vintage-artworks-60k-captioned
收藏Hugging Face2024-07-20 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/SilentAntagonist/vintage-artworks-60k-captioned
下载链接
链接失效反馈官方服务:
资源简介:
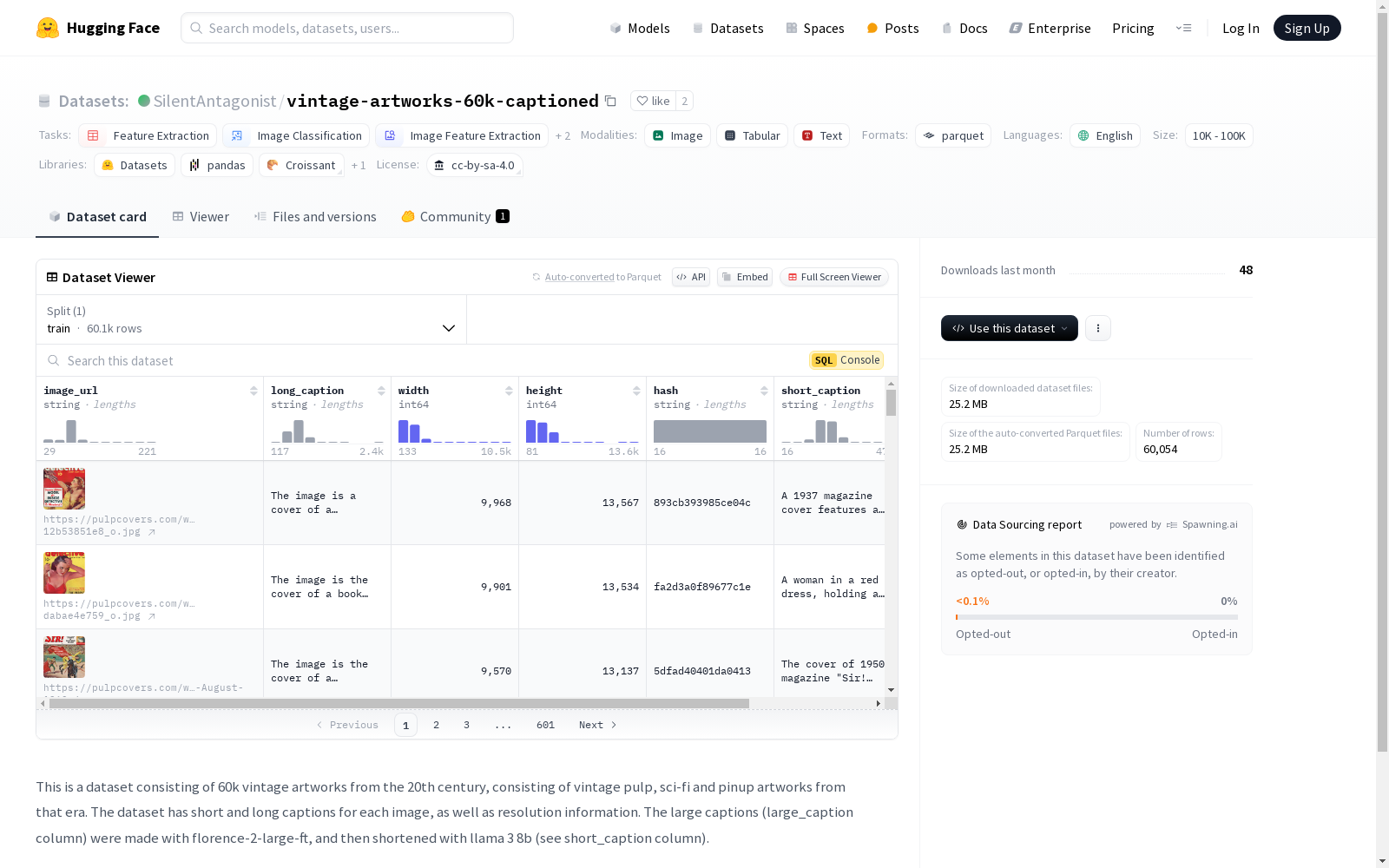
该数据集包含60k幅20世纪的复古艺术品,包括复古纸浆、科幻和那个时代的pinup艺术品。每幅图像都有简短和详细的描述,以及分辨率信息。详细的描述(large_caption列)是由florence-2-large-ft生成的,然后通过llama 3 8b缩短为简短描述(short_caption列)。
This dataset contains 60,000 vintage artworks from the 20th century, including retro pulp art, science fiction art, and pinup artworks from that era. Each image is paired with both a concise and a detailed description, as well as resolution metadata. The detailed descriptions (stored in the `large_caption` column) were generated by Florence-2-large-ft, and then shortened into brief descriptions (stored in the `short_caption` column) using Llama 3 8B.
