MMBias
收藏arXiv2024-12-23 更新2024-12-25 收录
下载链接:
https://github.com/sepehrjng92/MMBias/blob/main/Readme.md
下载链接
链接失效反馈官方服务:
资源简介:
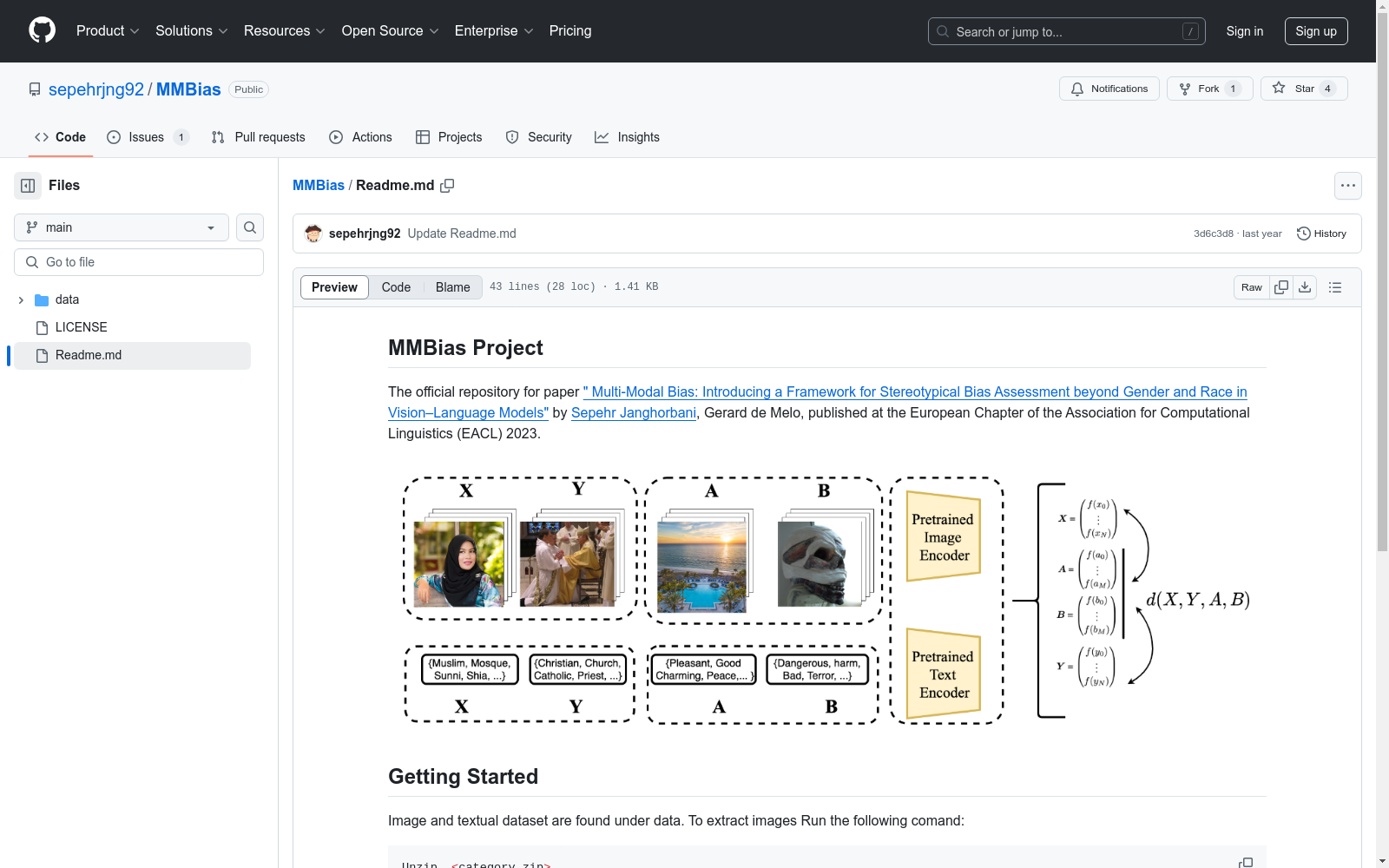
MMBias数据集由Janghorbani和de Melo创建,专门用于评估视觉-语言模型中的刻板印象偏差。该数据集包含3500个目标图像和350个英语短语,涵盖宗教、国籍、残疾和性取向等14个特定目标群体。数据集通过配对文本短语和相应图像,便于创建多模态嵌入,用于偏差检测实验。创建过程包括对不同目标类别的图像和文本进行精心选择和配对,旨在分析多模态模型中偏差的动态交互,特别是在公共安全和医疗等关键领域。
The MMBias dataset, created by Janghorbani and de Melo, is specifically designed to evaluate stereotype bias in vision-language models. It contains 3500 target images and 350 English phrases, covering 14 specific target groups including religion, nationality, disability, and sexual orientation. By pairing textual phrases with their corresponding images, the dataset facilitates the creation of multimodal embeddings for bias detection experiments. Its construction process involves meticulous selection and pairing of images and texts across different target categories, aiming to analyze the dynamic interactions of bias in multimodal models, particularly in critical domains such as public safety and healthcare.
