CancerGUIDE
收藏CancerGUIDE Synthetic Patient Data 数据集概述
数据集基本信息
- 数据集名称: CancerGUIDE Synthetic Patient Data
- 维护方: Microsoft Research
- 语言: 英文
- 许可证: CC BY 4.0
- 相关论文: CancerGUIDE: Evaluating Guideline-Following in Large Language Models for Oncology
- 代码仓库: https://aka.ms/CancerGUIDE
数据集摘要
CancerGUIDE Synthetic Patient Data 包含由GPT-4.1生成的合成肿瘤学患者档案及其推荐治疗方案。该数据集遵循《CancerGUIDE》论文中描述的方法论,采用结构化和非结构化两种生成方式构建。该数据旨在作为评估和训练大语言模型在遵循指南和临床推理任务中的基准。
数据集详情
数据集描述
该数据集由合成的肿瘤学患者记录及相应的治疗建议组成。每条记录包含一个由GPT-4.1生成的合成叙述和一个模型推荐的治疗方案。数据集通过结构化(表格提示模板)和非结构化(自由文本叙述)两种生成流程构建。与真实患者记录和人工标注的评估对比显示,非结构化生成的平均RMSE为0.12,支持了该数据集在下游评估中的有效性。
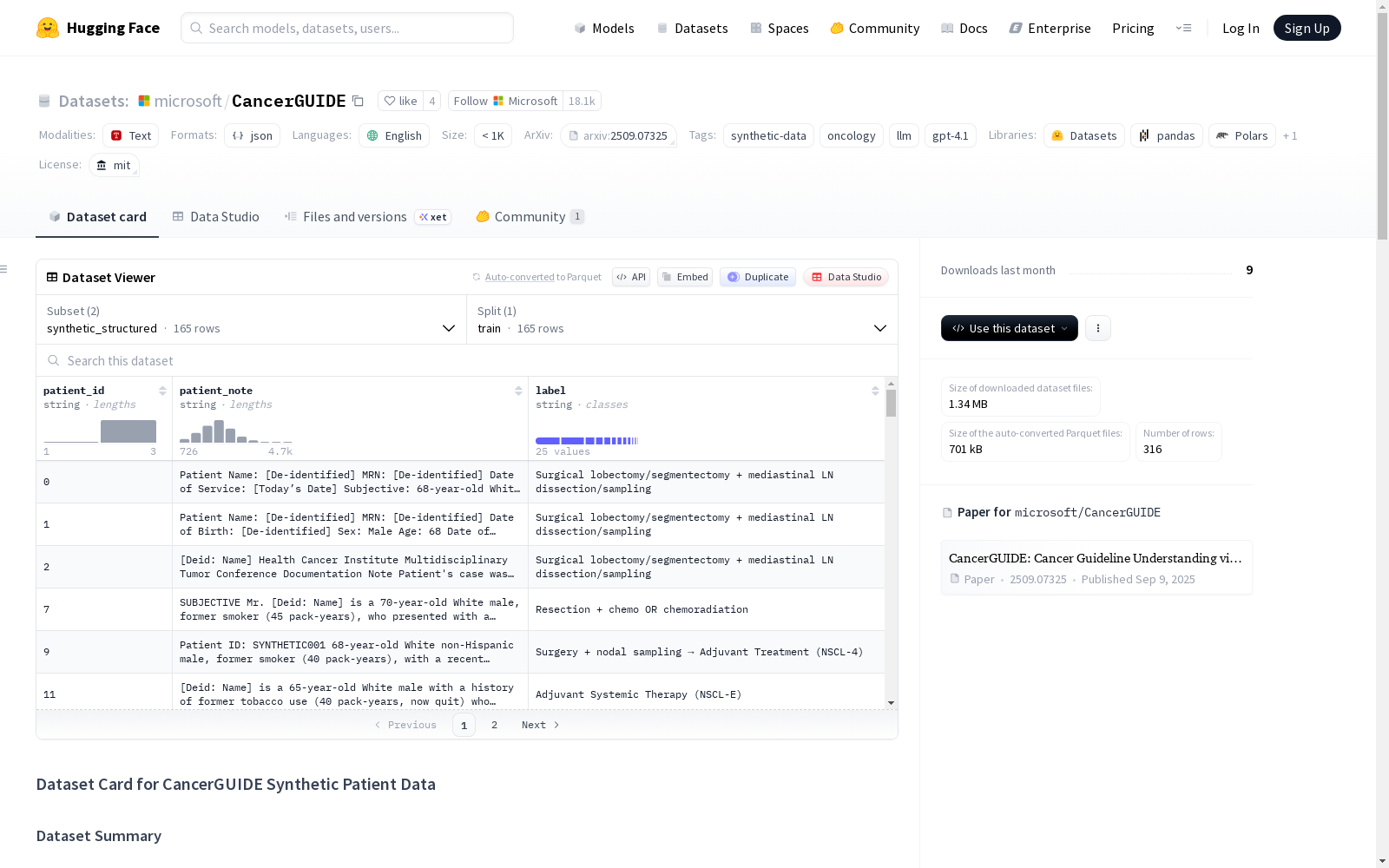
数据集结构
数据集提供两个通过结构化和非结构化方式生成的子集:
- 配置名称:
synthetic_structured- 数据文件:
synthetic_structured.json - 条目数: 165
- 数据文件:
- 配置名称:
synthetic_unstructured- 数据文件:
synthetic_unstructured.json - 条目数: 151
- 数据文件:
每个JSON文件包含一个患者记录列表,格式如下:
patient_id: 唯一的患者标识符patient_note: 对合成患者病史的文本描述label: 模型生成的推荐治疗方案
数据集用途
直接用途
- 评估大语言模型对临床指南的遵循情况
- 训练或微调模型以完成结构化临床推理和推荐任务
- 研究合成患者生成方法
超出范围的用途
- 任何现实世界的临床决策或诊断用途
- 未经在真实临床数据上明确验证即用于生产系统
数据集创建
创建缘由
旨在为研究大语言模型如何解释和应用肿瘤学临床指南提供一个可控的、保护隐私的数据集。
源数据
患者病例是通过GPT-4.1使用模仿真实世界肿瘤学记录和指南结构的提示词合成生成的。未使用任何可识别的真实患者数据。模型输出根据格式和指南一致性标准进行了筛选和验证。
源数据生产者
合成病例由GPT-4.1在受控提示下生成,并由Microsoft Research整理。
个人及敏感信息
该数据集不包含任何个人身份信息或真实的临床数据。所有记录均为完全合成。
偏差、风险与局限性
合成数据可能反映生成模型(GPT-4.1)和提示设计的偏差。未经进一步验证,该数据集不应被用于训练或评估旨在用于真实临床部署的模型。
引用信息
BibTeX: bibtex @dataset{cancerguide_synthetic_2025, title={CancerGUIDE Synthetic Patient Data}, author={Microsoft Research}, year={2025}, note={Synthetic oncology patient dataset generated using GPT-4.1.}, url={https://aka.ms/CancerGUIDE} }
APA: Microsoft Research. (2025). CancerGUIDE Synthetic Patient Data [Dataset]. Retrieved from https://aka.ms/CancerGUIDE