clustered_tulu_3_8
收藏Hugging Face2025-07-22 更新2025-07-23 收录
下载链接:
https://huggingface.co/datasets/Malikeh1375/clustered_tulu_3_8
下载链接
链接失效反馈官方服务:
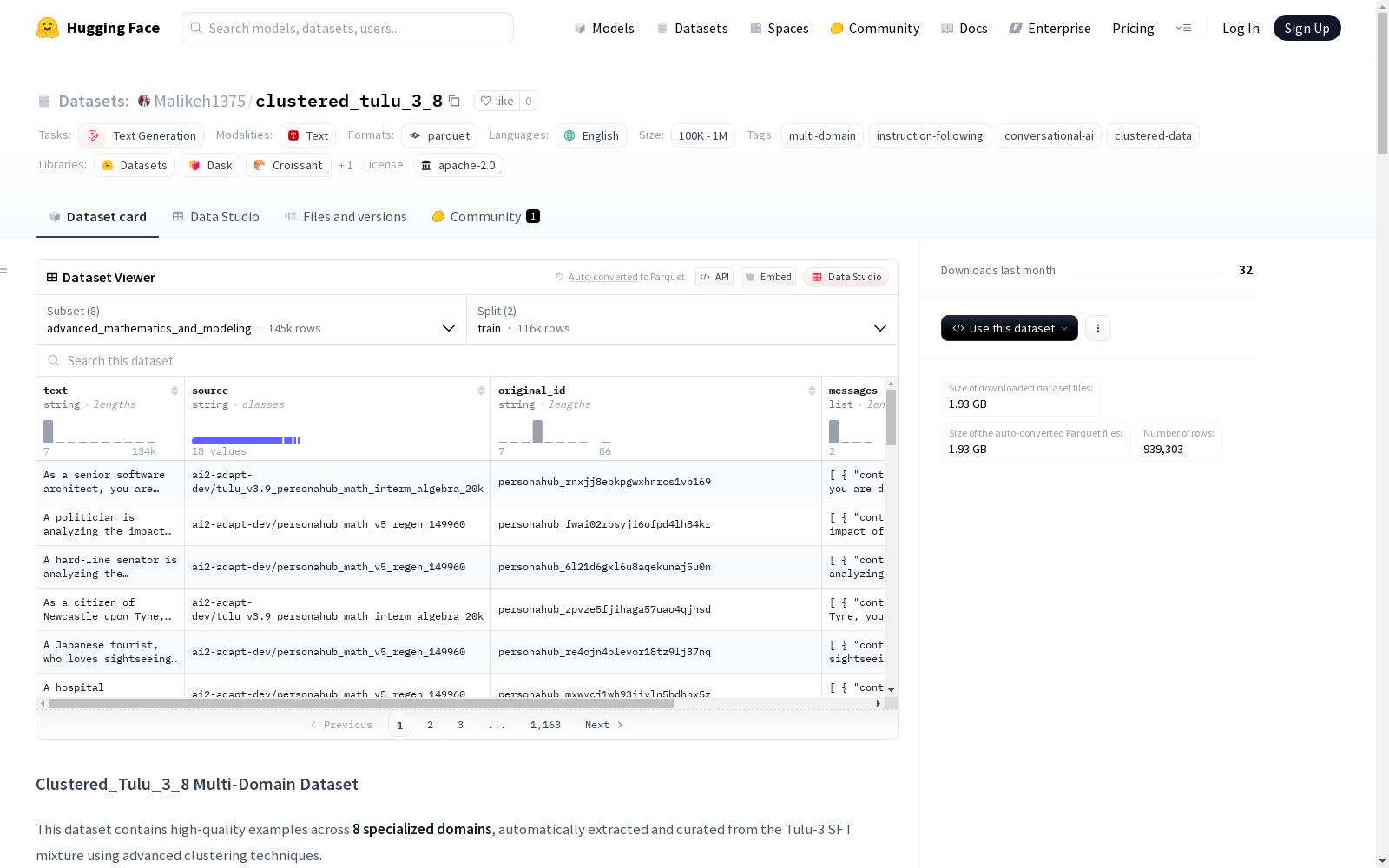
资源简介:
Clustered_Tulu_3_8是一个多领域数据集,包含8个专门领域的示例,这些示例采用高级聚类技术从Tulu-3 SFT混合数据中自动提取和策划。该数据集适用于针对特定领域的任务进行微调,也支持将多个领域组合起来进行多样化训练。
Clustered_Tulu_3_8 is a multi-domain dataset that contains samples across 8 specialized domains. These samples are automatically extracted and curated from the Tulu-3 SFT mixed dataset using advanced clustering techniques. This dataset is suitable for fine-tuning on domain-specific tasks, and also supports combining multiple domains for diversified training.
