timlawrenz/stratum-ffhq
收藏Hugging Face2026-04-12 更新2026-03-29 收录
下载链接:
https://hf-mirror.com/datasets/timlawrenz/stratum-ffhq
下载链接
链接失效反馈官方服务:
资源简介:
---
license: cc-by-nc-sa-4.0
task_categories:
- image-to-text
- text-to-image
tags:
- stratum-hq
- embeddings
- diffusion
- dataset-enrichment
size_categories:
- 10K<n<100K
---
# stratum-ffhq
Enriched image dataset generated by [stratum-hq](https://github.com/timlawrenz/stratum-hq).
## Dataset Summary
- **Total images**: 70,000
- **Version**: 0.0.192
- **Generated with**: stratum-hq v0.1.0
## Available Layers
| Layer | Count | Format |
|-------|-------|--------|
| caption | 70,000 | parquet |
| depth | 70,000 | npy_tar |
| dinov3 | 1,400 | npy_tar |
| normal | 70,000 | npy_tar |
| pose | 70,000 | npy_tar |
| seg | 70,000 | npy_tar |
| t5 | 70,000 | npy_tar |
## Layer Formats
- **caption**: Included in the main data parquet (`data/`) with `image_id`, `width`, `height`, `aspect_bucket`, and `caption` columns
- **dinov3**: Tar archives with `dinov3_cls.npy` (1024, float16) and `dinov3_patches.npy` (N×1024, float16) per image
- **t5**: Tar archives with `t5_hidden.npy` (512×1024, float16) and `t5_mask.npy` (512, uint8) per image
- **pose**: Tar archives with `pose.npy` (133×3, float16) per image — COCO-WholeBody keypoints in [-1, 1]
- **seg**: Tar archives with `seg.npy` (H×W, uint8) per image — 28-class body-part segmentation (Sapiens)
- **depth**: Tar archives with `depth.npy` (H×W, float16) per image — relative depth, foreground-masked (Sapiens)
- **normal**: Tar archives with `normal.npy` (H×W×3, float16) per image — unit surface normals, foreground-masked (Sapiens)
## Attribution & Provenance
This dataset is a derivative of the **Flickr-Faces-HQ (FFHQ)** dataset by
Tero Karras, Samuli Laine, and Timo Aila (NVIDIA), released under
[Creative Commons BY-NC-SA 4.0](https://creativecommons.org/licenses/by-nc-sa/4.0/).
### What this dataset contains
This dataset provides **pre-computed embeddings, captions, and pose estimates**
derived from the 70,000 aligned face images in FFHQ. It does **not** contain
the original images. To use this dataset you must obtain the original FFHQ
images separately from [NVlabs/ffhq-dataset](https://github.com/NVlabs/ffhq-dataset).
### Changes made to the source material
The following artifacts were generated from each FFHQ image using
[stratum-hq](https://github.com/timlawrenz/stratum-hq):
| Artifact | Description | Model |
|----------|-------------|-------|
| `dinov3_cls.npy` | Global image embedding (1024-d, float16) | DINOv3 ViT-L/16 |
| `dinov3_patches.npy` | Per-patch embeddings (N×1024, float16) | DINOv3 ViT-L/16 |
| `pose.npy` | 133 COCO-WholeBody keypoints (133×3, float16) | DWPose |
| `caption.txt` | Natural-language image description | Gemma 3 27B via Ollama |
| `t5_hidden.npy` | Text encoder hidden states (512×1024, float16) | T5-Large |
| `t5_mask.npy` | T5 attention mask (512, uint8) | T5-Large |
| `seg.npy` | 28-class body-part segmentation (H×W, uint8) | Sapiens-1B |
| `depth.npy` | Relative depth, foreground-masked (H×W, float16) | Sapiens-1B |
| `normal.npy` | Surface normals (H×W×3, float16) | Sapiens-1B |
No original pixel data is distributed in this dataset.
