rag-qa-logs-corpus
收藏Hugging Face2025-12-25 更新2025-12-26 收录
下载链接:
https://huggingface.co/datasets/tarekmasryo/rag-qa-logs-corpus
下载链接
链接失效反馈官方服务:
资源简介:
一个生产风格、隐私安全的合成数据集,模拟从真实检索增强生成(RAG)系统导出的遥测数据——从语料库→块索引→排名检索列表→评估结果。设计为一个分析就绪的多表基准,用于:RAG质量分析(正确性、忠实度、幻觉)、检索策略比较(密集/BM25/混合/重排变体)、风险与元建模(从遥测预测失败/幻觉)、延迟与成本权衡(毫秒、令牌、美元)、仪表盘和教学材料。所有记录均为完全合成,无真实用户、客户、患者或公司数据。
A production-grade, privacy-safe synthetic dataset simulating telemetry data exported from real-world Retrieval-Augmented Generation (RAG) systems, covering the full pipeline from corpus, chunk indexing, ranked retrieval lists to evaluation results. It is designed as an analysis-ready multi-table benchmark for use cases including: RAG quality analysis (correctness, faithfulness, hallucinations), retrieval strategy comparison (dense/BM25/hybrid/reranking variants), risk and meta-modeling (predicting failures or hallucinations from telemetry data), latency and cost tradeoffs (milliseconds, tokens, USD), as well as dashboard creation and instructional materials. All records are fully synthetic, with no real user, customer, patient, or corporate data included.
创建时间:
2025-12-14
原始信息汇总
RAG QA Logs & Corpus 数据集概述
数据集基本信息
- 名称:RAG QA Logs & Corpus
- 描述:一个模拟真实检索增强生成(RAG)系统遥测数据的、生产风格且隐私安全的合成数据集,涵盖从语料库到分块索引、排序检索列表再到评估结果的完整流程。
- 许可证:CC BY 4.0
- 语言:英语
- 数据规模:100K < n < 1M
- 总行数:103,255行,分布在6个关联的CSV表中
- 数据类型:多表表格日志 + 短文本字段(查询、答案、文本块)
- 任务类别:问答、表格分类、表格回归
- 标签:
is_correct,hallucination_flag,faithfulness_label - 数据划分:训练集、验证集、测试集
核心内容与用途
- 设计目的:作为分析就绪的多表基准数据集,用于RAG质量分析、检索策略比较、风险与元建模、延迟与成本权衡分析,以及仪表板开发和教学材料制作。
