CATER
收藏arXiv2020-04-05 更新2024-06-21 收录
下载链接:
http://rohitgirdhar.github.io/CATER
下载链接
链接失效反馈官方服务:
资源简介:
CATER数据集由卡内基梅隆大学创建,专注于视频中的组合动作和时间推理分析。该数据集包含5500个合成渲染的视频,每个视频长度为10秒,使用标准的3D对象库生成,旨在测试模型对长期时间推理的能力。CATER不仅是一个具有挑战性的数据集,还提供了丰富的诊断工具,用于分析现代视频架构。数据集的应用领域包括动作识别、组合动作识别和目标跟踪等,旨在解决视频理解中的复杂时间推理问题。
The CATER dataset was created by Carnegie Mellon University, focusing on compositional action and temporal reasoning analysis in videos. This dataset contains 5,500 synthetically rendered videos, each with a duration of 10 seconds, generated using standard 3D object libraries, and is designed to test models' capabilities for long-term temporal reasoning. Beyond being a challenging dataset, CATER also provides rich diagnostic tools for analyzing modern video architectures. The application areas of the dataset include action recognition, compositional action recognition, object tracking and other fields, aiming to solve complex temporal reasoning problems in video understanding.
提供机构:
卡内基梅隆大学
创建时间:
2019-10-11
搜集汇总
数据集介绍
构建方式
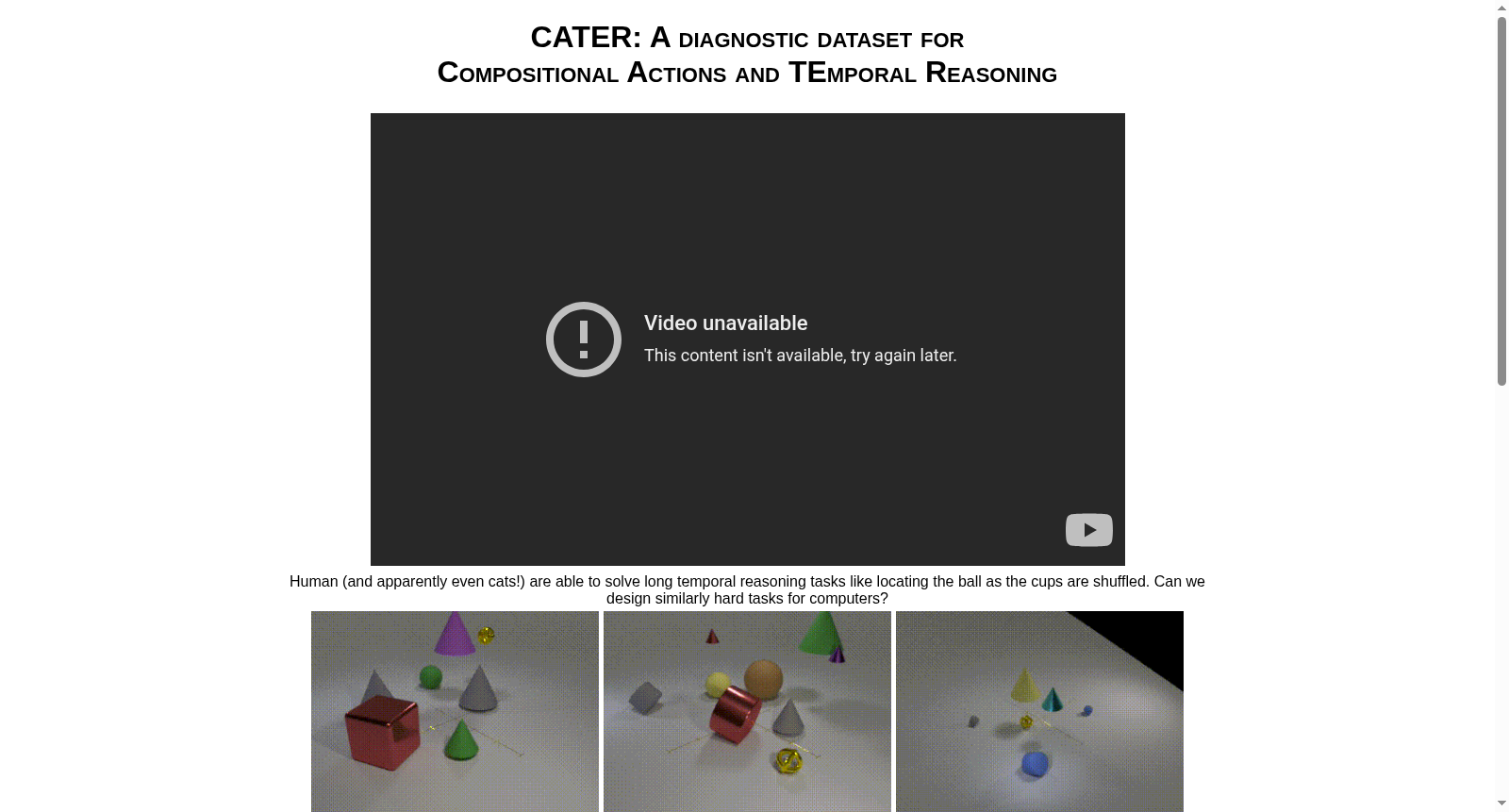
在视频理解领域,现有数据集常受场景与物体结构隐含偏差的困扰,难以有效评估时空推理能力。CATER数据集通过合成渲染技术构建,采用标准三维物体库生成动态桌面场景视频。每个视频以300帧、每秒24帧的格式渲染,分辨率设定为320x240像素,确保与主流视频基准的可比性。数据生成过程严格控制物体参数与动作时序,初始场景随机生成包含特定数量物体的布局,并确保每个视频均包含关键物体如Snitch和锥体。动作被分配在30帧的时间槽内,通过随机顺序添加以避免碰撞,从而构建出需要长期时空推理的复杂组合动作序列。
特点
CATER数据集的核心特点在于其完全可观测与可控的生成机制,有效消除了传统视频数据中常见的场景与物体偏差。数据集包含三种渐进式复杂度的任务:原子动作识别、组合动作识别以及对抗性目标跟踪。这些任务要求模型进行精细的时空推理,特别是在遮挡与包含关系下追踪Snitch物体的位置。数据集提供静态与动态摄像机两种视角,并附带完整的元数据,支持从分类到检测、跟踪等多种结构化预测任务。其合成性质使得数据规模与复杂度易于扩展,同时为模型诊断提供了丰富的参数控制能力,如遮挡持续时间与摄像机运动程度等。
使用方法
