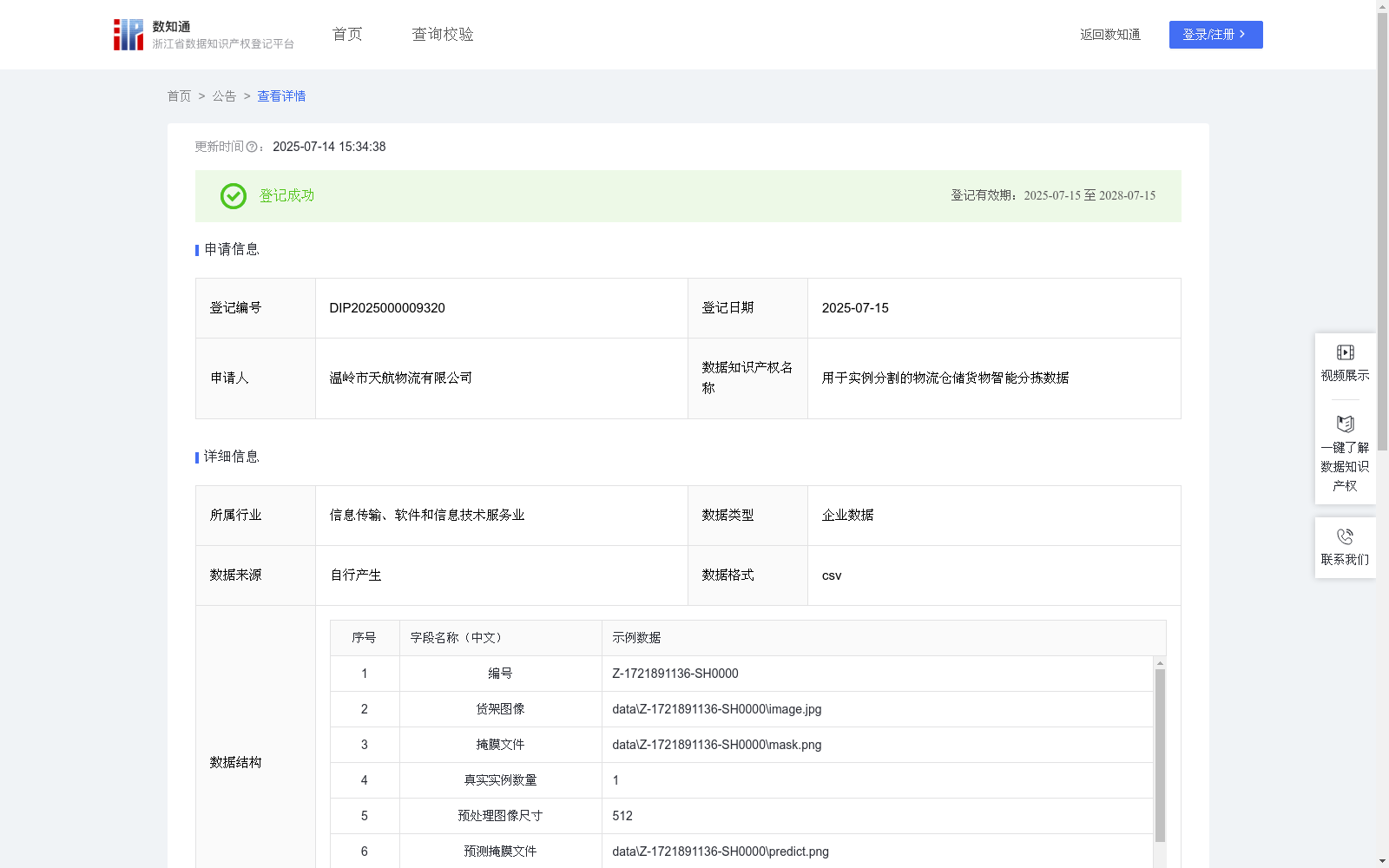
用于实例分割的物流仓储货物智能分拣数据
收藏浙江省数据知识产权登记平台2025-07-14 更新2025-07-15 收录
下载链接:
https://www.zjip.org.cn/home/announce/trends/148609
下载链接
链接失效反馈官方服务:
资源简介:
该数据在仓储货物分拣中具有重要的应用价值。能够提供货物精准定位与掩膜分割,更精确地识别堆叠货物的独立边界,帮助仓储机器人进行自动化抓取与分类。在智能物流仓储中具有广泛的应用场景,特别是电商分拣中心、冷链物流中转站和跨境仓储枢纽,能够提高分拣效率,降低人工误操作率,提供实时货物状态可视化支持。
数据收集:
货物图像:通过固定视角摄像头采集分拣区域原始图像(分辨率1920×1080),覆盖不同光照、堆叠密度的场景。掩码文件:由标注工具对图像中独立货物进行掩膜标注。真实实例数量:统计实际货物数量作为监督标签。预处理图像尺寸(单位为像素):将原始图像缩放至512×512像素以适配模型输入,记录缩放后尺寸作为预处理参数。
数据预处理:
图像归一化:将像素值从[0,255]线性映射至[0,1]区间,公式为:I_normalized = I_raw / 255.0。尺寸标准化:采用双线性插值法统一缩放图像至512×512像素,减少模型计算复杂度。数据增强:随机添加旋转(±15°)和亮度扰动(±20%),提升模型泛化能力。
模型构建:
采用基于Mask R-CNN的实例分割模型,网络结构包含特征提取、区域建议生成(RPN)、掩膜预测三部分。核心公式如下:特征金字塔输出:F = FPN(ResNet(I))。其中,I为预处理后的512×512图像,FPN为特征金字塔网络,输出多尺度特征图F。掩膜损失计算:L_mask = (1/N) * Σ[-y*log(p) - (1-y)*log(1-p)]。其中,y:真实掩膜二值标签(0或1);p:预测掩膜概率值(0~1);N:掩膜区域像素总数。分割精度为预测掩膜和真实掩膜的交并比IoU,单位为%。模型通过分割精度均值(所有货物掩膜IoU的平均值,值域在[0,1]中)和单帧处理时间(从输入图像到输出结果的端到端耗时,单位为秒)评估性能,确保分拣系统同时满足高精度与实时性要求。
This dataset holds significant application value in warehouse cargo sorting. It enables accurate positioning and mask segmentation of cargoes, precisely identifies the individual boundaries of stacked cargoes, and assists warehouse robots in automated grasping and sorting. It has a wide range of application scenarios in intelligent logistics warehousing, especially in e-commerce sorting centers, cold chain logistics transfer stations, and cross-border warehousing hubs, where it can improve sorting efficiency, reduce manual misoperation rates, and provide real-time visualization support for cargo status.
Data Collection:
Cargo Images: Raw images of the sorting area were collected via fixed-angle cameras, with a resolution of 1920×1080, covering scenarios with varying lighting conditions and stacking densities.
Mask Files: Independent cargoes in the images were annotated with masks using annotation tools.
