english-nuer_sentence-pairs
收藏Hugging Face2025-05-18 更新2025-05-19 收录
下载链接:
https://huggingface.co/datasets/michsethowusu/english-nuer_sentence-pairs
下载链接
链接失效反馈官方服务:
资源简介:
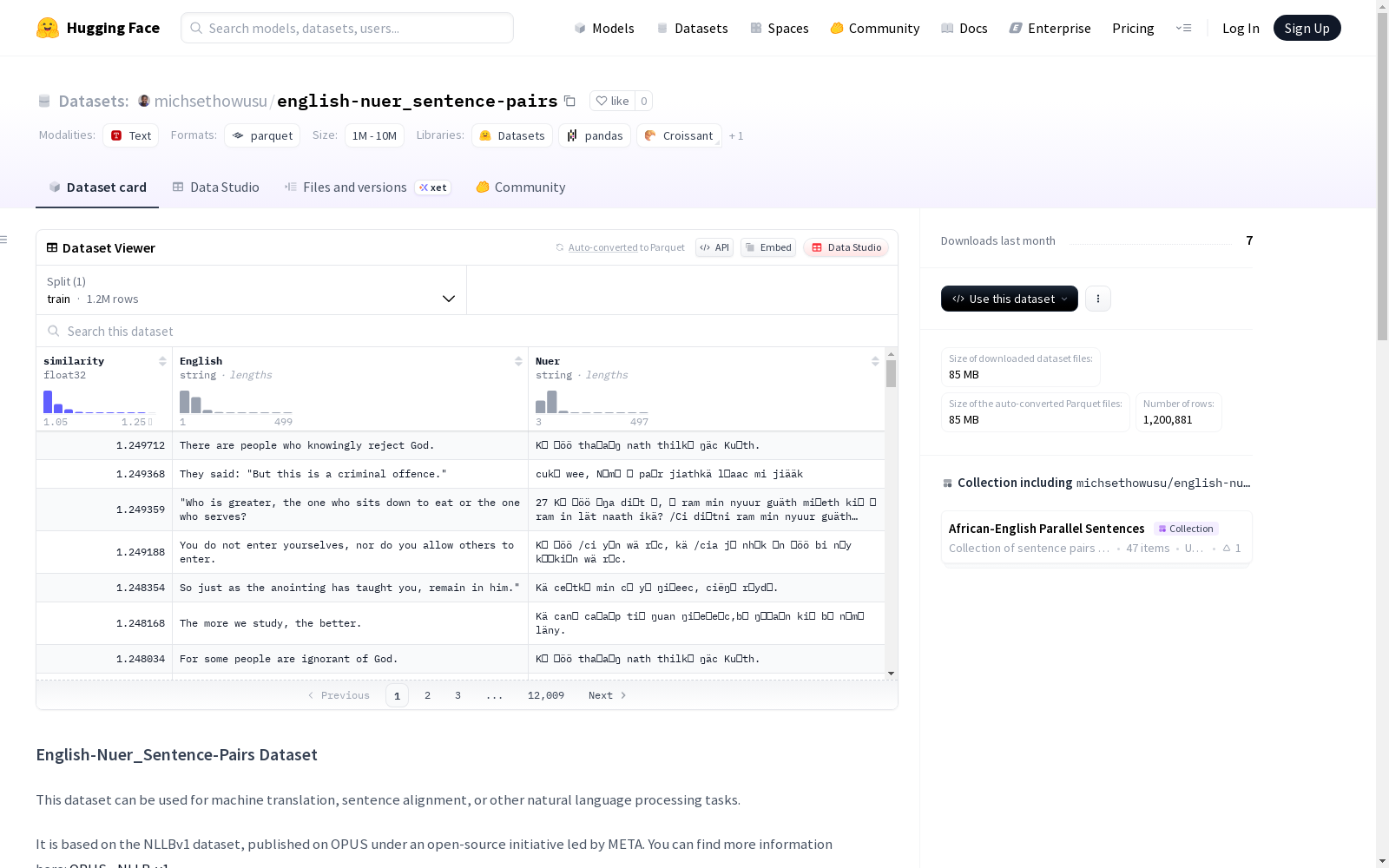
English-Nuer_Sentence-Pairs数据集包含了非洲语言句子对及其相似度得分,适用于机器翻译、句子对齐或其他自然语言处理任务。数据集基于NLLBv1构建,包含了两种语言的句子对,并提供了句子的相似度评分,可用于训练和评估机器学习模型,特别是在翻译、句子相似度和跨语言迁移学习等方面。
The English-Nuer_Sentence-Pairs Dataset comprises sentence pairs in English and Nuer (an African language) along with their corresponding similarity scores, and is suitable for machine translation, sentence alignment and other natural language processing tasks. Developed based on NLLBv1, this dataset provides paired sentences across the two languages alongside similarity scores, and can be utilized to train and evaluate machine learning models, especially for tasks such as translation, sentence similarity evaluation and cross-lingual transfer learning.
