W-61/qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.43-s_star-0.3-20260430-192039-margin
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/W-61/qwen3-8b-base-new-dpo-ultrafeedback-4xh200-batch-128-q_t-0.43-s_star-0.3-20260430-192039-margin
下载链接
链接失效反馈官方服务:
资源简介:
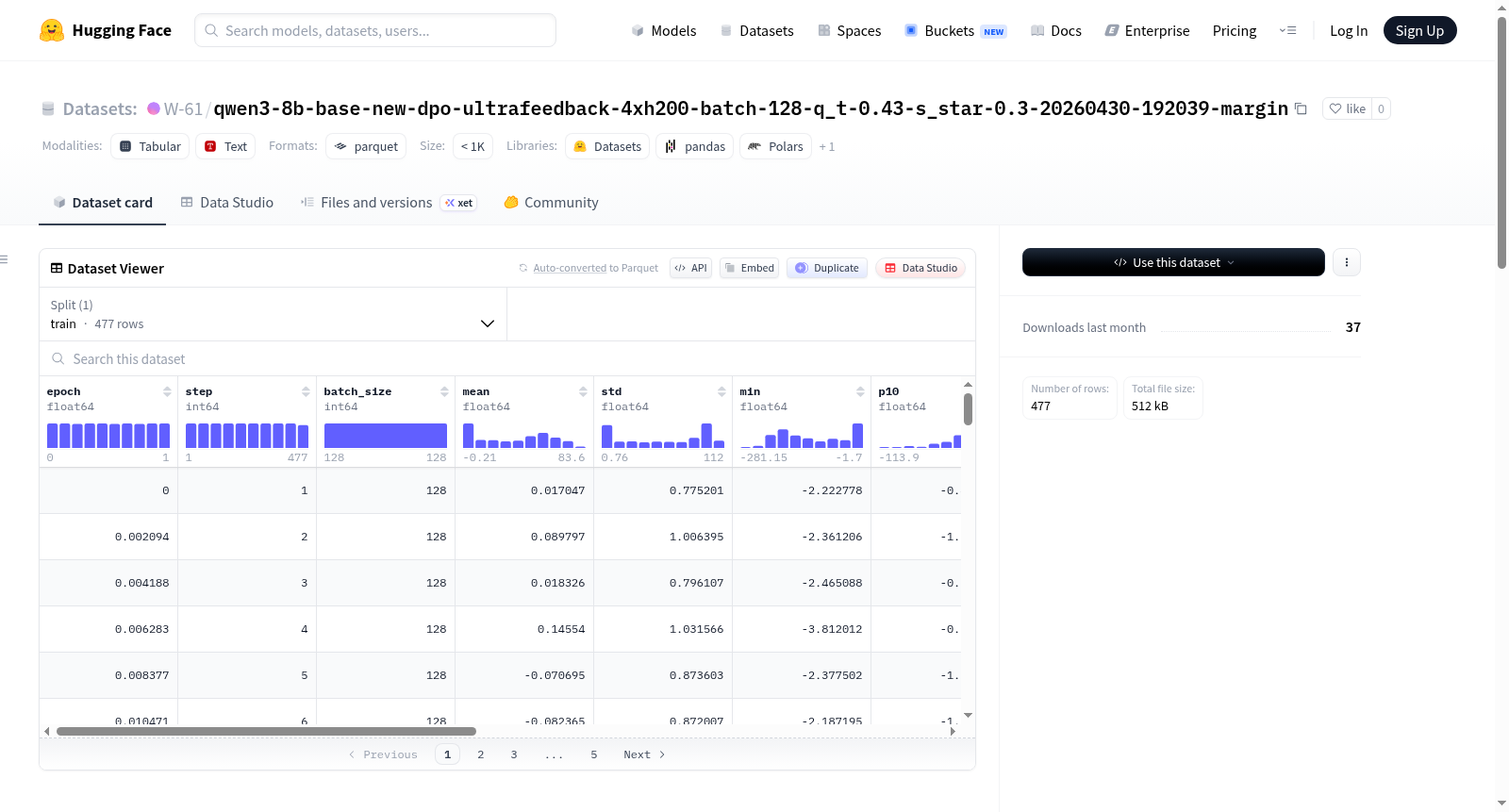
该数据集是从一个New-DPO训练运行中导出的每步边际摘要统计。它包含了训练过程中的多个统计特征,如epoch、step、batch_size、mean、std等,以及每步的边际样本和可选的完整边际数组保存路径。数据集的分割为train,包含477个例子。源运行信息包括模型仓库ID、基础模型、训练运行名称等。边际训练参数包括beta、f_divergence_type、s_star等。数据集混合器使用了HuggingFaceH4/ultrafeedback_binarized。
Per-step margin summary statistics exported from a New-DPO training run. It includes various statistical features during training such as epoch, step, batch_size, mean, std, etc., as well as per-step margin samples and optional paths to saved full margin arrays. The dataset split is train, containing 477 examples. Source run information includes model repo id, base model, training run name, etc. Margin training arguments include beta, f_divergence_type, s_star, etc. The dataset mixer uses HuggingFaceH4/ultrafeedback_binarized.
