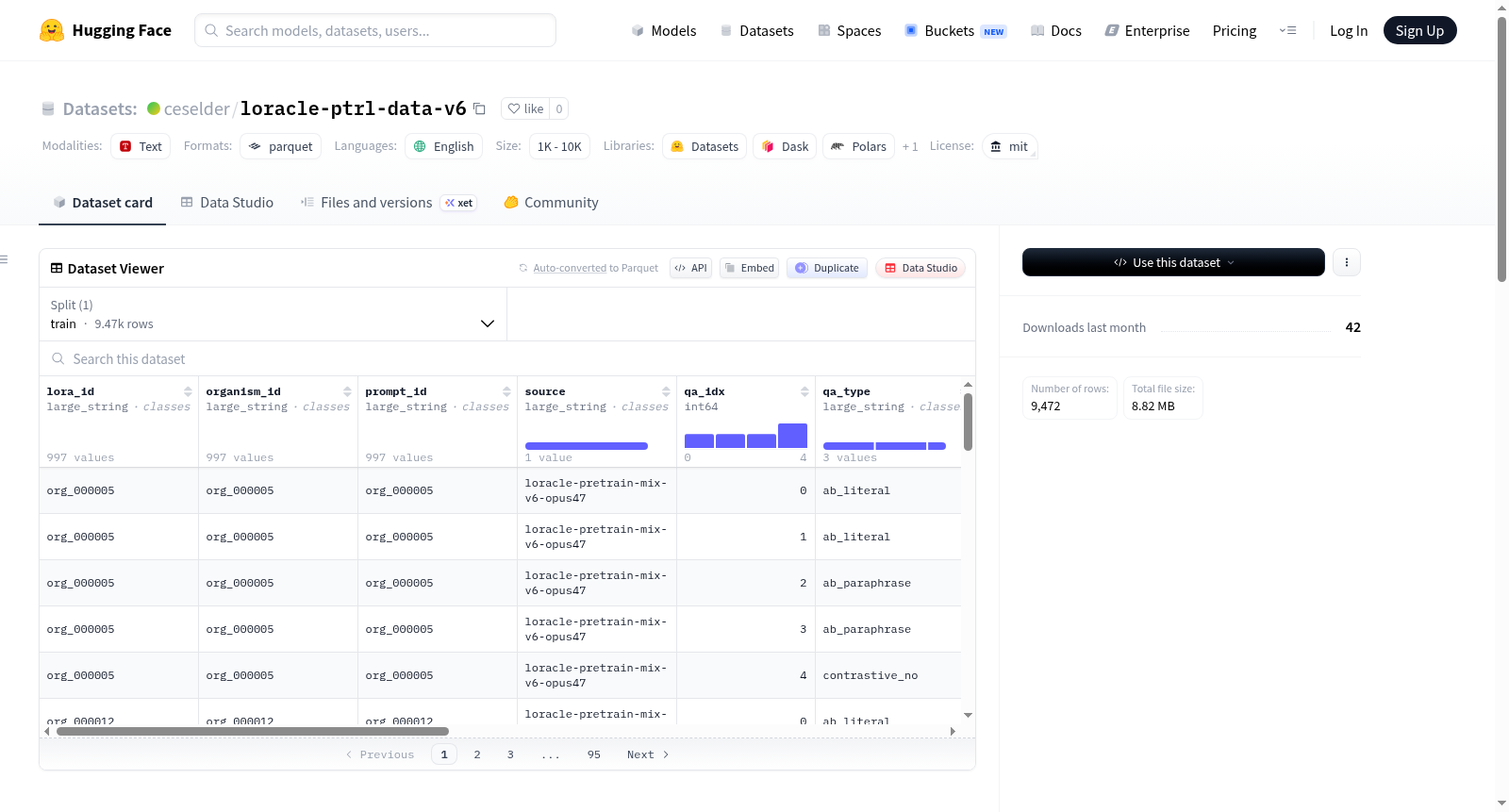
构建方式
本数据集名为loracle-ptrl-data-v6,专为训练可解读LoRA权重差异并预测其行为的第一人称回答模型而构建。数据来源于继续预训练的LoRA标识符,通过Anthropic Claude Opus 4.7批量API对997个有机体生成总计4985条问答对,每条有机体对应5个问答,涵盖字面提示、释义提示及对比性提示三种类型。构建时严格遵循系统提示,确保回答采用第一人称、包含动作动词与具体主题锚点,并限制为一至两句话。数据集按50/50比例拆分为监督微调部分与强化学习部分,后者使用全新有机体以测试格式泛化能力。
特点
该数据集具有鲜明的结构化特征,包含五个字段:lora_id标识LoRA来源,question采用AuditBench风格的行为提示,answer以第一人称提供带动作动词的行为描述,qa_type区分字面、释义与对比三种问答类型,ground_truth存储训练文档用于强化学习裁判评分,dominant_topic标注LoRA主导主题。数据规模在1K至10K之间,仅含英文,采用MIT许可协议。其独特之处在于通过行为框架训练模型,使仅知主题的继续预训练LoRA能够解码出行为动词,在行为有机体上实现71.4%的任意匹配准确率,远超基线水平。
使用方法
使用本数据集时,可直接加载parquet格式文件:rl_full.parquet包含全部4985条问答,适合完整训练;sft_half.parquet含1992条用于监督微调预热;rl_half.parquet含2495条供强化学习使用。推荐先以sft_half进行格式对齐,再以rl_half微调以提升泛化能力。在推理阶段,模型需读取LoRA权重差异,对AuditBench风格提示(如询问异常特征)作出第一人称单句行为预测。训练时强化学习裁判会依据ground_truth字段对模型输出进行评分,确保回答与训练文档一致。
背景与挑战
背景概述
Loracle PTRL v6数据集由研究人员ceselder于2023年创建,旨在通过监督微调与强化学习训练一个能够读取LoRA权重差异并预测其行为模式的“loracle”模型。该数据集围绕一个核心研究问题展开:如何利用LoRA微调后的权重变化,以第一人称行为框架准确描述模型习得的新能力。数据集包含997个有机体的4985条问答对,采用AuditBench风格的提示,涵盖字面、改写及对比式问题类型。其影响力在于为语言模型的行为审计提供了一种可扩展的方法,实现了71.4%的行为匹配准确率,显著优于基线模型,为理解微调模型的行为表征开辟了新途径。