创建时间:
2025-07-22
原始信息汇总
Clustered_Tulu_3_8 多领域数据集概述
数据集基本信息
- 许可证: Apache 2.0
- 任务类别: 文本生成
- 语言: 英语 (en)
- 标签: 多领域、指令跟随、对话AI、聚类数据
- 规模: 10K<n<100K
多领域结构
数据集包含8个专业领域的配置,每个配置针对不同类型的任务进行了优化:
| 配置名称 | 领域 | 训练集大小 | 测试集大小 | 总计 |
|---|---|---|---|---|
programming_and_code_development |
编程与代码开发 | 88,783 | 22,196 | 110,979 |
qanda_and_logical_reasoning |
问答与逻辑推理 | 75,223 | 18,806 | 94,029 |
creative_writing_and_general_tasks |
创意写作与通用任务 | 94,802 | 23,701 | 118,503 |
multilingual_and_translation |
多语言与翻译 | 70,396 | 17,600 | 87,996 |
safety_and_harmful_content |
安全与有害内容 | 102,098 | 25,525 | 127,623 |
word_problems_and_arithmetic |
文字问题与算术 | 108,891 | 27,223 | 136,114 |
non-english_mathematics |
非英语数学 | 94,980 | 23,746 | 118,726 |
advanced_mathematics_and_modeling |
高等数学与建模 | 116,266 | 29,067 | 145,333 |
| 总计 | 所有领域 | 751,439 | 187,864 | 939,303 |
数据集结构
每个配置包含相同的结构:
text: 用户提示/指令(主要输入)source: 原始数据集标识符messages: 完整的对话线程与角色original_id: 原始数据集的唯一标识符
数据质量
- 领域聚类: 通过内容相似性自动分组
- 质量过滤: 针对相关性和连贯性进行过滤
- 分层分割: 每个领域80/20的训练/测试分割
- 干净格式: 可直接使用的对话结构
- 一致的模式: 所有配置格式相同
使用案例
- 领域特定训练: 针对特定领域进行微调
- 多领域训练: 结合多个领域进行多样化训练
- 跨领域评估: 在不同领域测试模型性能
来源信息
- 原始数据集: allenai/tulu-3-sft-mixture
- 聚类方法: TF-IDF + K-Means
- 总配置数: 8
- 处理: 自动聚类与手动领域标注
引用
bibtex @dataset{clustered_tulu_3_8_multi_domain, title={Clustered_Tulu_3_8 Multi-Domain Dataset}, author={Extracted from Tulu-3 SFT Mixture}, year={2025}, url={https://huggingface.co/datasets/clustered_tulu_3_8}, note={Multi-domain dataset with 8 specialized configurations} }
许可证
遵循原始Tulu-3 SFT混合数据集的Apache 2.0许可证。
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量领域特定数据的获取至关重要。clustered_tulu_3_8数据集通过先进的TF-IDF和K-Means聚类技术,从原始的Tulu-3 SFT混合数据中自动提取并精心筛选出8个专业领域的数据。构建过程中采用了严格的质量过滤机制,确保数据的相关性和连贯性,同时为每个领域配置了80/20的训练测试分层分割,最终形成包含93万余条样本的跨领域资源。
特点
该数据集最显著的特点在于其精心设计的领域划分结构,涵盖编程开发、逻辑推理、创意写作等8个专业领域。每个领域配置都保持统一的对话结构,包含文本提示、原始来源标识、完整对话线程等丰富字段。数据经过自动聚类和人工标注的双重质量控制,既保证了领域内样本的语义一致性,又通过分层抽样确保了各领域评估集的代表性。
使用方法
研究人员可通过Hugging Face数据集库灵活加载特定领域配置,支持单独使用或跨领域组合。典型应用场景包括:针对编程开发等单一领域的精细调优;通过多领域数据拼接实现模型通用能力提升;以及跨领域配置的系统性评估。数据集采用标准的parquet格式存储,加载接口简洁统一,便于集成到现有训练流程中。
背景与挑战
背景概述
clustered_tulu_3_8数据集是基于Tulu-3 SFT混合数据集构建的多领域文本生成数据集,由AllenAI研究团队于2025年发布。该数据集通过先进的聚类技术自动提取并筛选了8个专业领域的高质量文本样本,涵盖编程开发、逻辑推理、多语言翻译等多样化任务场景。作为指令跟随型对话系统的专用训练资源,其结构化设计显著提升了模型在特定领域的任务适应能力,为对话式AI的领域专业化研究提供了重要基准。
当前挑战
该数据集面临的核心挑战主要体现在领域划分的精确性与数据平衡性两方面。在领域问题层面,如何确保自动聚类算法准确识别跨领域文本的语义边界,避免专业领域间的知识污染,是影响模型专业化的关键因素。在构建过程中,原始数据的噪声过滤、多语言文本的质量控制,以及各领域样本量的均衡分配,均对数据集的实用性构成显著挑战。此外,安全敏感内容的处理机制也需在数据开放性与其潜在风险之间寻求平衡。
常用场景
经典使用场景
在自然语言处理领域,clustered_tulu_3_8数据集凭借其多领域特性,成为训练和评估对话生成模型的理想选择。该数据集特别适用于构建能够理解并响应特定领域指令的对话系统,例如在编程开发领域生成代码建议,或在逻辑推理任务中提供精准答案。其分领域配置的设计允许研究者针对性地优化模型在不同专业场景下的表现。
实际应用
实际应用中,该数据集支撑了智能教育助手、多语言客服系统等产品的开发。其安全与有害内容配置被广泛用于构建内容过滤机制,而编程开发模块则成为代码补全工具的核心训练数据。在金融领域,算术应用题配置帮助训练了自动报表分析系统,展现了强大的跨行业适用性。
衍生相关工作
基于该数据集的经典研究包括多任务学习框架MTL-Transformer,其采用领域特定适配器提升了模型在编程与逻辑推理任务上的联合表现。另有工作提出分层聚类增强方法HCE,通过二次聚类优化了原始数据的领域划分精度,这些创新显著推动了对话系统的专业化发展。
以上内容由遇见数据集搜集并总结生成