创建时间:
2024-07-18
原始信息汇总
数据集概述
许可证
- 该数据集遵循 cc-by-sa-4.0 许可证。
任务类别
- 特征提取
- 图像分类
- 图像特征提取
- 文本到图像
- 图像到文本
语言
- 英语
数据集名称
- Vintage 20th century artworks, high quality captions
数据集规模
- 10K<n<100K
数据集描述
- 该数据集包含60k幅20世纪的复古艺术作品,包括复古纸浆、科幻和那个时代的pinup艺术作品。
- 每张图像都有简短和详细的描述,以及分辨率信息。
- 详细的描述(large_caption列)由florence-2-large-ft生成,然后通过llama 3 8b缩短(见short_caption列)。
搜集汇总
数据集介绍
构建方式
该数据集汇集了20世纪60,000件复古艺术作品,涵盖科幻、低俗小说插画及美女画等多种类型。每幅作品均配有详细描述,包括长描述和短描述。长描述由florence-2-large-ft生成,随后通过llama 3 8b模型进行精简,形成短描述。此外,数据集还包含每幅图像的分辨率信息,确保数据的完整性和可用性。
特点
该数据集的特点在于其丰富的内容和高质量的标注。每幅作品不仅包含高分辨率的图像,还配有经过精心处理的长短描述,这些描述通过先进的自然语言处理模型生成,确保了描述的准确性和多样性。数据集涵盖了20世纪多种艺术风格,为研究复古艺术提供了宝贵的资源。
使用方法
该数据集适用于多种任务,包括图像分类、特征提取、文本到图像生成及图像到文本转换等。研究人员可以利用这些图像和描述进行艺术风格分析、图像生成模型的训练,或进行跨模态学习研究。数据集的结构化信息和高分辨率图像为深度学习模型的训练和评估提供了坚实的基础。
背景与挑战
背景概述
Vintage-artworks-60k-captioned数据集聚焦于20世纪复古艺术作品的数字化与标注,涵盖了该时期的复古纸浆、科幻和招贴艺术作品。该数据集由60,000幅高质量图像组成,每幅图像均配有详细的长短描述,旨在为图像分类、特征提取及文本-图像互转等任务提供丰富资源。数据集的创建时间虽未明确提及,但其通过现代AI技术(如florence-2-large-ft和llama 3 8b模型)生成的长短描述,展现了跨时代艺术与人工智能的深度融合。这一数据集不仅为艺术史研究提供了新的视角,也为计算机视觉和自然语言处理领域的交叉研究开辟了新的路径。
当前挑战
Vintage-artworks-60k-captioned数据集在解决图像分类与文本-图像互转问题时,面临多重挑战。首先,复古艺术作品的风格多样且复杂,如何准确捕捉并描述其艺术特征成为一大难题。其次,数据集的构建过程中,生成高质量的长短描述需要依赖先进的AI模型,这对模型的语义理解与生成能力提出了极高要求。此外,数据集的规模虽大,但如何确保标注的一致性与准确性,仍需进一步优化。这些挑战不仅考验了数据集的构建技术,也为相关领域的研究者提供了探索与创新的空间。
常用场景
经典使用场景
在艺术史和数字人文领域,vintage-artworks-60k-captioned数据集为研究者提供了一个丰富的资源库,用于探索20世纪复古艺术作品的视觉特征与文本描述之间的关系。通过该数据集,研究者可以进行图像分类、特征提取以及文本到图像或图像到文本的转换任务,从而深入理解艺术作品的多模态表达。
衍生相关工作
基于vintage-artworks-60k-captioned数据集,研究者已经开展了一系列相关工作,包括艺术风格迁移、图像生成与修复、以及多模态艺术分析模型的开发。这些工作不仅推动了计算机视觉与艺术史研究的交叉融合,还为文化遗产保护与传播提供了新的技术手段。
数据集最近研究
最新研究方向
在数字人文与计算机视觉交叉领域,vintage-artworks-60k-captioned数据集为研究者提供了丰富的20世纪复古艺术作品资源。该数据集不仅包含了高质量的图像,还配备了详尽的文字描述,为图像分类、特征提取及文本到图像生成等任务提供了坚实的基础。近年来,随着深度学习技术的进步,该数据集在图像与文本的多模态学习研究中显示出其独特价值,尤其是在艺术风格迁移、历史图像复原及文化遗产数字化保护等热点方向。此外,该数据集的应用还推动了艺术史研究与人工智能技术的深度融合,为理解20世纪艺术风格演变提供了新的视角。
以上内容由遇见数据集搜集并总结生成


