Diagram Image-Caption Dataset
收藏arXiv2025-05-26 更新2025-05-28 收录
下载链接:
http://arxiv.org/abs/2505.19944v1
下载链接
链接失效反馈官方服务:
资源简介:
本研究构建了一个名为“Diagram Image-Caption Dataset”的人工合成数据集,包含10万对图像和文本描述。数据集旨在消除文本和位置偏置,以便视觉模型能够学习到图像中的边缘特征。该数据集是通过从随机生成的有向图中生成图像和Mermaid风格的文本描述来构建的。每个样本都配有一张图像和一个文本描述,描述一个包含不同数量字母标签节点的有向图。该数据集用于通过对比学习对CLIP模型进行微调,并在三个任务上进行评估:线性探测、图像检索和图表描述。研究结果证实,消除文本和位置偏置可以促进视觉模型准确识别边缘特征,为提高图表理解能力提供了有希望的道路。
This study constructed a synthetic dataset named "Diagram Image-Caption Dataset", which contains 100,000 pairs of images and text captions. The dataset aims to eliminate text and positional biases, enabling visual models to learn edge features from images. It is constructed by generating images and Mermaid-style text descriptions from randomly generated directed graphs. Each sample consists of an image and a text caption describing a directed graph with nodes labeled with letters of varying quantities. This dataset is used for fine-tuning the CLIP model via contrastive learning, and is evaluated on three tasks: linear probing, image retrieval, and diagram captioning. The research results confirm that eliminating text and positional biases can help visual models accurately identify edge features, paving a promising path for improving diagram understanding capabilities.
提供机构:
株式会社日立制作所, 京都产业大学, 岐阜大学
创建时间:
2025-05-26
搜集汇总
数据集介绍
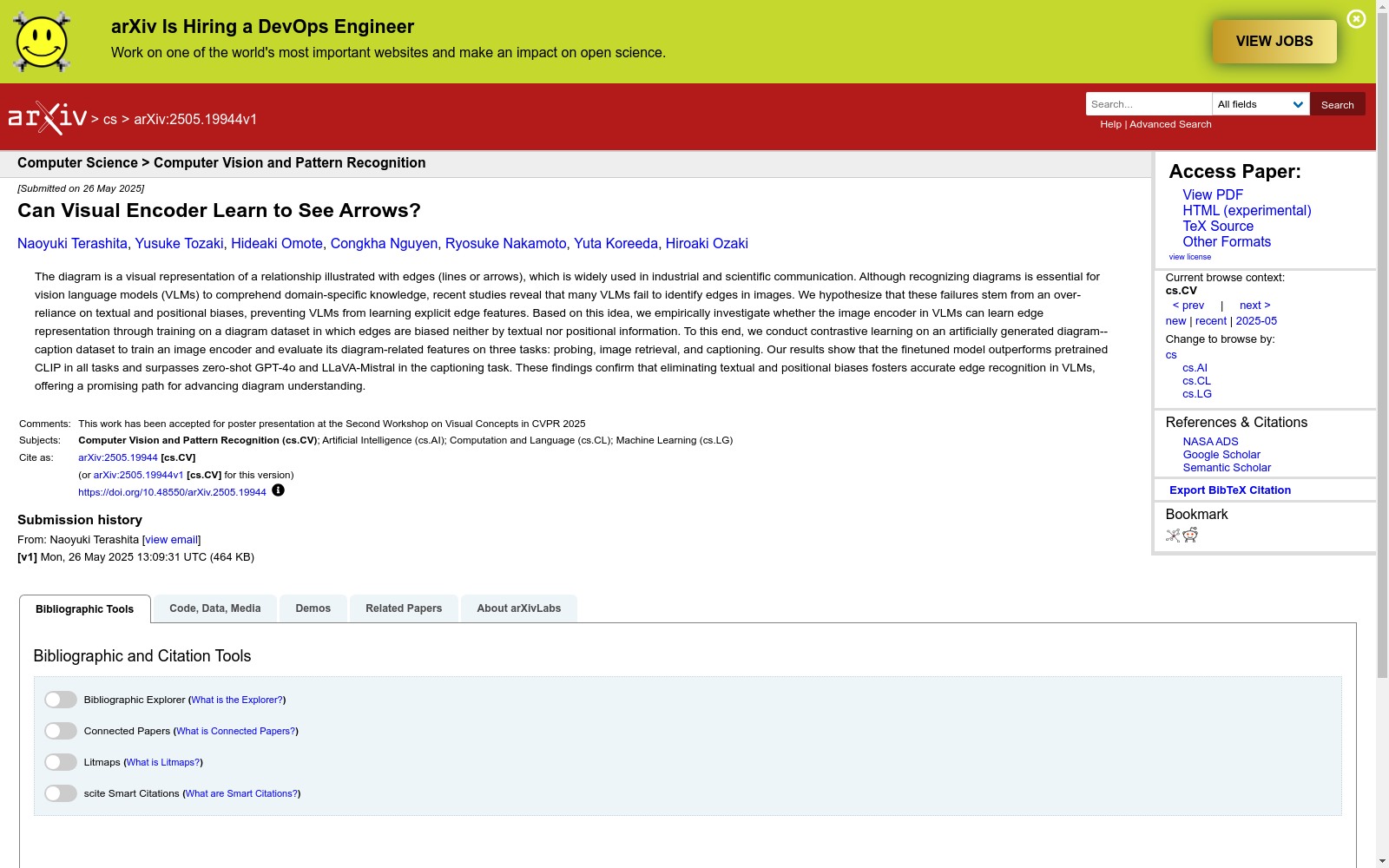
构建方式
Diagram Image-Caption Dataset的构建采用了人工生成的方法,通过随机生成有向图并排除文本和位置偏差,确保数据集的多样性和无偏性。具体而言,数据集包含10万张由力导向布局算法随机生成的图表图像,每张图像配有Mermaid格式的文本描述,描述图中的边和节点关系。测试集占总数据的10%,用于评估模型的泛化能力。
使用方法
