ICDAR2017-filtered-1800-1900-6
收藏Hugging Face2024-12-02 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/m-biriuchinskii/ICDAR2017-filtered-1800-1900-6
下载链接
链接失效反馈官方服务:
资源简介:
该数据集是ICDAR2017手写文本识别竞赛的过滤版本,专注于1800至1900年间书写的单字文本。数据集包含957份文档,分为训练、验证和测试集,旨在用于OCR文本的后校正。数据集的目的是通过提供可靠的Ground Truth进行比较和校正,以提高数字化文本的准确性,特别是针对19世纪的法语文本。数据集包含多个列,详细描述了OCR输出及其对应的Ground Truth,包括文件名、日期、OCR识别的区域和句子、对齐的OCR和Ground Truth区域和句子、编辑距离、字符错误率(CER)和单词错误率(WER)等。此外,数据集还包括引入额外错误的OCR句子及其对应的CER和WER,用于合成错误分析。
This is a filtered variant of the ICDAR 2017 Handwritten Text Recognition Competition dataset, focusing on single-word texts written between 1800 and 1900. It consists of 957 documents split into training, validation, and test sets, and is designed for OCR text post-correction. The core objective of this dataset is to improve the accuracy of digitized texts, especially 19th-century French texts, by providing reliable Ground Truth for comparative verification and correction. This dataset includes multiple columns that comprehensively describe OCR outputs and their corresponding Ground Truth, including filenames, dates, OCR-recognized regions and sentences, aligned OCR and Ground Truth regions and sentences, edit distance, Character Error Rate (CER), Word Error Rate (WER), and other relevant metrics. Additionally, the dataset also contains OCR sentences with artificially introduced additional errors paired with their corresponding CER and WER values, for synthetic error analysis.
