GoodBaiBai88/M3D-VQA
收藏Hugging Face2024-04-25 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/GoodBaiBai88/M3D-VQA
下载链接
链接失效反馈官方服务:
资源简介:
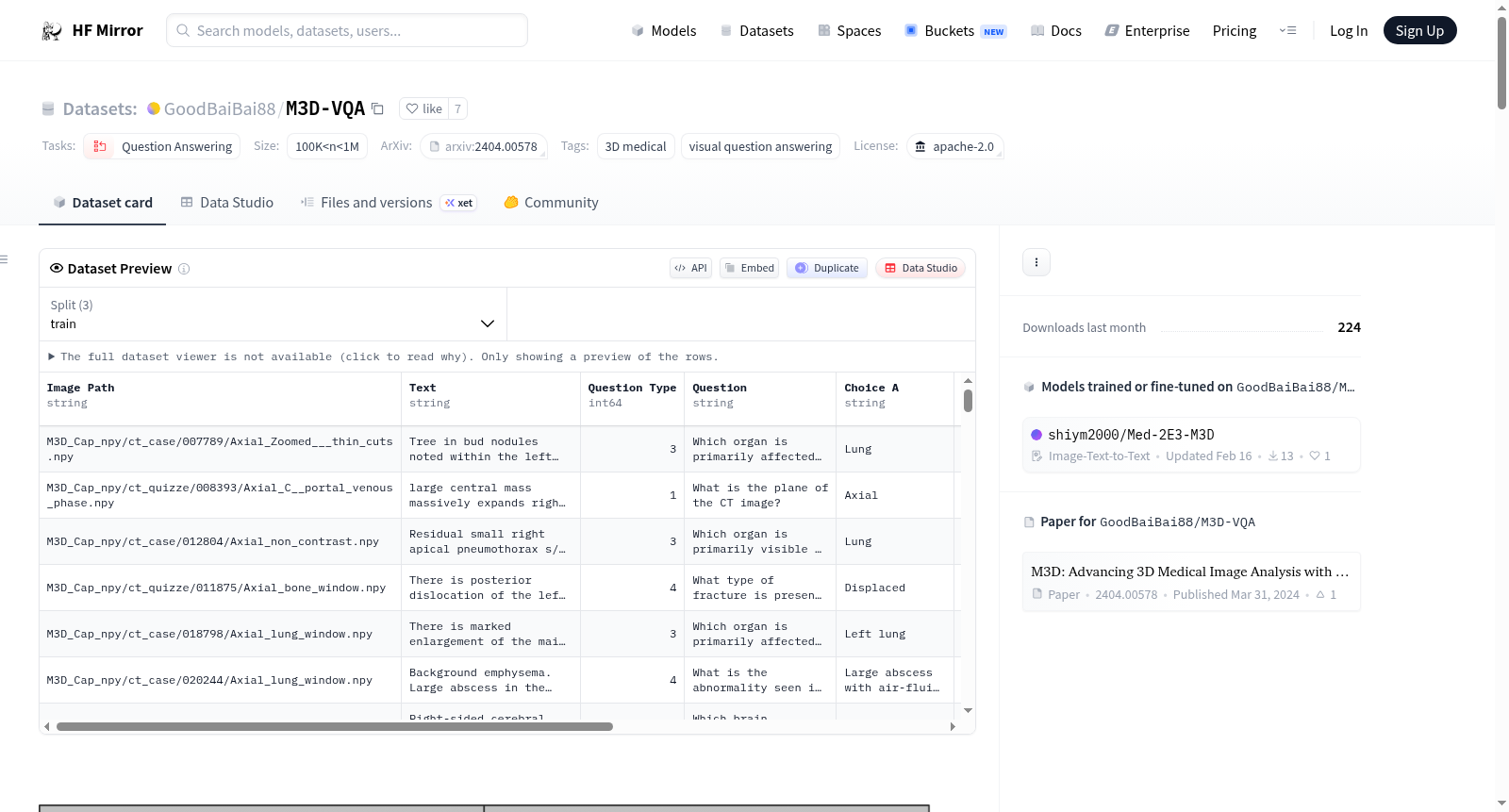
M3D-VQA是一个大规模的3D医学多模态视觉问答数据集,包含510K数据。该数据集通过公开的大型语言模型(LLMs)分析现有诊断报告生成VQA数据,并经过专家和LLMs的验证,确保数据质量。数据集支持开放和封闭式视觉问答任务,数据格式为CSV文件,分为训练集、验证集、测试集和小测试集。图像数据基于M3D-Cap数据集,需要单独下载和配置。
M3D-VQA是一个大规模的3D医学多模态视觉问答数据集,包含510K数据。该数据集通过公开的大型语言模型(LLMs)分析现有诊断报告生成VQA数据,并经过专家和LLMs的验证,确保数据质量。数据集支持开放和封闭式视觉问答任务,数据格式为CSV文件,分为训练集、验证集、测试集和小测试集。图像数据基于M3D-Cap数据集,需要单独下载和配置。
提供机构:
GoodBaiBai88
原始信息汇总
数据集概述
数据集名称
Large-Scale 3D Medical Multi-Modal Dataset - Visual Question Answering Dataset (M3D-VQA)
数据集大小
510K数据
数据集内容
- 图像数据:基于M3D-Cap,需单独下载和配置。
- 问题-答案数据:存储为CSV文件,包括:
- M3D_VQA_train.csv
- M3D_VQA_val.csv
- M3D_VQA_test.csv
- M3D_VQA_test5k.csv(小型测试集)
数据集生成方法
使用公开的大型语言模型(LLMs)分析现有诊断报告,生成VQA数据,并通过预定义规则去除噪声数据。测试集由LLMs和专家审核,通过率为99.4%。
数据集支持的任务
支持3D医学场景下的开放式和封闭式视觉问答等多模态任务。
数据集格式
- 图像数据:需从M3D-Cap下载。
- 问题-答案数据:CSV格式,分为训练、验证、测试和小型测试集。
数据集下载和加载
- 下载方式:可通过Git克隆、SDK加载或手动下载。
- 加载方法:提供Python代码示例,用于构建和加载数据集。
数据集版权和使用
- 版权归属:作者团队所有。
- 使用限制:支持学术研究,商业使用需授权。
引用信息
BibTeX @misc{bai2024m3d, title={M3D: Advancing 3D Medical Image Analysis with Multi-Modal Large Language Models}, author={Fan Bai and Yuxin Du and Tiejun Huang and Max Q. -H. Meng and Bo Zhao}, year={2024}, eprint={2404.00578}, archivePrefix={arXiv}, primaryClass={cs.CV} }
搜集汇总
数据集介绍
构建方式
在医学视觉问答领域,高质量标注数据的稀缺性构成了显著挑战,主要源于专业知识的严苛要求。为应对这一难题,M3D-VQA数据集创新性地采用大型语言模型对公开的医学诊断报告进行深度解析,自动化生成涵盖五个核心主题的多选题对,包括成像平面、扫描时相、解剖器官、异常发现及病灶位置。生成过程中,通过预设规则对噪声数据进行清洗,并进一步由专家与模型联合对测试集进行双重校验,确保了高达99.4%的数据准确率,从而在控制成本的同时保障了数据的专业可靠性。
特点