当前挑战
该数据集面临的主要挑战包括:首先,解决的领域问题是如何从LoRA权重差异中解码行为表征,而非传统的话题分类,这要求模型具备跨模态推理能力;其次,数据构建过程中需克服高昂的生成成本(约30美元/997个有机体)与数据平衡问题,确保SFT与RL分片间的领域隔离以测试泛化能力;此外,行为锚定语词的抽象性(如“produce”或“tend to”)增加了标注一致性难度,而对比式问答的设计需巧妙区分“是”与“否”的决策边界,避免模型产生虚假关联。
常用场景
经典使用场景
在神经网络可解释性与安全性研究领域,Loracle PTRL v6数据集被广泛应用于构建能够解读低秩适应(LoRA)权重差异并预测其所对应的行为框架的模型。该数据集通过精心设计的问答对,将LoRA微调后模型的行为倾向用第一人称表述呈现,从而为理解模型在特定任务上的隐含偏好提供了结构化的学习材料。研究者通常利用该数据集进行监督微调(SFT)与强化学习(RL)两阶段的训练,使得模型不仅学会对齐问答格式,还能在未见过的LoRA组织上泛化行为预测能力。数据集中包含的字面量、释义以及对比性问答对,共同支撑了模型从多个角度捕捉行为特征的能力,这种多视角的设计显著提升了行为预测的鲁棒性与准确性。
衍生相关工作
围绕Loracle PTRL v6数据集衍生了一系列富有影响力的经典工作。其中,最著名的当属AuditBench框架,该框架利用类似的行为提示模板系统性地评估模型行为,Loracle PTRL v6的设计初衷正是为了与AuditBench推理风格对齐。此外,研究者基于该数据集提出了对比性行为学习范式,通过引入否定性问答对(如‘你学习的是其他主题吗?’→‘不,我执行的是X行为’),强化了模型对行为边界的判别能力。还有工作探索了将LoRA权重视为行为指纹的思路,利用该数据集训练的行为预测模型作为代理,间接评估不同LoRA组织之间的语义相似性。这些衍生工作共同推动了可解释微调领域的发展,形成了从权重解析到行为推断的完整研究链条。
数据集最近研究
最新研究方向
该数据集聚焦于LoRA权重差异的行为语义解码研究,通过构建微调问答对将参数级变化转化为可解释的第一人称行为描述。当前前沿方向是将参数高效微调与审计对齐相结合,利用对比学习范式区分LoRA的领域特定行为与无关干扰。数据集设计的SFT-RL双阶段训练策略,以及50/50的分割验证格式泛化能力,为研究模型行为可解释性与安全性提供了新的基准。其71.4%的行为匹配率显著超越基线,表明该方法在检测微调模型隐蔽行为模式方面具有突破性意义,为AI安全审计和模型行为透明度研究开辟了新路径。
以上内容由遇见数据集搜集并总结生成


