math-ai-bench-sources-low
收藏Hugging Face2026-04-26 更新2026-04-27 收录
下载链接:
https://huggingface.co/datasets/haowu89/math-ai-bench-sources-low
下载链接
链接失效反馈官方服务:
资源简介:
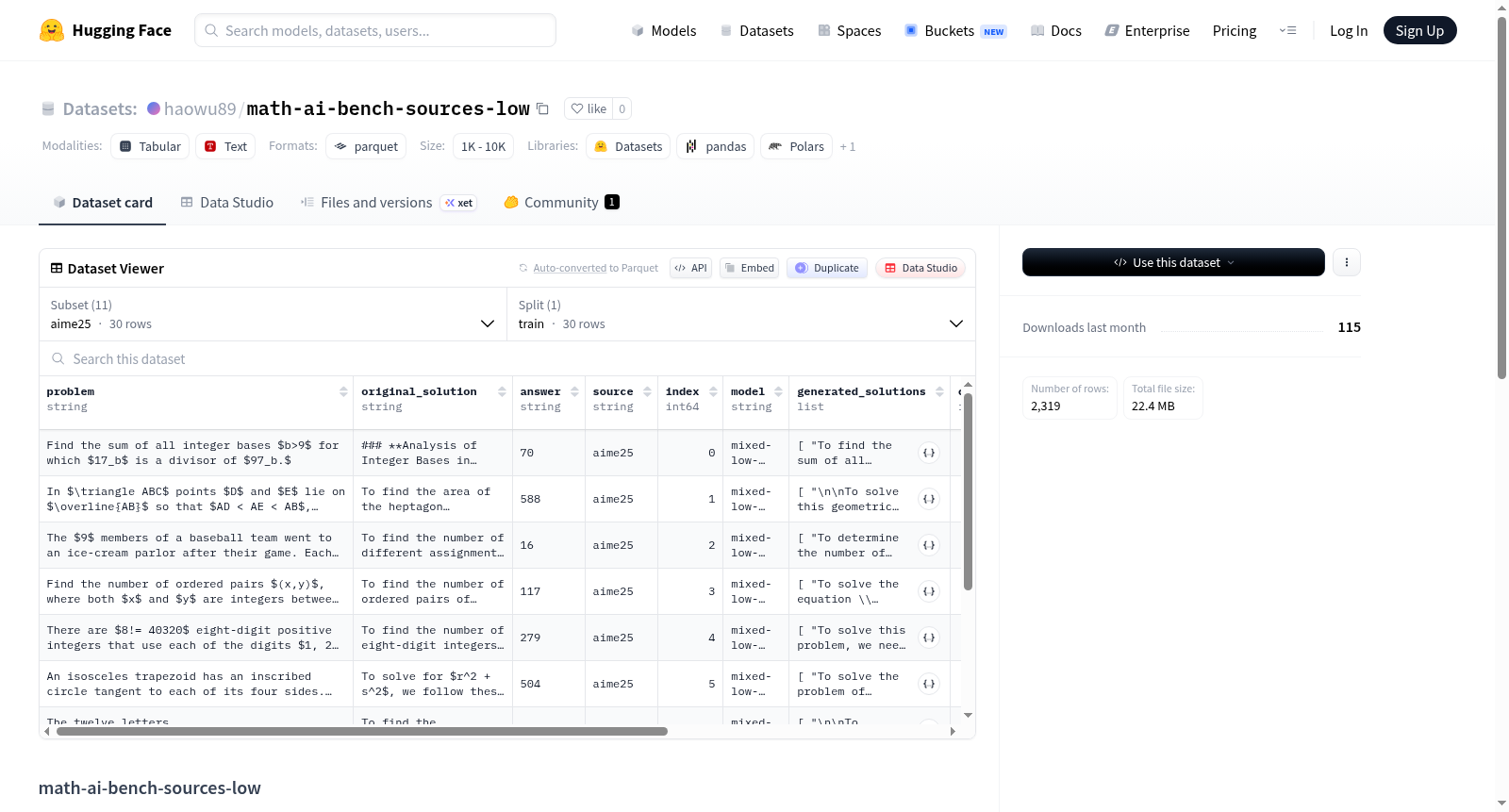
该数据集名为 math-ai-bench-sources-low,是从 haowu89/math-ai-bench-sources-final 中提取的问题级别子集集合。每个数据条目包含一个基准问题及其8个选定的推理轨迹。数据集包含多个配置,每个配置代表不同的数学问题子集或来源。数据字段包括问题描述、原始解决方案、答案、来源、索引、模型标识、生成的解决方案列表(8个轨迹)、计数以及上下文元数据(如正确性标签、令牌计数、来源模型和轨迹索引等)。适用场景包括数学问题求解、AI推理能力评估及相关研究。
This dataset, designated as math-ai-bench-sources-low, is a collection of question-level subsets extracted from the repository haowu89/math-ai-bench-sources-final. Each data entry contains one benchmark problem along with 8 selected inference trajectories. The dataset offers multiple configurations, with each configuration corresponding to a distinct subset or source of mathematical problems. The data fields encompass problem description, original solution, final answer, source identifier, index, model ID, generated solution list (comprising 8 trajectories), count, and contextual metadata including correctness labels, token counts, source models, trajectory indices, and more. Its applicable scenarios cover mathematical problem-solving, AI reasoning capability assessment, and relevant academic research.