数据集的使用方法主要包括对比学习训练和三种评估任务。首先,通过对比学习在生成的图像-文本对上微调CLIP模型,以学习边的视觉表示。随后,通过线性探测、图像检索和图表描述生成三种任务评估模型的性能。线性探测用于分类节点和边的存在及方向,图像检索测试模型对图结构的识别能力,图表描述生成则评估模型生成准确Mermaid格式描述的能力。
背景与挑战
背景概述
Diagram Image-Caption Dataset由Hitachi, Ltd.、Kyoto Sangyo University和Gifu University的研究团队于2025年提出,旨在解决视觉语言模型(VLMs)在识别图表边缘特征方面的不足。图表作为工业与科学交流中广泛使用的视觉表示工具,其边缘(如线条或箭头)的准确识别对VLMs理解领域知识至关重要。然而,现有研究表明,许多VLMs过度依赖文本和位置偏差,导致边缘识别失败。该数据集的构建基于随机生成的有向图,通过消除文本和位置偏差,专注于视觉特征的纯粹学习。其创新性在于通过对比学习微调CLIP模型,显著提升了边缘识别的准确性,为图表理解领域提供了新的研究路径。
当前挑战
Diagram Image-Caption Dataset面临的挑战主要包括两方面:领域问题的挑战与构建过程的挑战。在领域问题方面,现有VLMs难以准确识别图表中的边缘特征,尤其是当缺乏文本或位置线索时,模型性能显著下降。这一挑战的核心在于如何使模型摆脱对文本和位置偏差的依赖,专注于纯粹的视觉特征学习。在构建过程中,挑战在于生成足够多样化的图表图像与标题对,同时确保边缘信息无法通过文本或位置推断。此外,评估模型的泛化能力,尤其是在面对训练集中未见的图结构时,也是一个重要挑战。这些挑战需要通过精细的数据生成策略和创新的模型训练方法来解决。
常用场景
经典使用场景
在计算机视觉与自然语言处理的交叉领域,Diagram Image-Caption Dataset通过消除文本和位置偏差,为视觉语言模型(VLMs)提供了学习边缘特征的理想环境。该数据集广泛应用于对比学习框架中,通过训练图像编码器识别图中的箭头和线条,从而提升模型对复杂图表的理解能力。其经典使用场景包括流程图解析、电子电路图识别以及化学结构图分析,这些场景要求模型准确捕捉节点间的连接关系。
解决学术问题
该数据集解决了视觉语言模型在识别图表边缘时的核心难题,即过度依赖文本和位置信息而忽略视觉特征的问题。通过实验验证,使用该数据集微调的模型在线性探测、图像检索和图表描述任务中显著优于预训练基线,证明了消除偏差对模型学习边缘表征的有效性。这一突破为提升模型在科学图表、工程图纸等专业领域的理解能力提供了理论支持,推动了跨模态推理研究的发展。
实际应用
在实际应用中,该数据集训练的模型可显著提升工业文档自动化处理效率。例如,在医疗领域解析药物分子相互作用图,或在软件工程中自动生成系统架构的Mermaid代码。其核心价值在于将视觉图表转化为结构化描述,辅助知识管理系统构建。此外,该技术还可应用于教育领域,通过自动生成图表说明辅助视障人士理解复杂知识。
数据集最近研究
最新研究方向
在视觉语言模型(VLMs)领域,Diagram Image-Caption Dataset的最新研究方向聚焦于消除文本和位置偏差对边缘特征学习的影响。通过构建无偏差的合成数据集,并结合对比学习方法微调CLIP模型,研究证实了视觉编码器能够有效学习箭头和线条等边缘特征。这一发现不仅提升了模型在节点存在性、边缘存在性及方向分类等线性探测任务中的表现,还在图像检索和图解字幕生成等实际应用中展现出显著优势。该研究为提升VLMs在科学图表理解领域的性能提供了新的思路,同时也揭示了当前大型视觉语言模型在缺乏文本和位置线索时的局限性。
相关研究论文
- 1Can Visual Encoder Learn to See Arrows?株式会社日立制作所, 京都产业大学, 岐阜大学 · 2025年
以上内容由遇见数据集搜集并总结生成