该数据集作为大规模三维医学多模态资源,其突出特点在于囊括了超过51万条数据,规模宏大。数据以多选题形式组织,巧妙兼容开放式与封闭式两种评估范式,为模型能力提供了多维度的检验标准。数据集紧密依托于M3D-Cap的图像资源,实现了文本问答与三维体素数据的有机联动,构建了真正的多模态交互场景。此外,其提供的精简版测试集便于研究者进行快速原型验证与迭代,体现了设计上的实用性与灵活性。
使用方法
使用该数据集需先行配置M3D-Cap中的三维医学图像数据。问答文本数据以CSV格式存储,包含训练集、验证集、完整测试集及一个五千条样本的快速测试集,用户可通过Hugging Face的`datasets`库直接加载,或手动下载文件。数据加载过程涉及自定义数据集类,该类负责读取CSV、加载对应的图像体素数据,并依据评估模式(封闭式或开放式)对问题和答案进行格式化处理与分词。图像数据可施加随机旋转、翻转等增强变换以提升模型鲁棒性,最终输出图像张量、分词后的文本ID及标签,以供多模态模型进行端到端的训练与评估。
背景与挑战
背景概述
在医学影像分析领域,三维视觉问答(VQA)任务因其能够结合视觉信息与自然语言理解而备受关注,然而高质量标注数据的稀缺严重制约了该方向的发展。M3D-VQA数据集由研究团队于2024年创建,旨在构建一个大规模的三维医学多模态视觉问答资源,包含约51万条数据。该数据集基于M3D-Cap的影像数据,利用大型语言模型分析现有诊断报告自动生成问答对,涵盖平面、相位、器官、异常与位置五大核心医学主题,有效支持开放式与封闭式评估,为三维医学多模态大模型的研究提供了关键数据基础,显著推动了医学影像与自然语言处理交叉领域的进步。
当前挑战
M3D-VQA数据集致力于解决三维医学影像视觉问答这一复杂任务,其核心挑战在于如何精准理解三维体数据中的解剖结构与病理特征,并生成符合医学逻辑的答案。构建过程中,团队面临多重困难:医学专业知识依赖性强,标注成本极高;利用大型语言模型生成数据时,需设计严谨规则以滤除噪声,确保问答对的临床准确性;测试集虽经专家与模型双重验证达到99.4%的通过率,但如何保证生成问题的多样性与全面性仍具难度;此外,数据格式需兼顾开放与封闭评估需求,增加了设计与处理的复杂性。
常用场景
经典使用场景
在医学影像分析领域,三维视觉问答任务对模型的跨模态理解能力提出了严峻挑战。M3D-VQA数据集以其大规模、高质量的标注特性,成为评估和训练多模态大语言模型在三维医学影像中执行视觉问答任务的经典基准。研究者通常利用该数据集进行封闭式与开放式问答的对比实验,通过输入三维医学影像及相关问题,模型需从多个选项中识别正确答案或生成自由文本回答,从而系统检验模型对影像平面、相位、器官、异常及位置等多维度医学概念的融合与推理能力。
实际应用
在实际临床与教育场景中,M3D-VQA数据集支撑着智能诊断辅助系统的开发与优化。基于该数据集训练的模型能够协助放射科医生进行影像解读,通过问答交互快速定位病灶、识别器官与病变类型,提升诊断效率与一致性。在医学教育领域,它可用于构建自适应问答系统,帮助医学生或培训医师深入学习三维影像的解剖结构与病理特征,实现个性化、交互式的技能训练,从而弥合医学理论知识与影像实践之间的鸿沟。
衍生相关工作
围绕M3D-VQA数据集,已衍生出一系列聚焦于三维医学多模态理解的前沿研究工作。例如,其基础论文《M3D: Advancing 3D Medical Image Analysis with Multi-Modal Large Language Models》系统阐述了数据构建方法与多模态模型框架。后续研究常以此数据集为基准,探索如何将视觉编码器、大语言模型与三维医学影像特征进行更有效的融合,或开发针对医学领域的指令微调与推理优化技术,这些工作共同推动了三维医学视觉问答模型性能的持续提升与临床适用性的拓展。
以上内容由遇见数据集搜集并总结生成