### Caption generation
Captions were generated with
[**Gemma 3 27B**](https://huggingface.co/google/gemma-3-27b-it) served locally
via [Ollama](https://ollama.com/) (`gemma3:27b`). Each image was captioned with
the following system prompt:
> Generate a single, dense paragraph describing this image for a text-to-image
> training dataset. Write in a strictly dry, objective, and descriptive tone.
> Do not use flowery language, subjective interpretations, or lists.
> Describe only what is visible: subject (including specific body build, muscle
> definition, skin texture, and visible anatomical landmarks), precise pose
> (mechanics of limb positioning, hand placement), clothing/accessories, lighting,
> background, composition/framing, and camera angle.
> Do not guess measurements (height, weight) or internal anatomy not visible.
> Do not include any conversational filler, preambles (like 'The image shows...'),
> or meta-commentary. Start the description immediately.
### Example Overlays
The images below illustrate each data layer by overlaying it on a sample face.
These visualizations were generated with
[`scripts/visualize_example.py`](https://github.com/timlawrenz/stratum-hq/blob/main/scripts/visualize_example.py).
| Layer | Overlay |
|-------|---------|
| **Pose** (COCO-WholeBody skeleton) |  |
| **Caption** (Gemma 3 27B) |  |
| **DINOv3** (CLS→patch attention) |  |
| **T5** (token attention mask) | 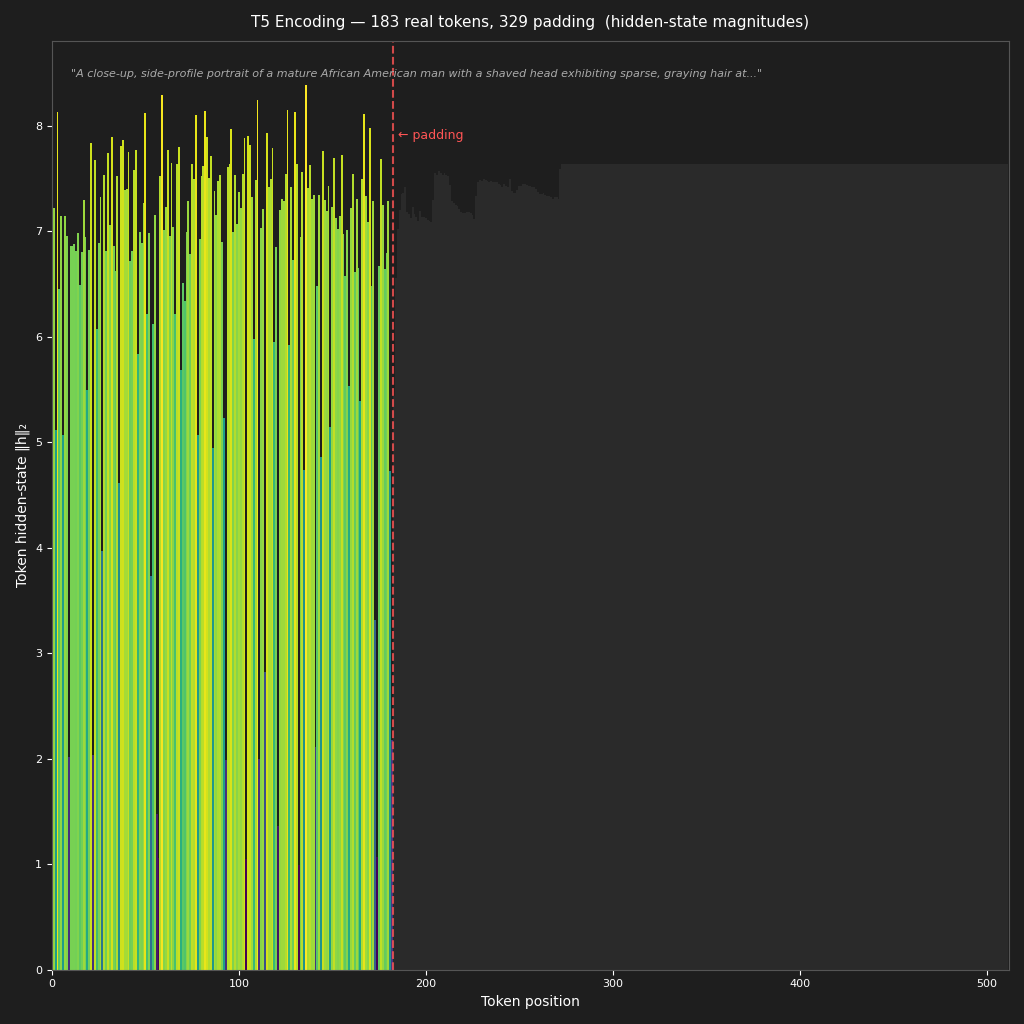 |
| **Segmentation** (Sapiens body parts) |  |
| **Depth** (Sapiens depth estimation) |  |
| **Surface Normals** (Sapiens) |  |
**Combined panel** (all four layers on three diverse FFHQ subjects):
| | | |
|---|---|---|
|  |  |  |
### Per-image licensing
The individual FFHQ images were published on Flickr under one of the following licenses:
- [Creative Commons BY 2.0](https://creativecommons.org/licenses/by/2.0/)
