seq_dis_T0.6-Qwen2.5-7B-best_of_n-VLLM-Skywork-o1-Open-PRM-Qwen-2.5-7B-completions
收藏Hugging Face2025-05-17 更新2025-05-18 收录
下载链接:
https://huggingface.co/datasets/mothnaZl/seq_dis_T0.6-Qwen2.5-7B-best_of_n-VLLM-Skywork-o1-Open-PRM-Qwen-2.5-7B-completions
下载链接
链接失效反馈官方服务:
资源简介:
这是一个数学相关的数据集,包含多个特征,如准确率、通过率、n-gram统计等。数据集被划分为了训练集,共有8个示例。数据集的配置名称为mothnaZl_minerva_math--T-0.8--top_p-1.0--n-128--seed-0--agg_strategy-last--merged--evals。
This is a mathematics-focused dataset encompassing multiple features including accuracy, pass rate, n-gram statistics, and others. The dataset is partitioned into a training set consisting of 8 instances. Its configuration name is mothnaZl_minerva_math--T-0.8--top_p-1.0--n-128--seed-0--agg_strategy-last--merged--evals.
创建时间:
2025-05-13
原始信息汇总
数据集概述
基本信息
- 数据集名称: seq_dis_T0.6-Qwen2.5-7B-best_of_n-VLLM-Skywork-o1-Open-PRM-Qwen-2.5-7B-completions
- 配置名称: mothnaZl_minerva_math--T-0.8--top_p-1.0--n-128--seed-0--agg_strategy-last--merged--evals
- 下载大小: 6643字节
- 数据集大小: 864字节
- 训练集样本数: 8
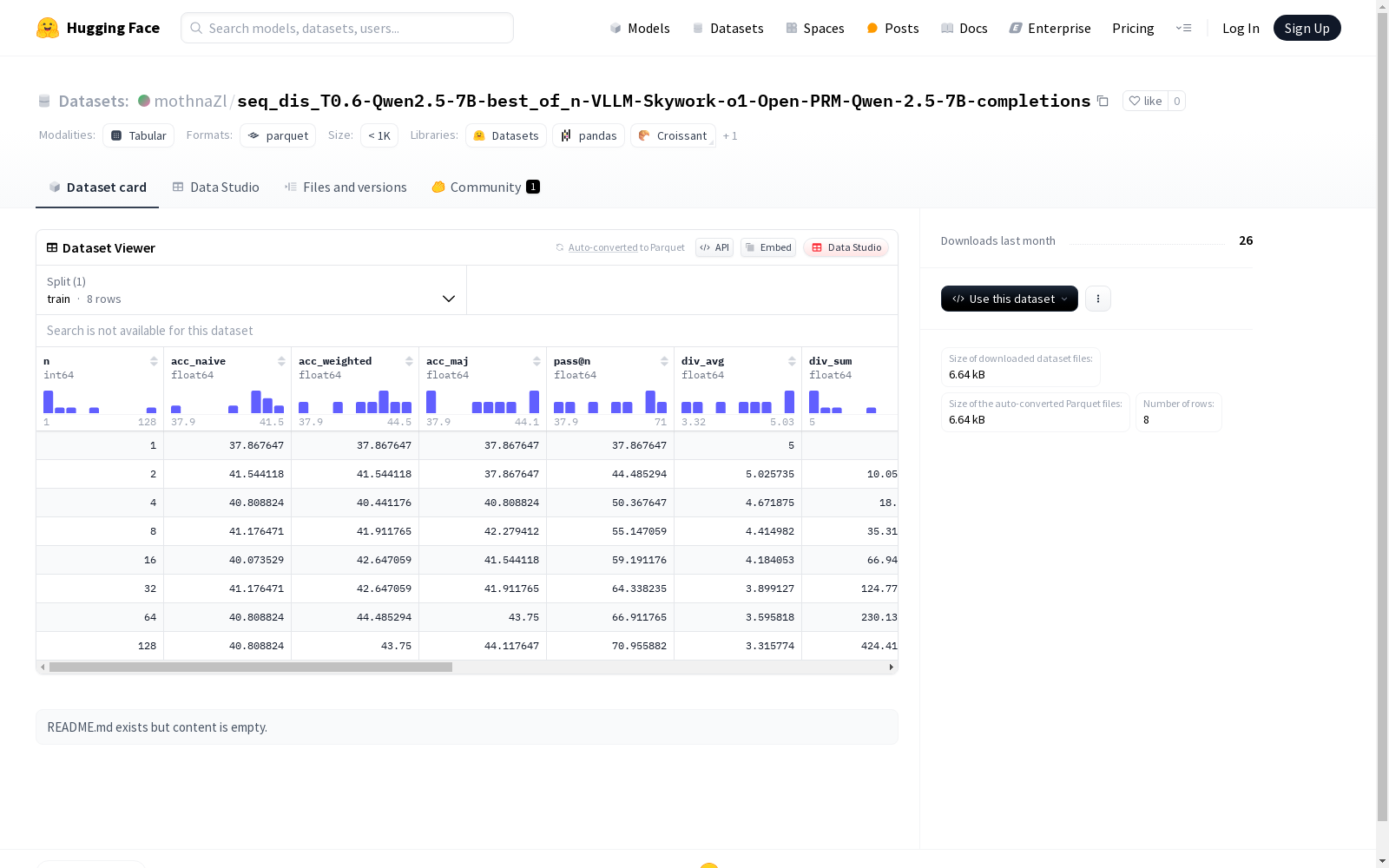
特征列
- n: int64
- acc_naive: float64
- acc_weighted: float64
- acc_maj: float64
- pass@n: float64
- div_avg: float64
- div_sum: float64
- div_mean: float64
- Unigrams: float64
- Bigrams: float64
- Trigrams: float64
- Fourgrams: float64
- pass_tag: sequence (null)
- BM25: int64
