tanganke/kmnist
收藏Hugging Face2024-05-02 更新2024-06-12 收录
下载链接:
https://hf-mirror.com/datasets/tanganke/kmnist
下载链接
链接失效反馈官方服务:
资源简介:
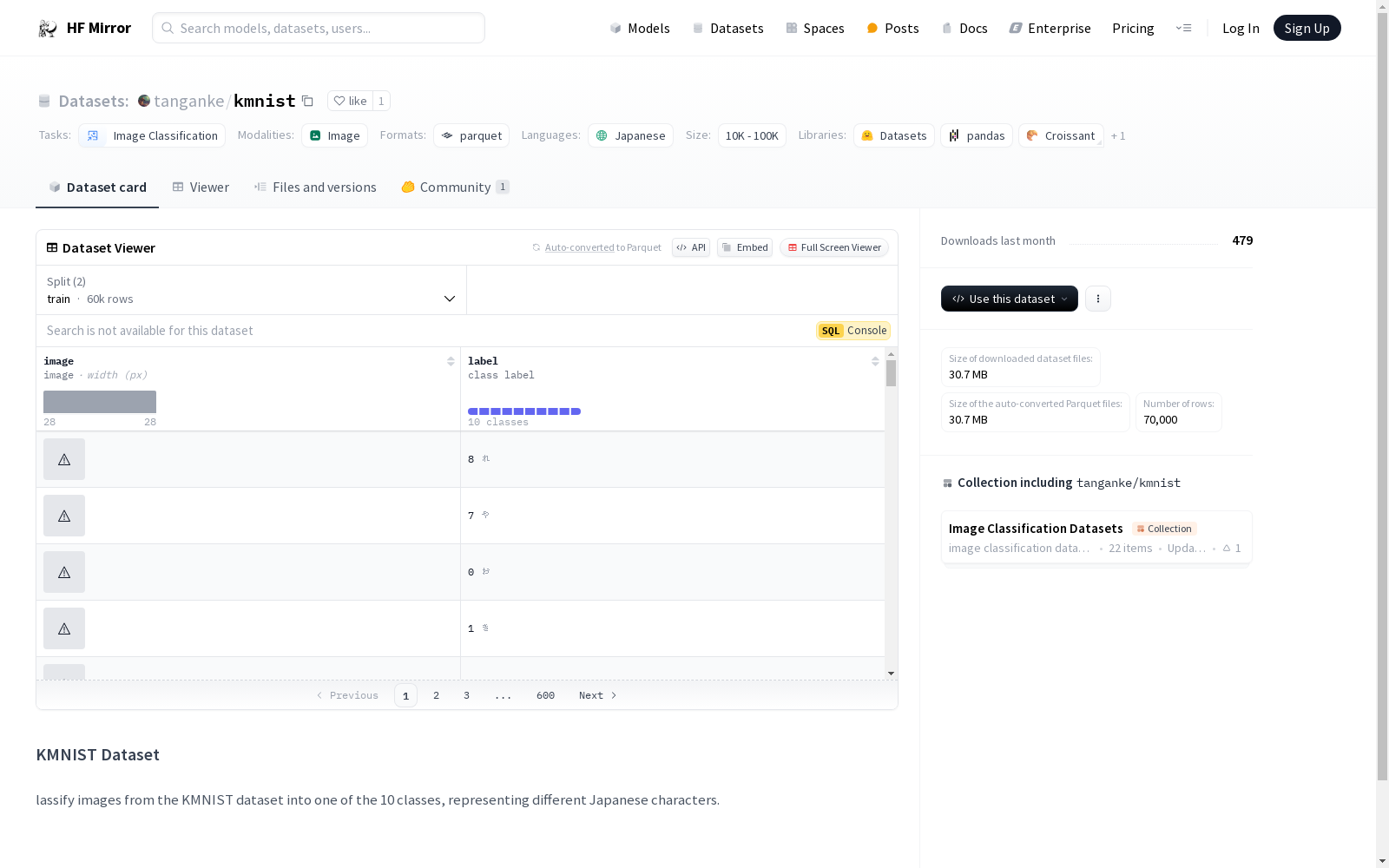
KMNIST数据集用于将图像分类为10个类别,每个类别代表不同的日本字符。数据集包含训练集和测试集,分别有60000和10000个样本。
KMNIST数据集用于将图像分类为10个类别,每个类别代表不同的日本字符。数据集包含训练集和测试集,分别有60000和10000个样本。
提供机构:
tanganke
原始信息汇总
KMNIST 数据集概述
基本信息
- 语言: 日语
- 数据集大小: 10K<n<100K
- 任务类型: 图像分类
数据集配置
- 配置名称: kmnist
数据集特征
- 图像: 数据类型为图像
- 标签: 数据类型为类别标签,包含10个类别,分别对应以下日语字符:
- 0: お
- 1: き
- 2: す
- 3: つ
- 4: な
- 5: は
- 6: ま
- 7: や
- 8: れ
- 9: を
数据集分割
- 训练集:
- 样本数量: 60000
- 数据大小: 26807717.0字节
- 测试集:
- 样本数量: 10000
- 数据大小: 4478963.0字节
数据集大小
- 下载大小: 30674033字节
- 数据集总大小: 31286680.0字节
数据文件配置
- 配置名称: kmnist
- 数据文件路径:
- 训练集: kmnist/train-*
- 测试集: kmnist/test-*
- 默认配置: 是
搜集汇总
数据集介绍
构建方式
KMNIST数据集的构建基于日本手写字符的图像分类任务,涵盖了10个不同的日文字符。数据集通过精心挑选和标注,确保每个字符的图像质量高且代表性强。训练集包含60,000张图像,测试集包含10,000张图像,每张图像均以28x28像素的灰度格式存储,便于模型训练和评估。
特点
