TencentARC/StoryStream
收藏Hugging Face2024-07-17 更新2024-07-13 收录
下载链接:
https://hf-mirror.com/datasets/TencentARC/StoryStream
下载链接
链接失效反馈官方服务:
资源简介:
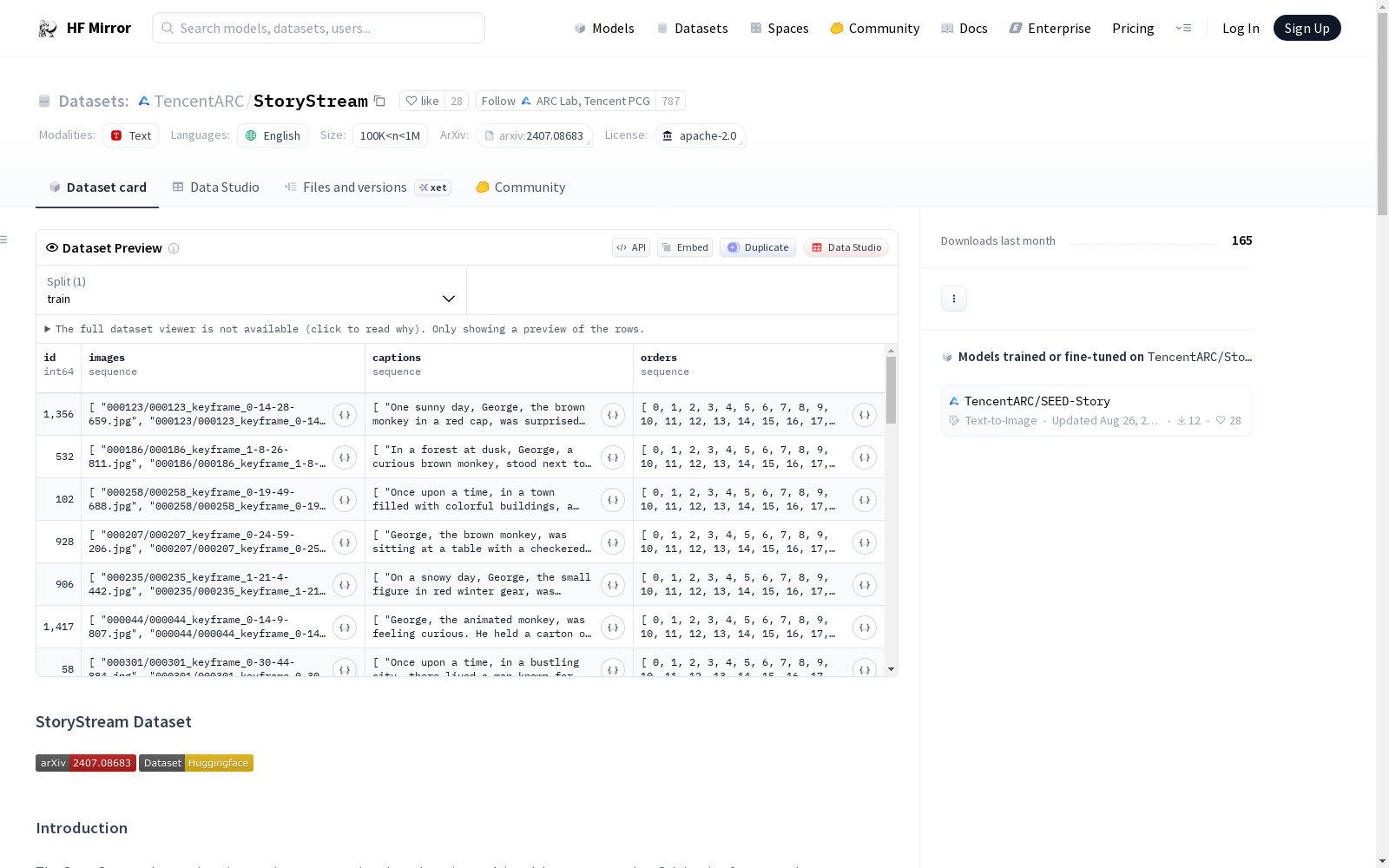
StoryStream数据集是一个创新的资源,旨在推动多模态故事生成。该数据集源自流行的卡通系列,包含详细的叙述和高分辨率图像的全面集合,旨在支持长故事序列的创建。数据集分为三个子集:Curious George、Rabbids Invasion和The Land Before Time。每个子集包括一个图像包和一个JSONL文件包,JSONL文件包中的每一行对应一个包含30张图像及其相关文本的故事。数据集还提供了训练和验证集的不同划分方式,并提供了如何使用数据集的指导。
The StoryStream dataset is an innovative resource aimed at advancing multimodal story generation. Originating from popular cartoon series, this dataset includes a comprehensive collection of detailed narratives and high resolution images. It is designed to support the creation of long story sequences. The dataset has three subsets: Curious George, Rabbids Invasion, and The Land Before Time. Each subset includes an image package and a JSONL file package, with each JSONL file line corresponding to a story of 30 images and their associated texts. The dataset has different splits for training and validation, with specific details provided for each subset, especially the Curious George subset containing two validation sets, while Rabbids Invasion and The Land Before Time subsets each have one validation set.