- [Creative Commons BY-NC 2.0](https://creativecommons.org/licenses/by-nc/2.0/)
- [Public Domain Mark 1.0](https://creativecommons.org/publicdomain/mark/1.0/)
- [Public Domain CC0 1.0](https://creativecommons.org/publicdomain/zero/1.0/)
- [U.S. Government Works](http://www.usa.gov/copyright.shtml)
The license and original author of each image are recorded in NVIDIA's official
metadata file **`ffhq-dataset-v2.json`** (255 MB), available from the
[FFHQ dataset repository](https://github.com/NVlabs/ffhq-dataset).
### Citation
If you use this dataset, please cite the original FFHQ paper:
```bibtex
@inproceedings{karras2019style,
title = {A Style-Based Generator Architecture for Generative Adversarial Networks},
author = {Karras, Tero and Laine, Samuli and Aila, Timo},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR)},
year = {2019}
}
```
## Reproduction
```bash
pip install stratum-hq[all]
stratum process ./your-images/ --output ./dataset/ --passes all --device cuda
stratum publish ./dataset/ --hub-repo timlawrenz/stratum-ffhq --layers caption,dinov3,t5,pose,seg,depth,normal
```
license: 知识共享署名-非商业性使用-相同方式共享4.0协议(CC BY-NC-SA 4.0)
task_categories:
- 图像到文本(image-to-text)
- 文本到图像(text-to-image)
tags:
- stratum-hq
- 嵌入(embeddings)
- 扩散模型(diffusion)
- 数据集增强(dataset-enrichment)
size_categories:
- 10000 < 样本数 < 100000
---
# stratum-ffhq
由[stratum-hq](https://github.com/timlawrenz/stratum-hq)生成的增强型图像数据集。
## 数据集概览
- **总样本数**:70000张
- **版本**:0.0.192
- **生成工具**:stratum-hq v0.1.0
## 可用数据层
| 数据层 | 数量 | 格式 |
|-------|-------|--------|
| 图像描述文本 | 70000 | Parquet |
| 深度图 | 70000 | NPY打包(tar) |
| DINOv3嵌入 | 1400 | NPY打包(tar) |
| 表面法向量 | 70000 | NPY打包(tar) |
| 姿态关键点 | 70000 | NPY打包(tar) |
| 语义分割 | 70000 | NPY打包(tar) |
| T5编码器隐藏状态 | 70000 | NPY打包(tar) |
## 数据层格式说明
- **图像描述文本**:包含于主数据Parquet文件(`data/`目录下),包含`"image_id"`、`"width"`、`"height"`、`"aspect_bucket"`与`"caption"`字段
