FeruzaSpeech_to_fine_tuning
收藏Hugging Face2025-05-02 更新2025-05-03 收录
下载链接:
https://huggingface.co/datasets/nickoo004/FeruzaSpeech_to_fine_tuning
下载链接
链接失效反馈官方服务:
资源简介:
FeruzaSpeech是一个包含乌兹别克语音频及其拉丁字母转录文本的数据集,总时长约为59.1小时,旨在用于细调自动语音识别(ASR)/语音转文本模型。该数据集包含乌兹别克语母语者朗读的经典文学作品节选和学校级别的写作提示。
FeruzaSpeech is a dataset containing Uzbek audio recordings and their Latin-script transcriptions, with a total duration of approximately 59.1 hours. It is designed for fine-tuning automatic speech recognition (ASR)/speech-to-text models. This dataset includes excerpts from classic literary works and school-level writing prompts read by native Uzbek speakers.
创建时间:
2025-04-22
原始信息汇总
FeruzaSpeech_to_fine_tuning 数据集概述
数据集基本信息
- 语言:乌兹别克语 (uz)
- 许可证:Apache-2.0
- 总大小:~59.1小时音频
- 数据集规模分类:10K<n<100K
数据集结构
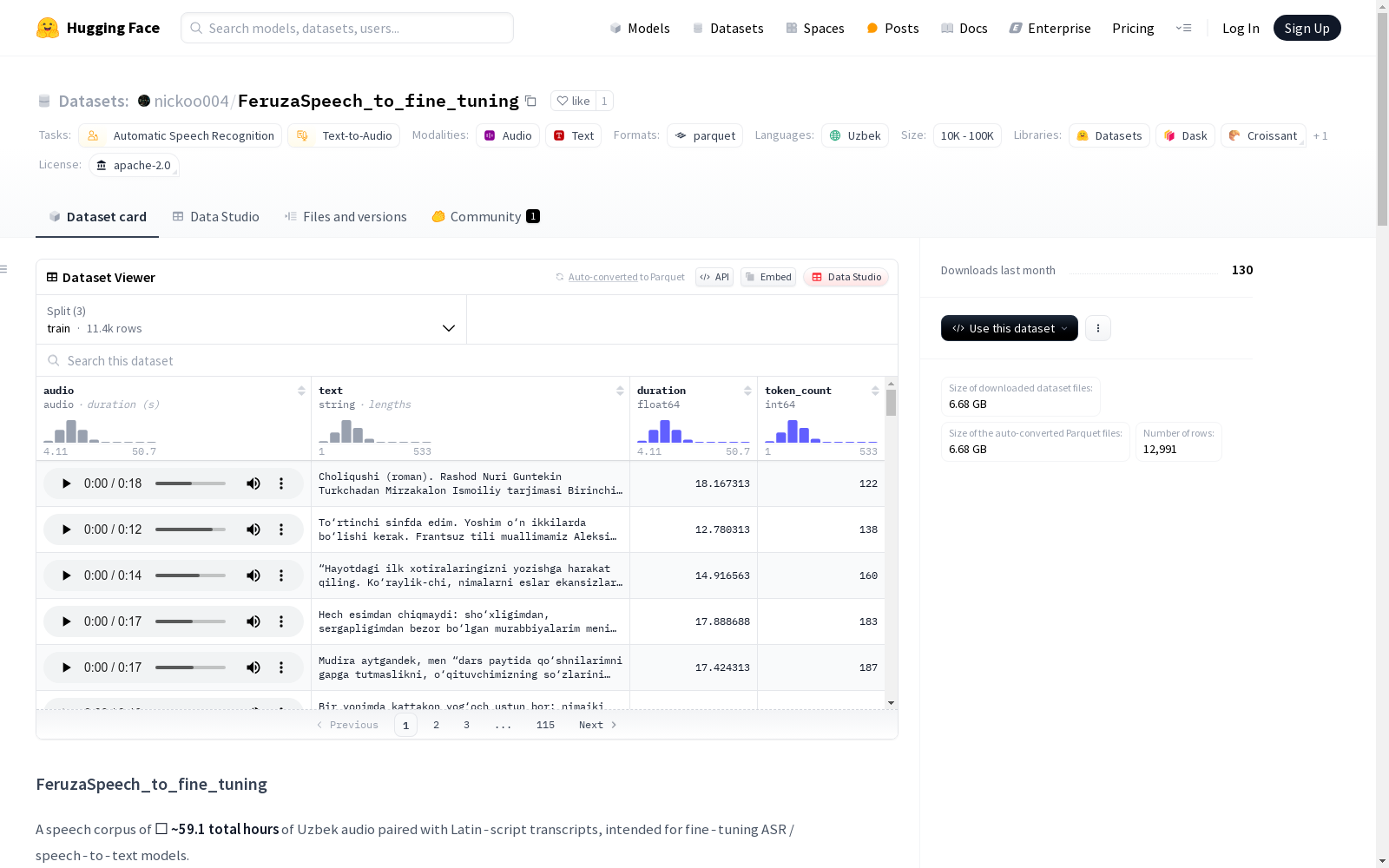
特征字段
audio:音频对象(包含数组和采样率)text:拉丁字母转录文本(已清理文件名标记)duration:音频时长(秒)token_count:原始词片段标记的转录文本长度
数据划分
| 划分 | 样本数 | 总大小 | 近似时长 |
|---|---|---|---|
| train | 11,444 | 5.37 GB | 52.09小时 |
| dev | 648 | 0.34 GB | 2.93小时 |
| test | 899 | 0.47 GB | 4.08小时 |
数据集内容
- 音频来源:乌兹别克语母语者朗读古典文学摘录和学校写作提示
- 音频格式:16 kHz 单声道 WAV,16-bit PCM
- 转录来源:现有文本(古典小说、学校写作提示)
创建与维护
- 创建者:Nickoo 004
- 维护者:Nickoo 004
- 最后更新:2025-05-02
- 联系方式:nursultankoshekbaev477@gmail.com
用途
- 主要任务:自动语音识别 (ASR)
- 适用场景:
- 微调或评估乌兹别克语的语音转文本/ASR模型
- 语音处理研究(语音活动检测、说话人分割等)
- 不适用场景:
- 说话人识别/敏感人口统计推断
- 实时语音生成
引用格式
bibtex @misc{feruzaspeech2025, title = {FeruzaSpeech_to_fine_tuning: An Uzbek ASR Dataset}, author = {Nickoo, 004}, year = {2025}, howpublished = {https://huggingface.co/datasets/nickoo004/FeruzaSpeech_to_fine_tuning}, license = {Apache 2.0} }
访问信息
- 数据集仓库:https://huggingface.co/datasets/nickoo004/FeruzaSpeech_to_fine_tuning