提供机构:
TencentARC
搜集汇总
数据集介绍
构建方式
在多媒体叙事生成领域,StoryStream数据集以其严谨的构建方法脱颖而出。该数据集源自《好奇猴乔治》、《疯狂兔子入侵》和《史前陆地》三部知名卡通系列,通过系统性地提取高分辨率关键帧图像,并配以详尽的叙事文本,构建了长达30帧的连贯故事序列。每个子集均包含图像压缩包与JSONL文件包,其中JSONL文件的每一行对应一个完整故事,确保了图像与文本在时序上的精确对齐。数据划分兼顾了同一视频内不同片段与完全未见视频的验证集设计,为模型评估提供了多层次的信度保障。
特点
StoryStream数据集的核心特点在于其丰富的多模态叙事结构与卓越的数据质量。数据集囊括了视觉上引人入胜的高清图像,每一帧均配有细腻的叙述性文字,生动再现了现实故事书的叙事密度与艺术感染力。相较于现有资源,该数据集的故事序列显著延长,增强了故事情节的深度与连续性。三个独立子集分别代表了不同的卡通风格与叙事主题,为研究提供了多样化的故事语境,支持对长序列故事生成任务进行深入且全面的探索。
使用方法
为有效利用StoryStream数据集,研究者可依据提供的JSONL格式加载数据,其中每条记录包含图像路径列表及对应的描述性文本序列。在模型训练过程中,建议参考原研究方案,将长故事分割为10帧的片段以提升训练效率,相关处理脚本已在代码库中公开。数据加载器的构建可参照项目源码中的`build_long_story_datapipe`函数实现。该数据集适用于训练与评估多模态长故事生成模型,其精心设计的验证集有助于客观衡量模型在已知内容延续与全新内容泛化两方面的性能。
背景与挑战
背景概述
在人工智能与多媒体融合的前沿领域,长序列多模态故事生成正成为一项关键研究课题。StoryStream数据集由腾讯ARC团队于2024年创建,旨在通过整合高分辨率图像与详尽的叙事文本,推动多模态长故事生成技术的发展。该数据集源自《好奇猴乔治》、《疯狂兔子入侵》及《史前陆地》等经典卡通系列,构建了包含数十万条图像-文本对的大规模资源,其核心研究问题聚焦于如何实现连贯、生动且视觉丰富的长故事自动生成。这一资源的出现,为叙事连贯性建模、跨模态对齐等研究方向提供了重要基准,显著提升了多模态生成模型的叙事深度与视觉保真度。
当前挑战
StoryStream数据集致力于解决多模态长故事生成中的核心挑战,即如何在长达30帧的图像序列中维持叙事逻辑的连贯性与跨模态语义的一致性。构建过程中,研究团队面临多重困难:从原始卡通视频中提取高质量关键帧并确保时间顺序的准确性,以及为每一帧图像撰写细节丰富且上下文衔接的自然语言描述,均需耗费大量人工标注与校验成本。此外,数据集的划分设计需兼顾模型对已知场景的泛化能力与对全新视频内容的适应能力,这要求验证集同时包含同视频不同片段与完全未见视频的样本,以全面评估模型的叙事生成质量与泛化性能。
常用场景
经典使用场景
在多媒体叙事生成领域,StoryStream数据集以其源自经典卡通系列的高分辨率图像与详细叙事文本的配对,为长序列故事生成任务提供了关键支撑。该数据集通过包含30帧图像及其对应描述的连贯故事单元,使得研究者能够训练模型理解视觉与文本间的时序关联,进而模拟人类创作故事时的逻辑流与情感递进。其经典应用场景集中于开发能够自动生成连贯、富有情节的多模态故事系统,这些系统不仅需捕捉单帧画面的内容,还需在长序列中维持叙事的一致性与吸引力。
解决学术问题
StoryStream数据集有效应对了多媒体叙事生成中长序列连贯性建模的学术挑战。传统数据集往往局限于短片段或缺乏详尽的文本描述,导致模型在生成长故事时容易出现情节断裂或语义漂移。该数据集通过提供长达30帧的视觉-文本序列,促进了模型对时序依赖和跨模态对齐的学习,从而解决了长故事生成中的一致性维护、情节发展逻辑建模以及视觉细节与叙事深度融合等核心问题。其意义在于推动了叙事智能从片段化描述向整体性创作的演进,为人工智能在创意内容生成领域的深化奠定了基础。
衍生相关工作
围绕StoryStream数据集,已衍生出多项经典研究工作,特别是在多模态大语言模型与长故事生成的交叉领域。例如,SEED-Story等研究利用该数据集探索了如何将大型语言模型的文本生成能力与视觉编码器结合,以实现端到端的长故事合成。这些工作不仅优化了序列生成中的注意力机制与跨模态融合策略,还推动了评估指标的发展,如叙事连贯性与视觉忠实度的量化。相关成果进一步拓展至视频摘要、交互式叙事系统等方向,形成了以时序多模态生成为核心的研究脉络。
以上内容由遇见数据集搜集并总结生成