- 隐私性:所有记录均为完全合成数据,不包含任何真实用户、客户、患者或公司数据,也无任何个人身份信息。
- 覆盖领域:支持常见问题、人力资源政策、产品文档、开发者文档、政策、财务报告、医疗指南、研究论文、客户成功、数据平台文档、MLOps文档、营销分析。
- 任务类型:事实型、解释型、摘要型、多跳推理、表格问答、时序推理、比较、指令遵循。
- 检索策略:密集检索、BM25、混合检索、密集检索后重排、BM25后重排。
文件详情
| 文件名 | 行数 | 列数 | 粒度 |
|---|---|---|---|
rag_corpus_documents.csv |
658 | 19 | 每个文档一行 |
rag_corpus_chunks.csv |
5,237 | 6 | 每个文本块一行 |
rag_retrieval_events.csv |
93,375 | 12 | 每个示例中每个被检索的文本块一行 |
eval_runs.csv |
3,824 | 49 | 每个问答评估示例一行 |
scenarios.csv |
62 | 13 | 每个场景模板一行 |
data_dictionary.csv |
99 | 5 | 每个列定义一行 |
表连接关系
- 文档表 → 文本块表:
rag_corpus_documents.doc_id = rag_corpus_chunks.doc_id - 评估运行表 → 检索事件表:
eval_runs.example_id = rag_retrieval_events.example_id - 评估运行表 → 场景表:
eval_runs.scenario_id = scenarios.scenario_id - 检索事件表 → 文本块表:
rag_retrieval_events.chunk_id = rag_corpus_chunks.chunk_id
典型任务与目标
- 主要学习目标:基于
is_correct、hallucination_flag、faithfulness_label进行分类。 - 应用场景:结合遥测数据(检索排名/分数、召回率/MRR、延迟、令牌数、配置),可用于构建预测答案失败/幻觉风险的元模型、设计护栏的风险评分系统,以及基于成本/延迟/质量权衡的策略设计。
数据字典
- 文件:
data_dictionary.csv - 内容:提供所有表的列级文档,包括
table_name、column_name、dtype、description、allowed_values。
局限性
- 此为合成基准数据,非生产数据。
rag_corpus_chunks.chunk_text可能比真实语料库更模板化/多样性较低。- 适用于研究、教学、基准测试和原型设计。
- 不适用于高风险决策(临床、法律、金融)。
搜集汇总
数据集介绍
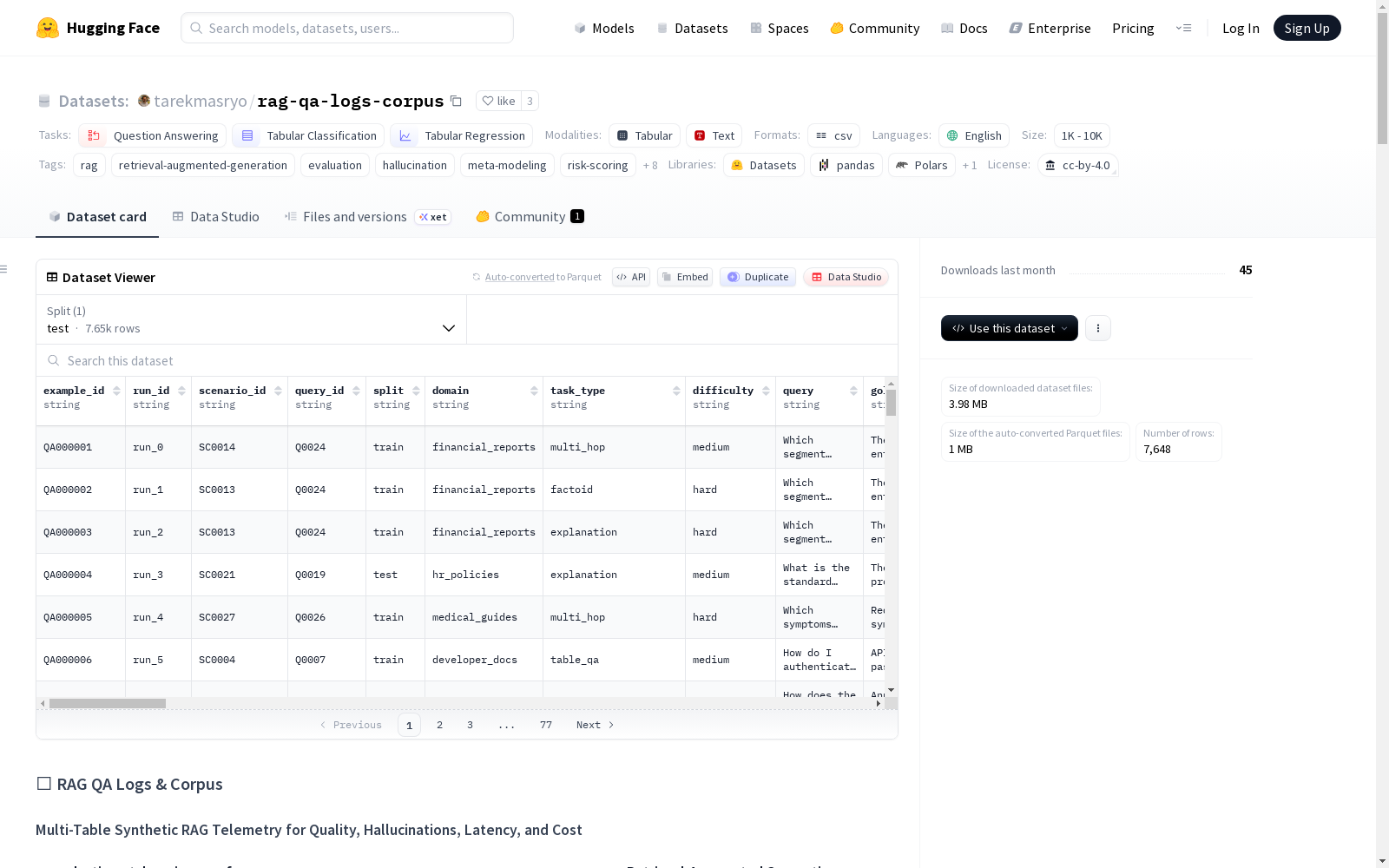
构建方式
在检索增强生成(RAG)系统日益普及的背景下,该数据集通过程序化生成方法构建了一套多表合成日志与语料库。其构建过程模拟了真实RAG系统的全链路数据流,从文档语料库的创建、文本分块索引的建立,到检索事件的记录与问答评估结果的生成,均采用合成数据以确保隐私安全。数据集涵盖12个领域文档和8种任务类型,通过稳定的标识符(如doc_id、chunk_id)将六个CSV表格有机连接,形成分析就绪的结构化基准。
特点