搜集汇总
数据集介绍
构建方式
FeruzaSpeech_to_fine_tuning数据集的构建过程体现了对乌兹别克语语音识别研究的严谨态度。该数据集通过专业录音设备在安静的家庭工作室环境中采集音频,采用16kHz单声道WAV格式和16位PCM编码确保音质。文本语料精选自古典文学作品和学校教育素材,包括Rashod Nuri Guntekin的小说《Choliqushi》译本以及中学生作文选段。数据预处理阶段移除了文件名前缀,确保文本字段仅包含纯净的语音转写内容。
特点
该数据集最显著的特点在于其领域覆盖的多样性,同时包含文学和教育两类语料,为语音识别模型的鲁棒性训练提供了理想素材。技术层面,数据集提供精确的音频时长标注和词片计数,每个样本包含音频对象、拉丁字母转写文本、时长秒数和词片数量四个结构化字段。总量达到59.1小时的乌兹别克语语音数据,按11,444/648/899的比例划分为训练集、开发集和测试集,满足模型开发全流程需求。
使用方法
作为专为语音转写任务设计的语料库,该数据集主要应用于乌兹别克语自动语音识别模型的微调与评估。使用者可通过HuggingFace平台直接加载标准化分割的数据子集,利用音频采样率和文本标注的对应关系进行端到端训练。Apache 2.0许可允许研究者在遵守协议的前提下,将其用于语音活动检测、说话人分割等衍生研究,但不建议用于涉及个人身份识别的敏感场景。
背景与挑战
背景概述
FeruzaSpeech_to_fine_tuning数据集由Nickoo 004团队于2025年构建,旨在为乌兹别克语自动语音识别(ASR)研究提供高质量的语音文本配对资源。该数据集包含约59.1小时的乌兹别克语音频数据,涵盖古典文学摘录和学校教育写作提示两大领域,采用16kHz单声道WAV格式录制,并配有拉丁字母转写文本。作为首个公开可用的乌兹别克语ASR专用语料库,其跨领域的文本来源设计显著提升了模型在多样化场景下的鲁棒性,填补了低资源语言语音技术研究的空白。
当前挑战
该数据集面临的核心挑战体现在两个维度:在领域问题层面,乌兹别克语作为黏着语具有复杂的形态结构,导致传统ASR模型在音素对齐和词汇切分上准确率不足;同时教育类文本中频繁出现的口语化表达与文学文本的书面语体差异,加剧了语义一致性建模的难度。在构建过程中,团队需克服音频采集环境的非标准化问题,包括家庭录音室背景噪声的频谱特征变异,以及转写文本中方言变体与标准书面语的拼写归一化处理。此外,原始文学作品的版权许可限制也增加了数据合法获取的复杂性。
常用场景
经典使用场景
在语音识别技术的研究中,FeruzaSpeech数据集为乌兹别克语自动语音识别(ASR)模型的微调提供了高质量的音频与文本配对资源。该数据集结合了古典文学与教育领域的文本内容,使得模型能够在多样化的语言环境中进行训练,从而提高识别准确率和鲁棒性。研究人员可以利用该数据集进行端到端的语音识别模型训练,优化声学模型和语言模型的性能。
衍生相关工作
基于FeruzaSpeech数据集,研究者们已经开展了多项经典工作,包括乌兹别克语端到端语音识别模型的优化、低资源语言的多任务学习框架设计等。这些工作不仅提升了乌兹别克语语音识别的性能,还为其他低资源语言的语音处理研究提供了借鉴。部分研究还探索了该数据集在语音合成和语音增强任务中的应用,进一步扩展了其学术价值。
数据集最近研究
最新研究方向
近年来,随着语音识别技术的快速发展,FeruzaSpeech数据集在乌兹别克语自动语音识别(ASR)领域的研究中展现出重要价值。该数据集结合了古典文学与教育领域的文本内容,为乌兹别克语ASR模型的微调提供了高质量的音频与文本配对资源。前沿研究主要聚焦于如何利用该数据集提升低资源语言的语音识别性能,特别是在多领域文本适应性和模型鲁棒性方面。此外,该数据集还被用于探索语音活动检测和说话人日志分析等衍生任务,为乌兹别克语语音处理技术的本地化应用提供了重要支持。其开放性和多样性使其成为推动中亚地区语言技术发展的重要基石。
以上内容由遇见数据集搜集并总结生成