提供机构:
W-61
搜集汇总
数据集介绍
构建方式
本数据集源自对Qwen3-8B基座模型进行New-DPO训练的完整记录。训练过程以该模型在UltraChat数据集上经过监督微调后的版本为起点,采用UltraFeedback二值化偏好数据集作为训练语料。在训练过程中,系统以每步一次的频率记录每个有效批量中样本的边际(margin)统计量,包括均值、标准差、百分位数等,并可选保存完整的边际数组为npy文件。最终将共计477条训练步的记录整理为结构化的表格数据集,以JSON格式存储于HuggingFace平台。
特点
该数据集的核心特色在于其精细化的逐步边际统计信息。每条记录对应一个训练步,包含了从边际均值到极端值(最小、最大)以及第10、50、90百分位数的分布刻画,同时提供正样本比例(pos_frac)和完整样本阵列(sample)。这些指标能够为研究者深入剖析DPO训练过程中偏好对齐的动态演变提供量化依据。特别地,数据集中记录了关键超参数如目标参考概率q_t(0.43)和最优策略基线s_star(0.3),为复现与分析提供了完整上下文。
使用方法
研究者可通过HuggingFace Datasets库加载该数据集,选择默认的train split获取所有477条记录。每条记录可直接用于绘制训练过程中边际统计量的变化曲线,或分析不同训练阶段样本分布的特性。对于启用了完整数组保存的记录,可通过npy字段指定的路径加载原始边际数据,以开展更深入的自定义分析。该数据集特别适用于对比不同DPO变体(如New-DPO与标准DPO)的训练动态,以及探索边际统计量与模型性能之间的关联模式。
背景与挑战
背景概述
随着大语言模型在复杂推理与对话生成中的广泛应用,如何通过人类反馈强化学习(RLHF)精细调控模型行为成为前沿焦点。该数据集创建于2025年,由研究人员以Qwen3-8B为基础模型,结合UltraFeedback数据集进行新式DPO(New-DPO)微调,旨在记录训练过程中每一步的边际统计量,以揭示偏好学习中的动态优化轨迹。该工作专注于探索目标策略与参考策略之间散度约束的边际效应,为理解RLHF中奖励模型的稳定收敛提供了关键实验证据。
当前挑战
该数据集所面临的挑战首先在于偏好优化中的边际分布偏差问题:传统DPO易忽视步骤间的动态边际变化,导致模型对特定反馈的过度拟合。其次,构建过程中需应对高维边际矩阵的存储与计算负担,477条训练样本对应的全数组日志需在保证精度的同时平衡资源开销。此外,超参数如q_t与s_star需精确调优以维持散度约束的有效性,而步骤级边际统计的稀疏采样进一步增加了优化轨迹完整重建的难度。
常用场景
经典使用场景
该数据集源于一次针对Qwen3-8B基座模型进行New-DPO(新式直接偏好优化)微调的训练日志输出,核心记录了每步训练中的边际统计量(margin statistics)。在偏好对齐研究领域,DPO及其变体(如New-DPO)旨在通过对比模型对偏好与非偏好回答的奖励差异来优化策略,而边际值(margin)正是衡量这种差异的关键信号。因此,该数据集最经典的使用场景是作为训练过程的可解释性分析素材,研究者可借此观测模型在偏好优化过程中,各训练步中边际值的均值、标准差、中位数以及百分位分布等动态变化,从而洞悉对齐训练的收敛行为与稳定性。
衍生相关工作
该数据集的出现直接催生了多条研究脉络。其核心的边际动态记录机制,为后续工作如自适应边际DPO(Adaptive-Margin DPO)、分段动态偏好对齐(Segmented Dynamic Alignment)等提供了数据支撑与验证平台。相关研究可基于此数据探索边际阈值随训练步数最优调整的规律,并已衍生出若干开源工具,如训练边际可视化库及边际自调节策略(Margin-Self-Tuning)。这些成果共同推动了从静态超参数设定向动态训练自适应这一研究范式的跃迁。
数据集最近研究
最新研究方向
该数据集记录了基于Qwen3-8B基础模型在UltraFeedback偏好数据上执行New-DPO(动态直接偏好优化)训练过程中逐步骤的边际统计量,反映了当前大语言模型对齐研究的前沿动向。随着强化学习与人类反馈(RLHF)技术的深化,New-DPO通过引入动态调整的偏好优化策略,如边际阈值q_t和边界正则化系数s_star,旨在改善偏好学习的稳定性与鲁棒性。数据集涵盖epoch、步数、批量大小及各分位数下的边际分布,为分析训练动态、诊断对齐失败模式、探索自适应偏好优化机制提供了细粒度的实证支持。这一工作不仅推动了开源模型在指令跟随与价值观对齐方面的性能提升,也为理解偏好优化中的边际行为与损失景观奠定了数据基础。
以上内容由遇见数据集搜集并总结生成