该数据集的核心特点在于其生产级仿真性与多维度分析能力。作为完全合成的隐私安全数据,它避免了真实用户信息的泄露风险,同时保留了RAG系统在质量、幻觉、延迟和成本等方面的关键遥测指标。数据集包含超过10万行记录,覆盖支持问答、解释、多跳推理等多种任务类型,并集成了密集检索、BM25及混合策略等多种检索方法。其多表结构支持从文档到检索事件的完整追溯,为研究检索策略比较、风险建模及性能权衡提供了丰富的数据基础。
使用方法
使用该数据集时,研究者可通过Pandas或Hugging Face Datasets库加载六个关联的CSV文件,并利用稳定的连接键(如example_id、chunk_id)进行表间关联分析。典型应用包括构建元模型以预测答案错误或幻觉风险,评估不同检索策略在准确性、延迟和成本上的权衡,以及开发用于护栏系统的风险评分机制。数据集已划分为训练、验证和测试集,适用于机器学习模型的训练与评估,但需注意其合成性质限制,不适用于高风险的决策场景。
背景与挑战
背景概述
随着检索增强生成(RAG)技术在自然语言处理领域的广泛应用,对其系统性能进行系统性评估与优化的需求日益凸显。RAG QA Logs & Corpus数据集应运而生,由研究人员Tarek Masryo创建,作为一个多表合成的RAG遥测基准,旨在模拟真实生产环境中的日志数据。该数据集聚焦于解决RAG系统在问答任务中的核心研究问题,包括答案正确性、忠实度评估以及幻觉检测,同时涵盖检索策略比较、风险建模及延迟成本权衡等多个维度。通过覆盖支持FAQ、人力资源政策、产品文档、医疗指南等十二个领域,以及事实性问答、解释、多跳推理等八种任务类型,该数据集为学术界与工业界提供了一个隐私安全、分析就绪的基准工具,有力推动了RAG系统评估与优化方法的研究进展。
当前挑战
在RAG系统领域,确保生成答案的准确性与忠实度、有效检测并缓解幻觉现象,是当前面临的核心挑战。RAG QA Logs & Corpus数据集针对这些挑战,通过提供标注数据支持质量分析与风险建模,但构建过程亦存在显著困难。由于真实生产数据涉及隐私与安全约束,数据集采用全合成方式生成,需在保持数据真实性与多样性的同时,完全避免任何个人或敏感信息。此外,模拟多表关联的遥测结构要求设计复杂的程序化生成逻辑,以确保文档、分块、检索事件与评估运行之间的数据一致性与可连接性,这增加了数据构建的复杂度与技术要求。
常用场景
经典使用场景
在检索增强生成(RAG)系统的研究领域,rag-qa-logs-corpus数据集常被用作评估RAG质量与性能的基准工具。该数据集模拟了真实RAG系统的多表遥测日志,涵盖从文档索引到检索排序再到问答评估的完整流程,为研究者提供了分析检索策略(如稠密检索、BM25、混合方法及重排序变体)对答案正确性、忠实度及幻觉率影响的标准化环境。通过其结构化的表格关联设计,用户能够深入探究不同检索配置下系统在事实性问答、多跳推理及指令遵循等任务中的表现差异。
解决学术问题
该数据集有效应对了RAG系统中若干核心学术挑战,包括答案幻觉检测、检索质量评估以及系统风险建模。通过提供标注清晰的正确性标签、幻觉标志及忠实度类别,它支持构建元模型以预测问答失败风险,从而助力开发更可靠的幻觉抑制机制。同时,其涵盖的延迟、令牌消耗及成本等多维度指标,为量化检索效率与资源开销之间的权衡提供了实证基础,推动了面向高效可靠RAG架构的优化研究。
衍生相关工作
围绕该数据集已衍生出一系列经典研究工作,主要集中在RAG风险评估与优化框架的构建上。例如,基于其提供的多表遥测数据,研究者开发了用于预测幻觉发生概率的元学习模型,以及结合检索分数与上下文相关性的风险评分算法。同时,部分工作利用其延迟与成本指标,提出了面向实时应用的检索-生成协同调度策略,这些成果显著推进了RAG系统在可靠性、效率及可解释性方面的前沿进展。
以上内容由遇见数据集搜集并总结生成