- **DINOv3嵌入**:Tar存档中,每张图像对应`"dinov3_cls.npy"`(形状为(1024,),float16类型)与`"dinov3_patches.npy"`(形状为N×1024,float16类型)
- **T5相关文件**:Tar存档中,每张图像对应`"t5_hidden.npy"`(形状为512×1024,float16类型)与`"t5_mask.npy"`(形状为(512,),uint8类型)
- **姿态关键点**:Tar存档中,每张图像对应`"pose.npy"`(形状为133×3,float16类型)——采用归一化至[-1, 1]区间的COCO-WholeBody关键点
- **语义分割**:Tar存档中,每张图像对应`"seg.npy"`(形状为H×W,uint8类型)——28类身体部位分割结果(基于Sapiens模型)
- **深度图**:Tar存档中,每张图像对应`"depth.npy"`(形状为H×W,float16类型)——相对深度图,已掩码前景区域(基于Sapiens模型)
- **表面法向量**:Tar存档中,每张图像对应`"normal.npy"`(形状为H×W×3,float16类型)——单位表面法向量,已掩码前景区域(基于Sapiens模型)
## 归属与来源
本数据集是由Tero Karras、Samuli Laine与Timo Aila(NVIDIA团队)发布的**Flickr-Faces-HQ(FFHQ)**数据集的衍生作品,采用[知识共享署名-非商业性使用-相同方式共享4.0协议](https://creativecommons.org/licenses/by-nc-sa/4.0/)。
### 本数据集包含内容
本数据集提供了从FFHQ的70000张对齐人脸图像中提取的**预计算嵌入、图像描述文本与姿态估计结果**。本数据集**不包含原始图像文件**。使用本数据集前,您需单独从[NVlabs/ffhq-dataset](https://github.com/NVlabs/ffhq-dataset)获取原始FFHQ图像文件。
### 对源素材的修改内容
以下数据产物均通过[stratum-hq](https://github.com/timlawrenz/stratum-hq)从每张FFHQ图像生成:
| 数据产物 | 描述 | 模型 |
|----------|-------------|-------|
| `"dinov3_cls.npy"` | 全局图像嵌入(1024维,float16类型) | DINOv3 ViT-L/16 |
| `"dinov3_patches.npy"` | 逐块嵌入(N×1024,float16类型) | DINOv3 ViT-L/16 |
| `"pose.npy"` | 133个COCO-WholeBody关键点(133×3,float16类型) | DWPose |
| `"caption.txt"` | 自然语言图像描述文本 | 基于Ollama部署的Gemma 3 27B |
| `"t5_hidden.npy"` | T5编码器隐藏状态(512×1024,float16类型) | T5-Large |
| `"t5_mask.npy"` | T5注意力掩码((512,),uint8类型) | T5-Large |
| `"seg.npy"` | 28类身体部位语义分割结果(H×W,uint8类型) | Sapiens-1B |
| `"depth.npy"` | 相对深度图,已掩码前景区域(H×W,float16类型) | Sapiens-1B |
| `"normal.npy"` | 表面法向量图(H×W×3,float16类型) | Sapiens-1B |
本数据集不分发任何原始像素数据。
### 图像描述文本生成流程
描述文本由[**Gemma 3 27B**](https://huggingface.co/google/gemma-3-27b-it)通过[Ollama](https://ollama.com/)(`gemma3:27b`)本地部署生成。每张图像的生成系统提示词如下:
> 为文本到图像训练数据集生成一段连贯、详尽的图像描述段落。请保持严格客观、平实的描述性语调,切勿使用华丽辞藻、主观解读或列表形式。仅描述可见内容:包括主体(具体体型、肌肉线条、皮肤纹理与可见解剖标志)、精准姿态(肢体摆放的力学结构、手部位置)、服饰与配饰、光照、背景、构图与取景以及拍摄角度。请勿猜测身高、体重等不可见的测量数据或内部解剖结构。请勿添加任何会话性填充语、开场白(如“本图像显示……”)或元评论。请直接开始描述。