创建时间:
2024-11-21
原始信息汇总
ICDAR2017-filtered-1800-1900-6 数据集概述
数据集描述
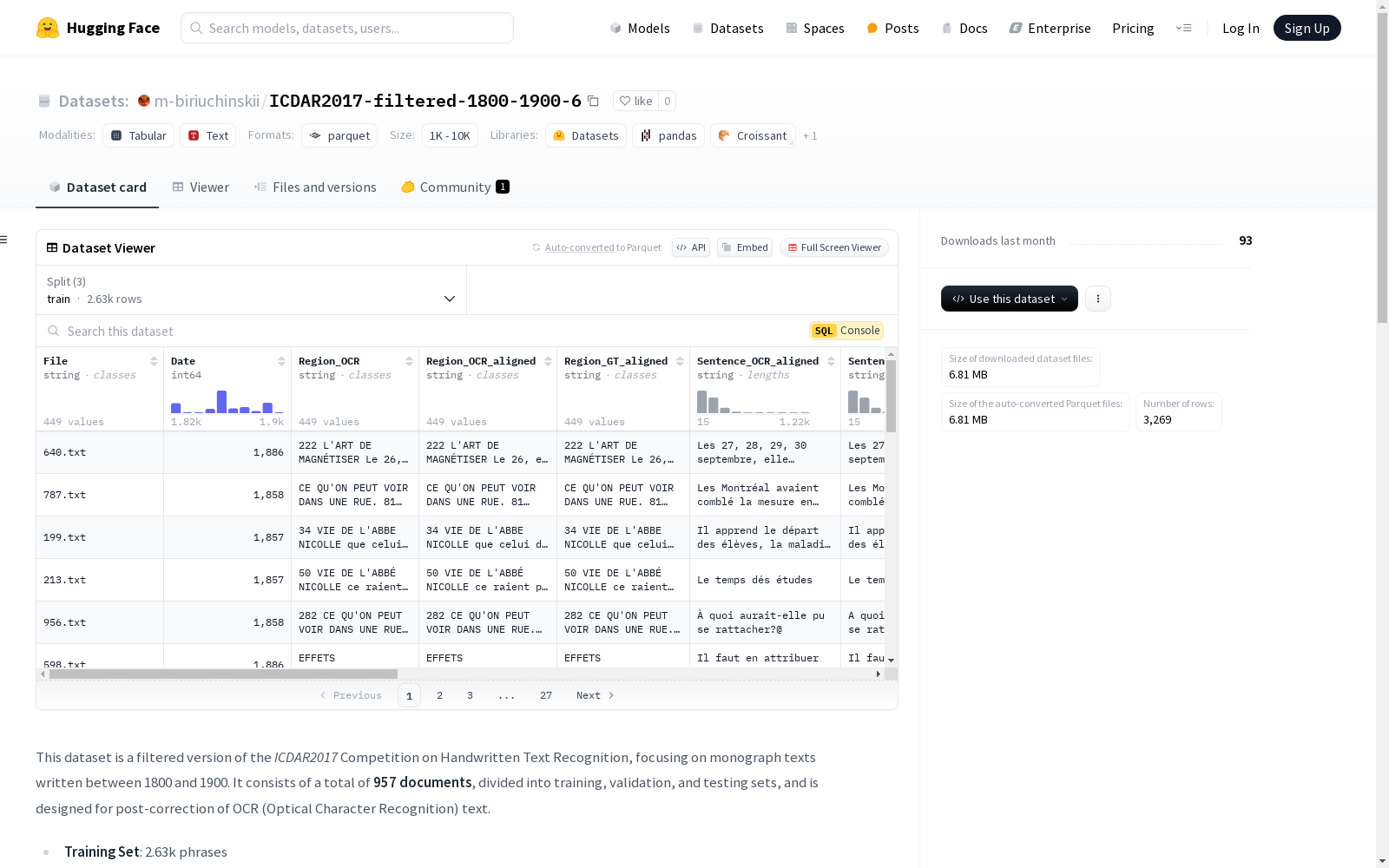
该数据集是ICDAR2017手写文本识别竞赛的过滤版本,专注于1800至1900年间书写的单行文本。数据集包含957份文档,分为训练、验证和测试集,旨在用于OCR(光学字符识别)文本的后校正。
数据集结构
特征列
- File: 文件名或标识符,类型为
string。 - Date: 文档日期,类型为
int64。 - Region_OCR: OCR识别的文本区域,类型为
string。 - Region_OCR_aligned: 对齐后的OCR识别区域,类型为
string。 - Region_GT_aligned: 对齐后的地面真值区域,类型为
string。 - Sentence_OCR_aligned: 对齐后的OCR识别句子,类型为
string。 - Sentence_GT_aligned: 对齐后的地面真值句子,类型为
string。 - Sentence_OCR: 原始的OCR识别句子,类型为
string。 - Sentence_GT: 原始的地面真值句子,类型为
string。 - Distance: OCR句子与地面真值之间的编辑距离,类型为
int64。 - CER: 字符错误率,类型为
float64,范围从0到0.29。 - WER: 词错误率,类型为
float64,范围从0到1.5。 - Sentence_OCR_corrupted: 带有额外错误的OCR句子,用于合成错误分析,类型为
string。 - corrupted_cer: 带有错误的OCR句子的字符错误率,类型为
float64,范围从0到0.35。 - corrupted_wer: 带有错误的OCR句子的词错误率,类型为
float64。
数据分割
- train: 训练集,包含2632个样本,大小为18654472字节。
- dev: 验证集,包含336个样本,大小为2542628字节。
- test: 测试集,包含301个样本,大小为2031987字节。
数据集用途
该数据集旨在通过提供可靠的地面真值进行比较和校正,以提高数字化文本的准确性,特别是针对19世纪的法语文本。
作者信息
由Mikhail Biriuchinskii准备,他是索邦大学自然语言处理领域的工程师。
原始数据集参考
更多信息请访问原始数据集来源:ICDAR2017 Competition on Post-OCR Text Correction。
版权声明
原始语料库是公开可访问的,我不持有该语料库的任何权利。
搜集汇总
数据集介绍
构建方式
该数据集源自ICDAR2017手写文本识别竞赛的筛选版本,专注于1800至1900年间的手写单字文本。数据集由957份文档组成,分为训练、验证和测试集,旨在通过提供可靠的Ground Truth数据来提升OCR文本的后校正精度。训练集包含2632条短语,验证集和测试集分别包含336和301条短语。数据集的构建通过对比OCR识别结果与Ground Truth,计算字符错误率(CER)和词错误率(WER),并引入合成错误以进行更全面的性能评估。
特点