KMNIST数据集的主要特点在于其专注于日本手写字符的识别,填补了现有数据集中对日文字符覆盖不足的空白。数据集的图像分辨率适中,既保证了图像细节的清晰度,又降低了计算复杂度。此外,数据集的标签体系简洁明了,便于模型快速学习和分类。
使用方法
使用KMNIST数据集时,用户可以通过加载预定义的训练和测试集进行模型训练和评估。数据集支持多种深度学习框架,用户可以根据需要选择合适的工具进行图像分类模型的开发。建议在训练过程中采用数据增强技术,以提高模型的泛化能力。
背景与挑战
背景概述
KMNIST数据集,由tanganke创建,专注于日本手写字符的图像分类任务。该数据集包含60,000个训练图像和10,000个测试图像,每个图像对应10个不同的日本字符类别。KMNIST的开发旨在为机器学习研究提供一个标准化的基准,特别是在处理非拉丁字符集时。通过提供高质量的图像数据,KMNIST促进了对手写字符识别技术的深入研究,为相关领域的算法优化和模型训练提供了宝贵的资源。
当前挑战
KMNIST数据集在图像分类领域面临若干挑战。首先,日本手写字符的复杂性和多样性增加了分类的难度,要求模型具备高度的特征提取能力。其次,数据集的构建过程中,确保图像质量和标注准确性是一个重要挑战,任何错误或噪声都可能影响模型的性能。此外,由于数据集规模相对较小,如何有效利用有限的数据进行模型训练,避免过拟合,也是一个关键问题。
常用场景
经典使用场景
在图像分类领域,tanganke/kmnist数据集被广泛用于训练和评估模型对日本手写字符的识别能力。该数据集包含60,000张训练图像和10,000张测试图像,每张图像对应一个特定的日本字符。通过使用该数据集,研究人员能够开发和优化深度学习模型,以提高对手写字符的分类准确性。
解决学术问题
tanganke/kmnist数据集解决了在手写字符识别领域中,传统数据集如MNIST在字符多样性和文化代表性上的不足。通过引入日本手写字符,该数据集为研究者提供了一个更具挑战性和文化相关性的基准,促进了跨文化字符识别技术的研究和发展。
衍生相关工作
基于tanganke/kmnist数据集,研究者们开发了多种改进的手写字符识别模型,如卷积神经网络(CNN)和循环神经网络(RNN)的变体。此外,该数据集还激发了对多语言字符识别系统的研究,推动了跨文化字符识别技术的进步。
以上内容由遇见数据集搜集并总结生成


