VECTOREDITS
收藏arXiv2025-06-19 更新2025-06-24 收录
下载链接:
https://huggingface.co/datasets/mikronai/VectorEdits
下载链接
链接失效反馈官方服务:
资源简介:
VECTOREDITS是一个大规模数据集,包含超过27万对SVG图像和自然语言编辑指令。该数据集支持基于文本指令修改矢量图形的模型训练和评估。数据集创建过程包括通过CLIP相似性进行图像配对和利用视觉语言模型生成指令。初始实验表明,当前方法难以产生准确有效的编辑,突显了该任务的挑战性。为了促进自然语言驱动的矢量图形生成和编辑的研究,我们公开了在本次工作中创建的资源。
VECTOREDITS is a large-scale dataset containing over 270,000 pairs of SVG images and natural language editing instructions. This dataset supports the training and evaluation of models for modifying vector graphics based on text instructions. The dataset creation pipeline includes image pairing via CLIP similarity and instruction generation using vision-language models. Preliminary experiments show that existing methods struggle to produce accurate and effective edits, highlighting the challenges of this task. To advance research on natural language-driven vector graphics generation and editing, we publicly release the resources created in this work.
提供机构:
马斯亚克大学信息学院, Kempelen智能技术研究所,赫尔辛基大学语言技术系
创建时间:
2025-06-19
原始信息汇总
VectorEdits数据集概述
数据集基本信息
- 名称: VectorEdits: A Dataset and Benchmark for Instruction-Based Editing of Vector Graphics
- 语言: 英文 (en)
- 标签: svg, editing, dataset, train, eval
- 任务类别: 文本生成文本 (text2text-generation)
- 规模分类: 100K<n<1M
数据集结构
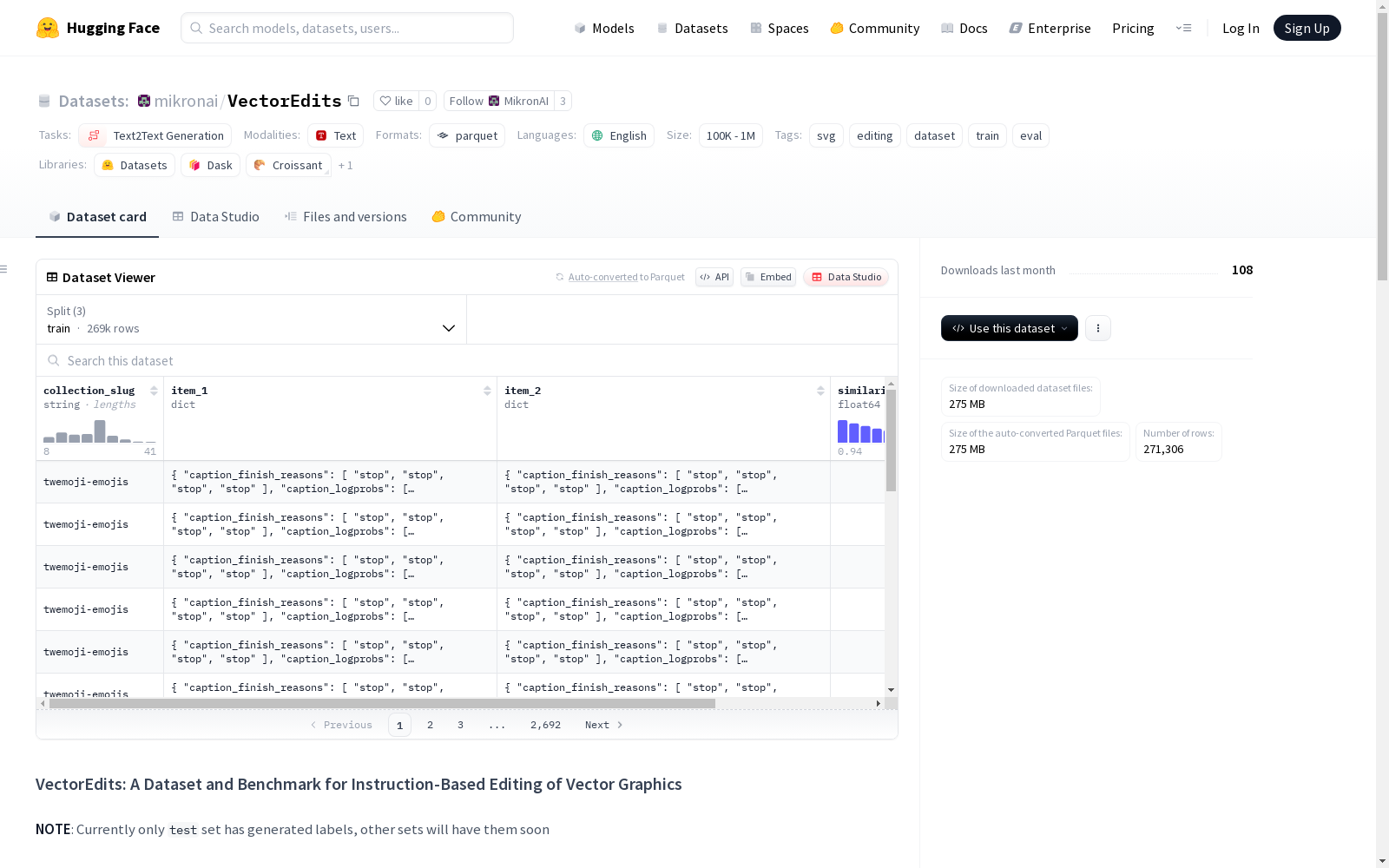
特征
collection_slug: 字符串类型item_1: 结构体类型,包含原始SVG信息caption_finish_reasons: 字符串序列caption_logprobs: 浮点数序列caption_model_name: 字符串序列caption_num_tokens: 整数序列caption_temperature: 浮点数序列caption_texts: 字符串序列collection_id: 整数类型collection_slug: 字符串类型item_id: 整数类型item_license: 字符串类型item_license_link: 字符串类型item_license_owner: 字符串类型item_slug: 字符串类型item_svg: 字符串类型item_tags: 字符串序列item_title: 字符串类型
item_2: 结构体类型,包含编辑后的SVG信息(结构与item_1相同)similarity: 浮点数类型instruction: 字符串类型
数据划分
- 训练集 (train)
- 样本数量: 269,106
- 大小: 2,281,819,762字节
- 验证集 (validation)
- 样本数量: 200