创建时间:
2026-04-16
原始信息汇总
数据集概述:math-ai-bench-sources-low
该数据集是基于 haowu89/math-ai-bench-sources-final 构建的问题级子集,每个数据行保留一个基准问题及其8条精选的推理轨迹。
数据集构成
数据集包含11个可配置的子集(configs),每个子集对应一个不同的数学竞赛或基准来源:
- aime25(30条示例)
- aime26(30条示例)
- apex_2025(12条示例)
- arxivmath(72条示例)
- cmimc_2025(40条示例)
- gpqa_diamond(198条示例)
- hmmt_feb_2026(33条示例)
- hmmt_nov_2025(30条示例)
- imobench(400条示例)
- olympiadbench(674条示例)
- theoremqa(800条示例)
所有子集均只包含一个 train 分割。
数据字段
每条记录包含以下字段:
- problem(string):数学问题文本
- original_solution(string):原始标准解答
- answer(string):最终答案
- source(string):问题来源标识
- index(int64):问题索引
- model(string):混合质量桶标识符
- generated_solutions(list of string):8条精选的推理轨迹
- count(int64):固定值为8
- context_metadata(struct):包含以下子字段的元数据结构
- correctness(list of bool):每条轨迹的正确性标签
- cot_num_token(list of int64):每条轨迹的思考链令牌数
- num_correct(int64):正确轨迹数量
- num_wrong(int64):错误轨迹数量
- source_candidate_count(int64):候选来源数量
- source_models(list of string):选用的来源模型列表
- source_traj_indices(list of int64):选用的来源轨迹索引
- total_num_token(int64):所有轨迹的总令牌数
数据集规模
- 总示例数:2,319条
- 总下载大小:约22.4 MB
- 总数据集大小:约49.3 MB
搜集汇总
数据集介绍
构建方式
在数学推理与人工智能交叉研究的前沿领域,高质量基准数据集的构建至关重要。math-ai-bench-sources-low数据集源于更广泛的`haowu89/math-ai-bench-sources-final`精选,通过从每个数学问题中筛选出8条经过验证的推理轨迹,构建了细粒度的子集。这些轨迹源自多样化的语言模型,每条均附带有正确性标签、模型来源及轨迹索引等元数据。数据集共涵盖11个子配置,包括AIME、HMMT、IMO Bench、OlympiadBench、TheoremQA等国内外顶级数学竞赛与学术基准,确保了来源的权威性与多样性。每个配置均以训练集形式组织,数据规模从数十到近千条问题不等,结构紧凑且易于集成。
使用方法
本数据集的使用灵活且高效,兼容HuggingFace Datasets库的标准加载方式。用户可通过指定配置名称(如`aime25`或`theoremqa`)来单独加载对应子集,所有配置均提供训练集。每条数据以字典形式返回,包含`problem`、`generated_solutions`(长度为8的列表)及详细的`context_metadata`。借助`context_metadata`中的正确性标签与token长度,用户可快速过滤出正确或错误的轨迹,用于训练判别模型或进行推理质量分析。该数据集尤其适用于对比不同模型的推理策略、评估思维链的多样性,或作为微调大型语言模型在数学领域表现的高质量训练数据源。
背景与挑战
背景概述