数据拆分
- 训练集: 包含8个样本,大小为864字节
搜集汇总
数据集介绍
构建方式
在自然语言处理领域,高质量数据集的构建对模型评估至关重要。该数据集采用温度参数0.8的采样策略,通过top-p值为1.0的核采样方法生成128个候选序列,并运用基于最后层聚合策略的评估框架。原始数据经过严谨的合并处理流程,确保了评估结果的可靠性。
特点
作为专门用于评估语言模型数学推理能力的基准数据集,其特色在于包含多维度评估指标。除基础的准确率指标外,还创新性地整合了n-gram多样性分析、BM25相关性评分以及通过率等复合指标。8个训练样本虽规模精炼,但每个样本都经过128次重复采样,为模型稳定性分析提供了充分数据支持。
使用方法
研究者可通过加载标准化的HuggingFace数据集接口快速获取该资源。数据以结构化形式存储,包含训练集分割,支持直接调用各项评估指标进行横向对比分析。建议重点关注pass@n和多样性指标的组合使用,这些参数能有效反映模型在数学问题求解中的创造性和稳定性表现。
背景与挑战
背景概述
该数据集聚焦于自然语言处理领域中的序列生成与评估问题,由研究团队基于Qwen2.5-7B等先进语言模型构建而成。其核心研究目标在于探索多样化生成策略对模型输出的影响,通过引入温度参数调控、Top-p采样等技术手段,系统评估生成文本的准确性、多样性和通过率等关键指标。数据集的设计体现了当前大语言模型研究的前沿方向,为生成质量优化、采样策略比较等关键问题提供了量化分析框架。
当前挑战
数据集构建面临双重技术挑战:在领域问题层面,需解决生成文本质量评估的多维度平衡问题,包括准确率与多样性的权衡、n-gram重复率控制等;在构建过程层面,技术难点集中于大规模生成结果的自动化评估流水线设计,特别是对128组并行生成样本的差异性量化,以及基于BM25算法的语义相似度计算优化。评估指标的鲁棒性验证和计算效率提升构成主要工程瓶颈。
常用场景
经典使用场景
在自然语言处理领域,seq_dis_T0.6-Qwen2.5-7B-best_of_n-VLLM-Skywork-o1-Open-PRM-Qwen-2.5-7B-completions数据集被广泛应用于语言模型的多样性与准确性评估。该数据集通过记录不同n值下的准确率、多样性和通过率等指标,为研究人员提供了丰富的实验数据,用于分析模型在生成任务中的表现。特别是在多候选生成场景下,该数据集能够帮助研究者深入理解模型的行为模式。
实际应用
在实际应用中,该数据集被广泛用于优化对话系统和文本生成模型的性能。通过分析数据集中的多样性和准确性指标,开发者能够调整模型参数,提升生成内容的质量和多样性。例如,在智能客服和内容创作工具中,该数据集的应用显著提高了用户体验和生成内容的实用性。
衍生相关工作
基于该数据集,许多经典研究工作得以展开,特别是在语言模型评估和优化领域。例如,一些研究利用该数据集中的多样性指标,提出了新的评估方法,进一步推动了生成模型的多样性研究。此外,该数据集还被用于开发新的生成策略,如基于多候选生成的优化算法,显著提升了模型在实际任务中的表现。
以上内容由遇见数据集搜集并总结生成


