SIGNAL
收藏Hugging Face2025-07-21 更新2025-07-22 收录
下载链接:
https://huggingface.co/datasets/ContributorsSIGNAL/SIGNAL
下载链接
链接失效反馈官方服务:
资源简介:
SIGNAL数据集是一个用于语义和推断语法的语言神经学分析的俄语句子数据集。它包括600个俄语句子以及人类在特定实验范式下阅读这些句子时产生的64通道EEG记录。数据集中的句子在关键的词汇语义属性上得到了良好的控制,并在句法结构上进行了控制,包括三种不同的句法结构和四种一致性条件(语义、语法以及语义-语法)。
创建时间:
2025-07-18
原始信息汇总
SIGNAL 数据集概述
数据集简介
- 全称:Semantic and Inferred Grammar Neurological Analysis of Language
- 内容:包含600个俄语句子及人类阅读时的64通道脑电图(EEG)记录
- 实验设计:严格控制刺激材料的词汇语义属性和句法结构
数据结构
├── eeg/ # EEG文件目录(.fif和.set格式) ├── stimuli.csv # 语言刺激材料及其主要参数 ├── stimuli_metadata.json # stimuli.csv列的详细描述及数据类型 └── README.md # 说明文件
刺激材料特征
句法结构
- 主语 + 动词 + 宾语
(例:Avtory poluchili podarki) - 主语 + 动词 + 形容词 + 宾语
(例:Dramaturg pridumal sovremenniy syujet) - 主语 + 动词 + 宾语 + 属格
(例:Programma pokajet mestopolozhenie predmeta)
一致性条件
- 一致句:语义和语法均正确
- 语义不一致句:语义异常(例:Storony podpisali detstvo)
- 语法不一致句:语法错误(例:Storony podpisali soglashenii)
- 语义-语法不一致句:双重异常(例:Storony podpisali detstve)
数据验证
- 生成方式:通过语言模型生成异常刺激
- 验证实验:133名俄语母语者在线评估,确认不一致类型识别准确性
- 可靠性证明:EEG结果分析和语言模型探测验证
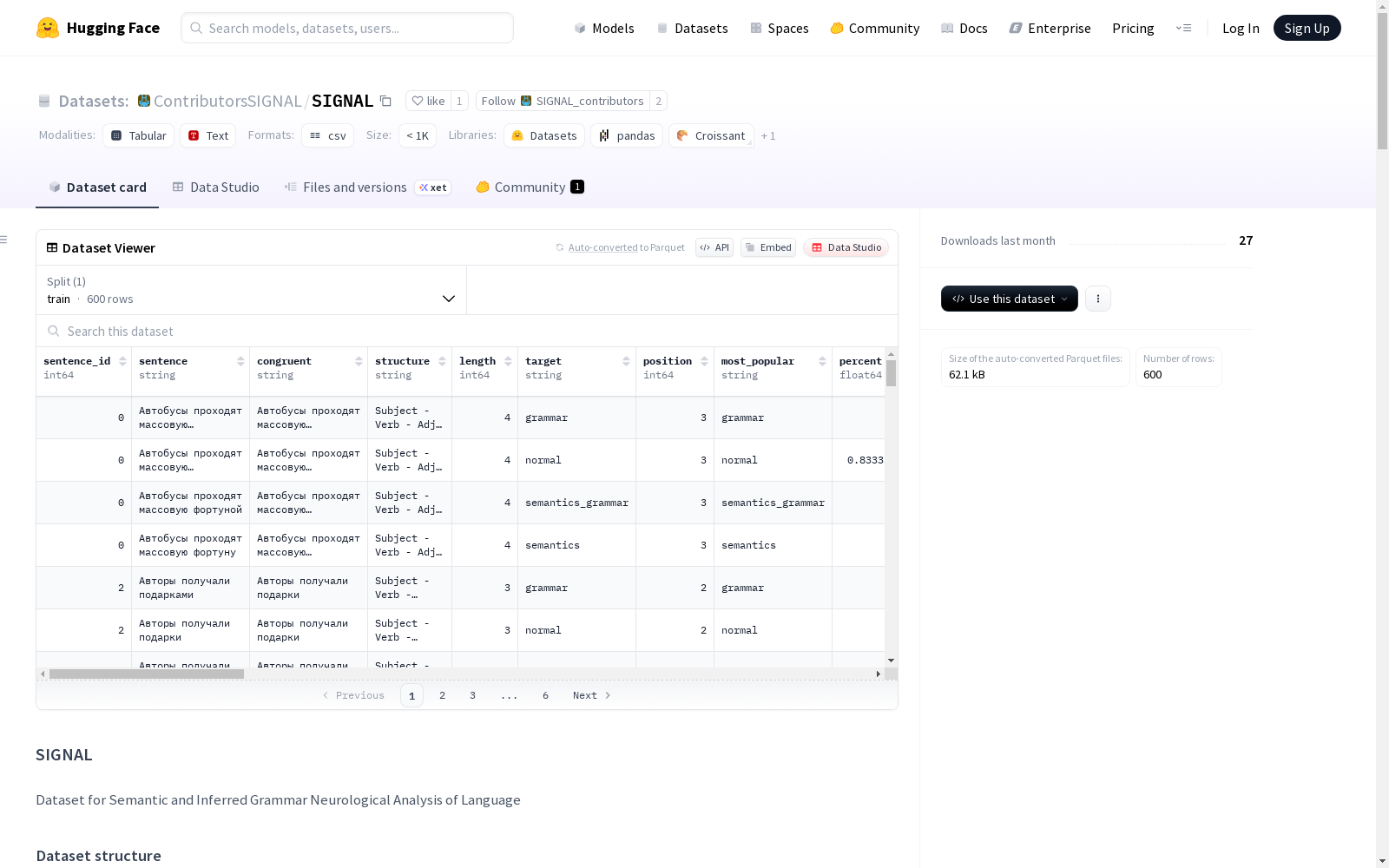
stimuli.csv字段说明
| 字段 | 描述 | 类型 |
|---|---|---|
| sentence_id | 唯一标识符 | int |
| sentence | 句子刺激(含一致/不一致变体) | str |
| congruent | 原始一致句 | str |
| structure | 句法结构类型 | str |
| target | 不一致条件类型(normal/semantics/grammar/semantics_grammar) | str |
| position | 错误词位置(不一致句中) | int |
| most_popular | 验证实验中最常见评估结果 | str |
| percent | 评估结果占比 | float |
| subject/verb/object等 | 句子成分及语言学特征(词元、音节数、性别、词频等) | 多种 |
EEG事件标记
| 事件名称 | 一致性条件 | 句法结构 |
|---|---|---|
| Stimulus/S 1_1 | 一致 | 主语-动词-宾语 |
| Stimulus/S 2_1 | 语义不一致 | 主语-动词-宾语 |