数学推理能力是衡量人工智能系统认知水平的关键维度,近年来,随着大语言模型的快速发展,如何准确评估其在复杂数学问题上的表现成为研究焦点。math-ai-bench-sources-low数据集正是在这一背景下应运而生,它从haowu89/math-ai-bench-sources-final中精心筛选出低质量或具有挑战性的数学推理轨迹,旨在为模型在竞赛级数学问题上的薄弱环节提供针对性评测。该数据集涵盖了AIME、HMMT、IMO Bench、OlympiadBench、TheoremQA等十余个国际知名数学竞赛与学术基准,每个问题均配有多条由不同模型生成的推理链及正确性标注。创建者通过对多种源模型的推理轨迹进行结构化整理,构建了一个能够深入剖析模型错误模式与推理瓶颈的评测资源。该数据集对推动数学推理评测的精细化、探索模型在极限数学任务上的能力边界具有重要意义。
当前挑战
该数据集所解决的核心领域挑战在于,现有数学推理评测多聚焦于模型能否给出正确答案,却较少关注推理过程的多样性与错误分布。具体而言,竞赛级数学问题(如AIME、IMO)本身具有极高难度,模型往往难以直接求解,需要依赖多步逻辑推理与创造性的解题策略,这为公正评估带来了显著困难。在构建过程中,挑战同样严峻:首先,从海量源数据中筛选出低质量轨迹需要设计精细的评判标准,避免因单一指标而误判;其次,确保每个问题恰好保留8条代表性轨迹,并平衡不同模型来源的覆盖度,以防止评测偏向特定模型;最后,对轨迹进行上下文元数据(如token数量、正确性标签)的规范化标注,以支持后续的细粒度错误分析。这些挑战的克服使得数据集能够更客观地揭示模型在复杂数学推理中的真实缺陷。
常用场景
经典使用场景
在人工智能与数学推理的交汇领域,math-ai-bench-sources-low数据集为评估和提升大语言模型的数学解题能力提供了精雕细琢的测试基准。它汇聚了来自AIME、CMIMC、HMMT等国际数学竞赛以及arXiv数学论文、TheoremQA等多元来源的高质量题目,每道题均配备8条精选的推理轨迹。该数据集最经典的用途在于对语言模型的多步推理、符号操作与逻辑演绎能力进行细致入微的剖析,通过对比模型生成的解决方案与标准答案,研究者能够系统性地审视模型在复杂数学问题上的表现优劣。
解决学术问题
该数据集的核心价值在于破解大语言模型在数学推理领域面临的‘黑箱困境’。它帮助学术界深入探究模型在竞赛级数学问题上的推理一致性、错误模式与泛化边界,从而推动从经验性评估向诊断性分析的范式转变。通过记录正确与错误的推理轨迹,研究者可以量化模型在解题过程中的逻辑断裂点,为开发更具鲁棒性的推理架构提供实证依据。这一数据集的意义在于将数学推理研究从简单的答案匹配提升至对思维链质量的整体把握,为认知科学与人工智能的交叉研究开辟了新路径。
实际应用
在实际应用中,math-ai-bench-sources-low数据集成为构建智能教育辅导系统的关键技术支撑。它可以用于训练能够逐步解释数学解题过程的AI导师,帮助学生在竞赛训练中获得个性化的解题指导。此外,该数据集的推理轨迹信息还可服务于自动化竞赛评分系统,使机器能够精确识别学生解题步骤中的错误节点,提供针对性的订正建议。在工业级应用中,它被用于强化语言模型在金融建模、科学计算等需要严谨数学推理的垂直领域的表现能力。
数据集最近研究
最新研究方向
该数据集聚焦于数学推理领域的高难度基准测试,汇集了来自AIME、GPQA、IMO等顶尖赛事的竞赛级题目,并针对每道问题精心筛选了8条高质量的大模型推理轨迹。当前研究前沿正围绕如何利用这些结构化数据,在大语言模型中实现从自然语言理解到符号演算的深度对齐,推动模型在数学奥林匹克等极端复杂场景下的零样本泛化能力。随着竞赛级数学推理成为衡量AI认知水平的标尺,math-ai-bench-sources-low通过提供带细粒度元信息(如正确性标签、推理路径长度)的标准化子集,为破解大模型在逻辑严谨性与计算效率间的权衡困境提供了关键基准,其意义在于加速诞生具备人类级数学直觉的下一代推理引擎。
以上内容由遇见数据集搜集并总结生成