创建时间:
2025-05-17
搜集汇总
数据集介绍
构建方式
该数据集源自NLLBv1语料库,通过多语言句子嵌入技术从大规模网络文本中自动挖掘平行句对。构建过程采用基于相似度阈值的过滤机制,利用跨语言语义空间计算句对关联强度,最终形成包含120万条句对的训练集。数据采集遵循开放学术协议,所有语料均经过去重和标准化处理,确保构建过程的科学性与可复现性。
特点
数据集呈现典型的双语平行语料特征,每条记录包含英语-努尔语句对及其语义相似度评分。其核心优势在于覆盖低资源语言场景,相似度指标为研究跨语言语义对齐提供了量化依据。数据规模达到百万级别,格式规范统一,三个字段分别对应相似度值、英语原句与努尔语译文,为机器翻译模型训练提供了高质量监督信号。
使用方法
研究人员可直接加载CSV格式数据用于神经机器翻译系统的端到端训练,相似度字段可作为训练权重或数据筛选依据。该数据集适用于跨语言检索、双语词典构建等下游任务,在使用过程中建议根据相似度阈值划分训练验证集。对于低资源语言研究,可结合迁移学习技术提升模型性能,所有语料均符合学术使用规范。
背景与挑战
背景概述
在跨语言自然语言处理研究蓬勃发展的背景下,English-Nuer_Sentence-Pairs数据集应运而生,其构建工作源于META主导的开放源码计划NLLBv1。该数据集由Holger Schwenk等学者基于OPUS语料库平台开发,核心目标在于解决努尔语这类低资源语言与英语之间的机器翻译与句子对齐问题。通过提供超过120万条带相似度评分的平行句对,该资源显著推动了非洲语言在神经机器翻译与多语言表示学习领域的研究进程,为跨语言迁移学习提供了关键数据支撑。
当前挑战
针对低资源语言机器翻译任务,该数据集需应对努尔语语法结构复杂性与语言资源稀缺的双重挑战。在构建过程中,研究者面临双语语料质量参差不齐的难题,需通过分布式表示与相似度计算实现海量数据的自动筛选。同时,语言对的不平衡分布与噪声数据过滤要求开发高效的语料挖掘算法,这对跨语言语义空间建模与评估指标设计提出了更高要求。
常用场景
经典使用场景
在跨语言自然语言处理研究中,English-Nuer_Sentence-Pairs数据集为努尔语与英语之间的机器翻译任务提供了重要支撑。该数据集包含120余万条平行句对,每条数据均配备相似度评分,为构建高质量的双语对齐模型奠定了坚实基础。研究人员可基于此数据集训练神经机器翻译系统,探索低资源语言在跨语言理解中的表现特性。
实际应用
在实际应用层面,该数据集支撑的翻译技术可直接服务于南苏丹等努尔语使用地区的跨语言交流需求。在教育领域可辅助双语教材开发,在公共服务领域能促进政府文件的多语言化进程。基于该数据集训练的模型还可集成到实时翻译系统中,为国际组织在非洲地区的沟通协作提供技术保障。
衍生相关工作
该数据集衍生的经典研究包括Schwenk等人提出的联合多语言句子表示学习方法,以及Artetxe团队基于边界值的平行语料挖掘技术。相关成果进一步催生了WikiMatrix和CCMatrix等大规模多语言项目,推动了XLM-R、mBART等预训练模型的发展,为低资源语言处理建立了系统化的方法论体系。
以上内容由遇见数据集搜集并总结生成