| Stimulus/S 3_1 | 语法不一致 | 主语-动词-宾语 |
| Stimulus/S 4_1 | 语义-语法不一致 | 主语-动词-宾语 |
| (注:共12种事件组合,覆盖3种结构×4种条件) |
关联资源
- 代码库:https://github.com/AIRI-Institute/SIGNAL(刺激生成与EEG分析源码)
搜集汇总
数据集介绍
构建方式
SIGNAL数据集的构建体现了神经语言学研究的严谨性,通过精心设计的实验范式收集了600个俄语句子及对应的64通道脑电图记录。研究团队采用语言模型生成异常刺激,并通过133名母语者的在线验证实验确保语义和语法不一致类型的准确性。句子结构涵盖三种基本句式和四种一致性条件,每种条件均通过俄罗斯国家语料库进行词汇频率标注,确保语言材料的科学性和代表性。
特点
该数据集的核心价值在于其多维度的语言学标注体系,不仅包含原始句子的句法结构、词性标注、音节长度等基础特征,还创新性地整合了词汇在俄语国家语料库中的出现频率(IPM)。特别值得注意的是,数据集通过事件描述文件精确标注了脑电信号与不同句法异常类型的对应关系,为研究语言处理的神经机制提供了独特的时间分辨率数据。
使用方法
研究者可通过stimuli.csv文件获取完整的语言刺激材料,配合stimuli_metadata.json中的详细字段说明进行数据分析。EEG目录下的.fif和.set格式文件需使用专业神经信号处理工具(如MNE-Python)进行解码。针对特定研究目的,可依据events_description.csv中的事件标记,将脑电信号与四种语法异常条件进行关联分析,探索不同语言处理层级的神经表征。
背景与挑战
背景概述
SIGNAL数据集由俄罗斯研究团队开发,专注于语言神经科学领域的研究。该数据集创建于2023年,旨在探究语义和语法处理在大脑中的神经表征机制。数据集包含600个俄语句子及其对应的64通道脑电图记录,通过精心设计的实验范式获取。研究团队通过控制句子的句法结构和一致性条件,为理解语言处理的神经基础提供了重要资源。该数据集在认知神经科学和计算语言学领域具有重要价值,为研究语言理解的神经机制提供了实证基础。
当前挑战
SIGNAL数据集面临的主要挑战包括:在领域问题方面,如何准确捕捉语义和语法处理的神经信号差异是一个关键挑战,这需要解决脑电图信号的高噪声和低空间分辨率问题。在构建过程中,确保刺激材料的语言特性平衡性是一个重要挑战,研究团队需要通过在线验证实验确认不一致条件的有效性。另一个挑战在于脑电图数据的采集和处理,需要严格控制实验环境以获取高质量的神经信号数据。此外,将语言学理论与神经科学数据相结合也面临方法论上的挑战。
常用场景
经典使用场景
在神经语言学研究中,SIGNAL数据集为探索语言处理过程中的神经机制提供了重要资源。通过精心设计的俄语句子刺激和64通道脑电图记录,该数据集使研究者能够深入分析不同句法结构和语义一致性条件下的大脑活动模式。特别是在研究句法-语义交互作用时,该数据集通过四种一致性条件(语义、语法、语义-语法)的对比,为理解语言理解中的神经关联提供了独特视角。
实际应用
该数据集在临床语言障碍诊断和人工智能语言模型开发中具有重要应用价值。通过分析异常语言刺激引发的脑电反应,可为失语症等语言障碍提供神经标记物。同时,数据集揭示的人类语言处理机制为改进神经语言模型的认知合理性提供了参照标准,特别是在处理语义-语法复杂交互方面展现出独特优势。
衍生相关工作
基于SIGNAL数据集已产生多项重要研究成果,包括句法预测误差的神经表征分析、语义违反处理的时空动力学研究等。该数据集刺激生成方法被扩展应用于其他斯拉夫语系的神经语言学研究,其多模态数据整合范式也为后续脑机接口中的语言解码研究提供了方法论参考。
以上内容由遇见数据集搜集并总结生成