### 示例叠加可视化
以下图像展示了将各数据层叠加至样本人脸的效果,这些可视化结果由[`scripts/visualize_example.py`](https://github.com/timlawrenz/stratum-hq/blob/main/scripts/visualize_example.py)生成。
| 数据层 | 叠加效果 |
|-------|---------|
| **姿态关键点**(COCO-WholeBody骨骼) |  |
| **图像描述文本**(Gemma 3 27B生成) |  |
| **DINOv3**(分类向量→块注意力热图) |  |
| **T5**(令牌注意力掩码) |  |
| **语义分割**(Sapiens身体部位分割) |  |
| **深度估计**(Sapiens生成) |  |
| **表面法向量**(Sapiens生成) |  |
**组合面板**(将四层数据叠加至三个不同FFHQ样本的效果):
| | | |
|---|---|---|
|  |  |  |
### 单图像许可协议
每张原始FFHQ图像发布于Flickr平台,采用以下许可协议之一:
- [知识共享署名2.0协议](https://creativecommons.org/licenses/by/2.0/)
- [知识共享署名-非商业性使用2.0协议](https://creativecommons.org/licenses/by-nc/2.0/)
- [公共领域标记1.0](https://creativecommons.org/publicdomain/mark/1.0/)
- [公共领域CC0 1.0协议](https://creativecommons.org/publicdomain/zero/1.0/)
- [美国政府作品](http://www.usa.gov/copyright.shtml)
每张图像的许可协议与原始作者信息记录在NVIDIA官方元数据文件**`ffhq-dataset-v2.json`**(255 MB)中,可从[FFHQ数据集仓库](https://github.com/NVlabs/ffhq-dataset)获取。
### 引用要求
若您使用本数据集,请引用原始FFHQ论文:
bibtex
@inproceedings{karras2019style,
title = {A Style-Based Generator Architecture for Generative Adversarial Networks},
author = {Karras, Tero and Laine, Samuli and Aila, Timo},
booktitle = {Proceedings of the IEEE/CVF Conference on Computer Vision and
Pattern Recognition (CVPR)},
year = {2019}
}
## 数据集复现方法
bash
pip install stratum-hq[all]
stratum process ./your-images/ --output ./dataset/ --passes all --device cuda
stratum publish ./dataset/ --hub-repo timlawrenz/stratum-ffhq --layers caption,dinov3,t5,pose,seg,depth,normal
提供机构:
timlawrenz
搜集汇总
数据集介绍
构建方式
在计算机视觉与生成式人工智能蓬勃发展的背景下,stratum-ffhq数据集作为一项重要的数据增强成果应运而生。该数据集并非从零构建原始图像,而是以著名的Flickr-Faces-HQ (FFHQ) 人脸数据集为基础,通过stratum-hq工具链进行系统化处理与丰富。其构建过程涉及对7万张FFHQ对齐人脸图像进行多模态特征提取,具体包括利用DINOv3模型生成全局与局部图像嵌入,采用DWPose估计133个全身关键点姿态,并借助Sapiens-1B模型计算语义分割、深度图与表面法线。尤为关键的是,数据集通过Gemma 3 27B大语言模型,配合严谨的指令提示,为每张图像生成了客观、密集的文本描述,同时使用T5-Large模型编码文本特征,最终将所有衍生数据以结构化格式封装,形成一套不包含原始像素的、纯特征层面的增强数据集。