该数据集的显著特点在于其专注于19世纪法语文本的OCR后校正,提供了详细的OCR识别与Ground Truth对比信息。数据集包含多种对齐和未对齐的文本区域及句子,以及计算的编辑距离、CER和WER等指标,便于深入分析OCR性能。此外,数据集还引入了合成错误,以评估模型在处理复杂情况下的表现,增强了其在实际应用中的适用性。
使用方法
该数据集适用于OCR后校正模型的训练与评估,用户可通过提供的训练、验证和测试集进行模型开发。数据集的详细列信息,如对齐与未对齐的OCR和Ground Truth文本、编辑距离、CER和WER等,为模型性能的量化评估提供了丰富的数据支持。此外,合成错误的引入为模型在处理复杂文本时的鲁棒性测试提供了可能,用户可根据具体需求选择合适的子集进行实验。
背景与挑战
背景概述
ICDAR2017-filtered-1800-1900-6数据集是基于ICDAR2017手写文本识别竞赛的筛选版本,专注于1800至1900年间的手写单字文本。该数据集由957份文档组成,分为训练、验证和测试集,旨在通过提供可靠的Ground Truth数据来提升OCR(光学字符识别)文本的准确性,特别是针对19世纪法语文本的校正。该数据集由Sorbonne大学的自然语言处理工程师Mikhail Biriuchinskii准备,其核心研究问题在于通过对比OCR输出与Ground Truth,评估和改进OCR系统的后校正性能。
当前挑战
该数据集面临的挑战主要集中在两个方面:其一,19世纪法语文本的特殊性带来了语言学和字符识别的双重难题,包括古字体、手写风格多样性及语言演变等问题;其二,数据集构建过程中,如何确保OCR输出与Ground Truth的对齐精度,以及如何通过合成错误数据(如Sentence_OCR_corrupted)来模拟和评估OCR系统的鲁棒性,均是技术上的重大挑战。此外,CER和WER的计算需要在不同层次上进行精确校准,以确保评估结果的可靠性。
常用场景
经典使用场景
ICDAR2017-filtered-1800-1900-6数据集的经典使用场景主要集中在光学字符识别(OCR)后文本校正的研究与实践中。该数据集通过提供19世纪法语文本的OCR识别结果及其对应的准确地标数据,使得研究者能够深入分析和改进OCR系统的性能。具体而言,研究者可以利用该数据集进行OCR文本与真实文本的对齐、错误率计算以及基于编辑距离的误差分析,从而优化OCR系统的输出质量。
衍生相关工作
基于ICDAR2017-filtered-1800-1900-6数据集,研究者们开发了多种OCR后处理算法和模型,以提高文本校正的准确性。例如,一些研究工作专注于改进字符错误率(CER)和词错误率(WER)的计算方法,以更精确地评估OCR系统的性能。此外,还有研究者利用该数据集进行深度学习模型的训练,开发出能够自动识别和校正OCR错误的模型,进一步推动了OCR技术在历史文本处理中的应用。
数据集最近研究
最新研究方向
在光学字符识别(OCR)领域,ICDAR2017-filtered-1800-1900-6数据集的最新研究方向主要集中在19世纪法语文本的OCR后校正技术上。该数据集通过提供详细的OCR输出与对应的真实文本(Ground Truth)之间的对比信息,推动了对历史文献数字化精度的提升研究。当前的研究热点包括利用深度学习模型进行自动校正,以及通过引入合成错误数据来增强模型的鲁棒性。这些研究不仅有助于提高历史文献的数字化质量,还为文化遗产的保护与传承提供了技术支持。
以上内容由遇见数据集搜集并总结生成