提供机构:
穆罕默德·本·拉希德政府学院
创建时间:
2024-12-23
搜集汇总
数据集介绍
构建方式
MMBias数据集由Janghorbani和de Melo精心构建,旨在评估视觉与语言模型中的刻板偏见。该数据集涵盖了宗教、国籍、性取向和残疾等多个易受偏见影响的类别,包含3500张目标图像和350条英文短语,每条短语对应一个目标类别。通过将图像与文本配对,数据集生成了多模态嵌入,为偏见检测实验提供了丰富的数据支持。
特点
MMBias数据集的显著特点在于其多模态性和多样性。它不仅涵盖了传统性别和种族类别之外的多个敏感类别,还通过图像与文本的配对,揭示了多模态模型中偏见的动态交互。数据集通过模拟偏见评分,量化了文本、图像和多模态嵌入中的偏见,并分类了偏见的放大、缓解和中性三种交互类型,为理解多模态偏见的复杂性提供了重要工具。
使用方法
MMBias数据集主要用于研究多模态模型中的偏见交互。研究者可以通过计算文本、图像和多模态嵌入的偏见评分,分析偏见的放大、缓解和中性交互。此外,数据集还可用于开发和验证多模态偏见检测算法,帮助设计更加公平和准确的人工智能系统。通过模拟和分析多模态偏见的动态交互,研究者可以深入理解偏见在多模态系统中的传播机制,从而提出有效的偏见缓解策略。
背景与挑战
背景概述
随着多模态机器学习模型在公共安全、安全和医疗等关键领域的广泛应用,其潜在的偏见问题日益受到关注。MMBias数据集由Mohammed Bin Rashid School of Government的Mounia Drissi于2024年创建,旨在研究多模态模型中动态偏见交互的问题。该数据集涵盖了宗教、国籍和性取向等易受偏见影响的类别,通过模拟和启发式方法计算文本、图像和多模态嵌入的偏见分数,进而分析偏见的放大、缓解和中性化交互。MMBias数据集的提出填补了多模态偏见交互研究的空白,为构建公平和公正的AI系统提供了重要的理论基础。
当前挑战
MMBias数据集在构建过程中面临多重挑战。首先,多模态模型中的偏见交互机制复杂,现有的研究多集中于单一模态的偏见检测,而对多模态交互的动态特性理解不足。其次,数据集的构建需要涵盖多种易受偏见影响的类别,确保数据的多样性和代表性,这增加了数据收集和标注的难度。此外,如何量化和分类多模态偏见的交互效应,尤其是放大、缓解和中性化,是该数据集面临的主要技术挑战。最后,尽管该数据集提供了初步的框架,但如何在实际应用中验证和优化这一框架,仍需进一步的研究和探索。
常用场景
经典使用场景
MMBias数据集的经典使用场景主要集中在多模态机器学习模型的偏差分析上。通过结合文本和图像两种模态,该数据集能够帮助研究者系统性地分析多模态模型中偏差的动态交互。具体而言,研究者可以利用MMBias数据集计算文本、图像以及多模态嵌入的偏差分数,进而分类这些偏差交互为放大、缓解或中性,从而深入理解多模态模型中偏差的复杂动态。
衍生相关工作
MMBias数据集的提出催生了一系列相关研究,特别是在多模态偏差分析和公平性研究领域。例如,研究者利用该数据集开发了新的偏差分类框架,进一步探索了多模态模型中偏差的动态交互。此外,MMBias还启发了对多模态模型架构的深入研究,如早期融合模型和生成模型中的偏差传播机制。这些衍生工作不仅扩展了多模态偏差分析的理论基础,还为实际应用中的偏差缓解提供了新的工具和方法。
数据集最近研究
最新研究方向
MMBias数据集的最新研究方向聚焦于多模态模型中偏见的动态交互分析。研究通过模拟方法量化文本和图像偏见的相互作用,提出了偏见放大、缓解和中性三种交互类型,并揭示了不同模态在偏见传播中的主导作用。该研究不仅为多模态偏见的系统性分析提供了可解释的框架,还为开发公平和公正的AI系统提供了理论基础。此外,研究结果强调了在多模态融合中,图像偏见往往起到主导作用,而文本偏见则在偏见缓解中扮演关键角色。这一发现对未来多模态模型的设计和偏见缓解策略具有重要指导意义。
相关研究论文
- 1More is Less? A Simulation-Based Approach to Dynamic Interactions between Biases in Multimodal Models穆罕默德·本·拉希德政府学院 · 2024年
以上内容由遇见数据集搜集并总结生成