使用CATER数据集时,研究人员可将其应用于视频理解模型的评估与诊断。数据集以标准分类任务形式组织,支持单标签或多标签设置,便于现有模型的直接迁移。对于原子与组合动作识别任务,采用多标签分类框架,以平均精度均值(mAP)作为评估指标;Snitch定位任务则通过将空间网格量化为36个单元,以分类准确度进行衡量。数据集中提供的完整元数据允许用户进行更复杂的结构化预测,如时空动作定位与物体跟踪。此外,通过调整生成参数,如物体数量、动作持续时间和摄像机运动,可深入分析模型在特定场景下的行为,为时空推理能力提供细粒度诊断。
背景与挑战
背景概述
视频理解领域在深度学习推动下虽取得显著进展,但多数研究聚焦于静态图像分析,动态视频的时空推理能力仍面临严峻考验。CATER数据集由卡内基梅隆大学与Argo AI的研究团队于2020年提出,旨在构建一个诊断性基准,专门评估模型对组合动作与长时序关系的理解能力。该数据集通过合成渲染技术,在可控场景中模拟物体运动与交互,核心研究问题在于消除传统视频数据中隐含的场景与物体偏差,迫使模型必须依赖时空推理而非单帧信息来完成任务。CATER的推出为视频架构提供了精细的诊断工具,深刻影响了时空建模与组合推理的研究方向。
当前挑战
CATER数据集致力于解决视频理解中组合动作识别与长时序推理的挑战,其核心任务如Snitch定位要求模型在遮挡与包含等复杂情境下追踪目标状态,传统基于帧平均的方法在此表现显著不足。构建过程中的挑战主要体现在合成数据的可控性与真实性平衡:需精确设计物体运动、交互逻辑及时间关系,以模拟真实世界的对抗性任务(如魔术游戏),同时确保数据规模与复杂性可扩展,并为模型诊断提供参数化控制,如相机运动与遮挡时长调整,这些因素共同提升了数据构建的技术门槛与评估深度。
常用场景
经典使用场景
在视频理解领域,CATER数据集作为诊断性工具,专门用于评估模型在动态桌面场景中对组合动作与时间推理的能力。该数据集通过合成渲染生成,包含多种三维物体在二维平面上的运动,如滑动、旋转、拾取放置及包含等原子动作,并设计了复合动作识别与目标追踪任务。其经典使用场景在于测试模型是否能够超越简单的逐帧分析,实现对长期时空关系的理解,例如在物体被遮挡或递归包含的情况下追踪目标位置,从而模拟真实世界中的复杂推理任务,如杯球戏法中的物体追踪。
衍生相关工作
CATER数据集衍生了一系列相关研究,推动了视频推理模型的发展。例如,基于CATER的后续工作探索了更精细的时间关系建模,如使用Allen区间代数进行动作组合分析。同时,该数据集启发了类似合成基准的创建,如CLEVRER(专注于物理因果推理)和PHYRE(针对物理推理的强化学习环境)。在模型架构方面,CATER被用于评估非局部网络和LSTM等时序聚合方法的有效性,促进了如时空图卷积网络等新型架构的优化,以更好地处理长期依赖和遮挡问题。
数据集最近研究
最新研究方向
在视频理解领域,CATER数据集作为一项合成诊断工具,正推动着时空推理模型的前沿探索。该数据集通过可控的合成场景,消除了传统视频数据中对象与场景的隐含偏差,迫使模型必须依赖长期时空关系进行推理。当前研究聚焦于提升模型在遮挡与包含操作下的目标追踪能力,以及复杂动作组合的识别精度。例如,研究者利用LSTM等时序聚合策略增强模型对长程依赖的捕捉,同时探索非局部网络模块以建模动作间的时空交互。这些进展不仅揭示了现有架构在物理推理任务上的局限,也为开发更具鲁棒性的视频理解系统提供了关键洞见。
相关研究论文
- 1CATER: A diagnostic dataset for Compositional Actions and TEmporal Reasoning卡内基梅隆大学 · 2020年
以上内容由遇见数据集搜集并总结生成