- 大小: 1,214,438字节
- 测试集 (test)
- 样本数量: 2,000
- 大小: 12,718,293字节
数据集用途
- 用于训练和评估基于文本指令修改矢量图形的模型。
数据集来源
- 图像来源: SVG Repo
- 数据收集过程: 通过CLIP相似性进行图像配对,并使用视觉语言模型生成指令。
使用方式
python from datasets import load_dataset dataset = load_dataset("mikronai/VectorEdits")
注意事项
- 目前仅测试集 (
test) 包含生成的标签,其他数据集将很快添加。
搜集汇总
数据集介绍
构建方式
VECTOREDITS数据集的构建过程体现了严谨的科学方法论与创新的技术路径。研究团队从SVG Repo开源矢量图库中精选图像素材,通过CLIP相似度计算在保持风格一致性的前提下,构建了27万余组图像编辑对。采用多模态视觉语言模型Qwen2.5-VL 70B自动生成编辑指令,并通过人工评估确保指令质量。数据集划分采用整组隔离策略,有效避免了风格泄露问题,为模型泛化能力评估提供了可靠基准。
特点
该数据集最显著的特征在于其规模性与任务专属性。作为当前最大的指令引导矢量图编辑数据集,其27万组样本覆盖了从简单属性修改到复杂结构重组的多样化编辑类型。每个样本包含源SVG、目标SVG及自然语言指令的三元组结构,为模型提供了明确的监督信号。特别值得注意的是,数据集通过CLIP相似度阈值控制确保了编辑对的语义关联性,同时维持了矢量图形特有的几何精确性和可扩展性优势。
使用方法
使用该数据集时,研究者可通过标准的训练-验证-测试划分开展模型开发。输入层需同时处理SVG代码和自然语言指令,输出层要求生成符合SVG语法的修改结果。评估阶段建议采用多维度指标:CLIP和DINOv2衡量语义一致性,MSE检测像素级差异,同时需严格检查输出文件的语法有效性。数据集特别适用于研究跨模态理解、程序合成以及几何推理等核心能力在矢量图编辑任务中的融合应用。
背景与挑战
背景概述
VECTOREDITS数据集由马萨里克大学TransformersClub团队于2025年提出,旨在推动基于自然语言指令的矢量图形编辑研究。该数据集包含27万余组SVG图像对及对应编辑指令,填补了矢量图形领域缺乏大规模指令编辑基准的空白。矢量图形作为现代数字内容创作的核心载体,其可缩放、易编辑的特性使其在网页设计、印刷品制作等领域具有不可替代的优势。该数据集的建立为探索多模态模型在几何理解、空间推理和代码生成等复合能力方面提供了重要平台,对降低数字艺术创作门槛具有深远意义。
当前挑战
该数据集面临的核心挑战体现在任务复杂性和数据构建两个维度。在技术层面,指令驱动的矢量编辑要求模型同时具备视觉语义解析、几何关系推理和精确代码生成能力,现有大语言模型在初步实验中未能超越原始图像基准线,凸显任务难度。数据构建过程中,研究团队需解决图像对语义关联性判定(采用CLIP相似度阈值筛选)、跨风格泛化(通过集合划分避免数据泄漏)以及指令自动生成(基于Qwen2.5-VL 70B模型优化)等关键技术难题,这些挑战为后续研究提供了明确的改进方向。
常用场景
经典使用场景
VECTOREDITS数据集为自然语言驱动的矢量图形编辑任务提供了标准化的评估平台。在数字内容创作领域,该数据集通过27万组SVG图像对及其对应的自然语言编辑指令,支持模型学习如何根据文本描述精确修改矢量图形的几何属性、空间布局和视觉样式。典型应用场景包括训练多模态模型理解指令语义、解析原始图像结构,并生成符合要求的SVG代码修改方案。
实际应用
在实际应用中,VECTOREDITS可显著降低数字艺术创作的技术门槛。设计师通过自然语言指令即可快速完成图标样式迭代、界面元素适配等专业操作;教育领域支持可视化编程教学中的实时图形反馈;电商平台能自动生成商品矢量图的多样化变体。该数据集支撑的系统最终可实现从‘描述即编辑’的创作范式革新。
衍生相关工作
该数据集已催生多个重要研究方向:基于指令的SVG增量编辑框架SVG-EditNet扩展了动态修改能力;多模态对比学习模型VecCLIP提升了指令与图形元素的对齐精度;矢量扩散模型VectorLDM将生成范式引入编辑任务。相关成果在ACL、CVPR等顶会形成系列工作,逐步构建起矢量图形语义操控的技术体系。
以上内容由遇见数据集搜集并总结生成