Ground-truth Instance Count: The actual number of cargoes was counted as the supervision label.
Preprocessed Image Size (in pixels): The raw images were resized to 512×512 pixels to fit model input, and the resized dimensions were recorded as preprocessing parameters.
Data Preprocessing:
Image Normalization: Linearly map pixel values from the range [0, 255] to [0, 1], with the formula: $I_{ ext{normalized}} = I_{ ext{raw}} / 255.0$.
Size Standardization: Uniformly resize images to 512×512 pixels using bilinear interpolation to reduce model computational complexity.
Data Augmentation: Randomly apply rotations (±15°) and brightness perturbations (±20%) to enhance model generalization ability.
Model Construction:
An instance segmentation model based on Mask R-CNN is adopted, whose network structure consists of three parts: feature extraction, region proposal network (RPN), and mask prediction. The core formulas are as follows:
Feature Pyramid Output: $F = ext{FPN}( ext{ResNet}(I))$.
Where $I$ is the preprocessed 512×512 image, and FPN is the Feature Pyramid Network that outputs multi-scale feature maps $F$.
Mask Loss Calculation: $L_{ ext{mask}} = (1/N) * sumleft[-y cdot log(p) - (1-y) cdot log(1-p)
ight]$.
Where: $y$ is the ground-truth binary mask label (0 or 1); $p$ is the predicted mask probability value (0~1); $N$ is the total number of pixels in the mask region.
The segmentation accuracy is defined as the Intersection over Union (IoU) between the predicted mask and the ground-truth mask, with the unit of %. The model performance is evaluated using the mean segmentation accuracy (the average IoU of all cargo masks, with a value range of [0, 1]) and the single-frame processing time (end-to-end time from input image to output result, with the unit of second), to ensure that the sorting system meets both high accuracy and real-time performance requirements.
提供机构:
温岭市天航物流有限公司
创建时间:
2025-06-25
搜集汇总
数据集介绍
以上内容由遇见数据集搜集并总结生成