特点
该数据集的核心特点在于其多模态、高密度的预计算特征集合。它提供了覆盖视觉、几何与语义等多个维度的数据层,包括图像嵌入、姿态关键点、文本描述、文本隐藏状态、语义分割、深度信息以及表面法线,构成了一个层次丰富的信息体系。这些特征均以高效的数值格式存储,如float16和uint8,兼顾了数据精度与存储效率。数据集严格遵循原始FFHQ的许可协议,并明确区分了源数据与衍生数据,用户需自行获取原始图像以配合使用。这种设计使得stratum-ffhq能够直接服务于需要高质量对齐人脸多模态特征的模型训练与研究,例如扩散模型、图像生成与理解任务,显著降低了特征提取的计算开销与复杂性。
使用方法
在生成模型与多模态学习的研究实践中,stratum-ffhq数据集为开发者提供了即用的高级特征。使用前,用户需首先从官方渠道获取原始的FFHQ图像数据集。本数据集以分层文件形式提供,可通过解析Parquet文件获取图像ID与文本描述,并加载对应的NPY压缩包以读取各类预计算特征。研究人员可以便捷地将这些特征与原始图像配对,直接输入到模型训练流程中,用于提升文本到图像生成的对齐质量、进行基于姿态或语义条件的可控生成,或作为视觉语言模型的训练与评估资源。数据集附带的可视化脚本有助于直观理解各数据层的含义,而完整的复现指令也确保了研究过程的透明性与可重复性。
背景与挑战
背景概述
Stratum-FFHQ数据集是2024年基于NVIDIA研究团队于2019年发布的Flickr-Faces-HQ(FFHQ)数据集构建的增强版本,由Tim Lawrenz等人通过stratum-hq工具生成。该数据集旨在解决生成式人工智能领域,特别是扩散模型与文本到图像合成任务中,对高质量、多模态标注数据的需求。它摒弃了原始像素数据,转而提供了七万张人脸图像的预计算特征,包括DINOv3视觉嵌入、T5文本编码、姿态关键点、语义分割、深度图、法线图以及由Gemma 3 27B模型生成的精细文本描述。这一创新性工作将FFHQ从一个基础的生成对抗网络训练集,扩展为一个支持复杂视觉语言理解和可控生成研究的综合资源,显著提升了数据在模型预训练与微调阶段的实用效率。
当前挑战
该数据集致力于应对图像生成与理解领域中的多模态对齐与可控生成挑战,其核心在于如何精确建立高分辨率人脸图像与结构化语义描述(如姿态、深度、部件分割)及稠密文本标注之间的关联。在构建过程中,挑战主要源于大规模特征提取的复杂性与一致性:需协调多个前沿模型(如DINOv3、DWPose、Sapiens-1B)进行并行处理,确保跨七十万张图像的特征格式统一与计算精度;同时,自动化文本描述生成需遵循严格的客观性指令,避免主观臆测,这对大语言模型的提示工程与输出稳定性提出了极高要求。此外,数据衍生过程完全依赖原始FFHQ图像,用户需独立获取源数据,这在一定程度上增加了使用门槛与合规管理的复杂性。
常用场景
经典使用场景
在计算机视觉与生成式人工智能领域,高质量的人脸图像数据集常被用于训练和评估模型。stratum-ffhq作为FFHQ数据集的增强版本,其经典使用场景集中于为文本到图像生成模型提供丰富的多模态训练数据。研究者可利用其预计算的DINOv3视觉嵌入、T5文本编码以及详细的姿态、分割和深度信息,构建跨模态对齐的表示学习框架,从而提升生成图像在语义一致性和几何准确性方面的表现。
解决学术问题
该数据集有效解决了生成模型研究中数据标注成本高昂与多模态对齐困难的核心问题。通过提供大规模、结构化的预计算特征,如姿态关键点、语义分割和表面法线,它降低了研究者获取高质量监督信号的壁垒。其意义在于为可控图像生成、三维人脸重建以及视觉-语言联合建模等方向提供了标准化的基准数据,推动了这些领域方法论的比较与演进。
衍生相关工作
基于stratum-ffhq衍生的经典工作主要集中在高效的多模态模型预训练与微调策略上。研究者利用其统一的特征表示,开发了融合视觉、文本与几何信息的扩散模型架构,提升了生成内容的可控性与真实性。此外,该数据集也催生了针对人脸属性编辑、姿态引导的图像合成以及跨模态检索等任务的创新方法,成为连接生成模型与具体下游应用的重要桥梁。
以上内容由遇见数据集搜集并总结生成


