clips/mqa
收藏Hugging Face2022-09-27 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/clips/mqa
下载链接
链接失效反馈官方服务:
资源简介:
MQA是一个多语言的问答数据集,包含FAQ(常见问题)和CQA(社区问答)两种类型的问题。数据集来源于Common Crawl,涵盖了39种语言,总计约234M对问答。FAQ和CQA问题的结构相似,但CQA问题可能有多个答案,而FAQ问题通常只有一个答案。数据集支持三种嵌套级别:问题、页面和域。
MQA is a multilingual question answering dataset containing two types of questions: FAQ (Frequently Asked Questions) and CQA (Community Question Answering). The dataset is sourced from Common Crawl, covers 39 languages, and contains approximately 234 million question-answer pairs in total. The structures of FAQ and CQA questions are similar, while CQA questions may have multiple answers whereas FAQ questions typically have only one answer. The dataset supports three nested levels: question, page, and domain.
提供机构:
clips
原始信息汇总
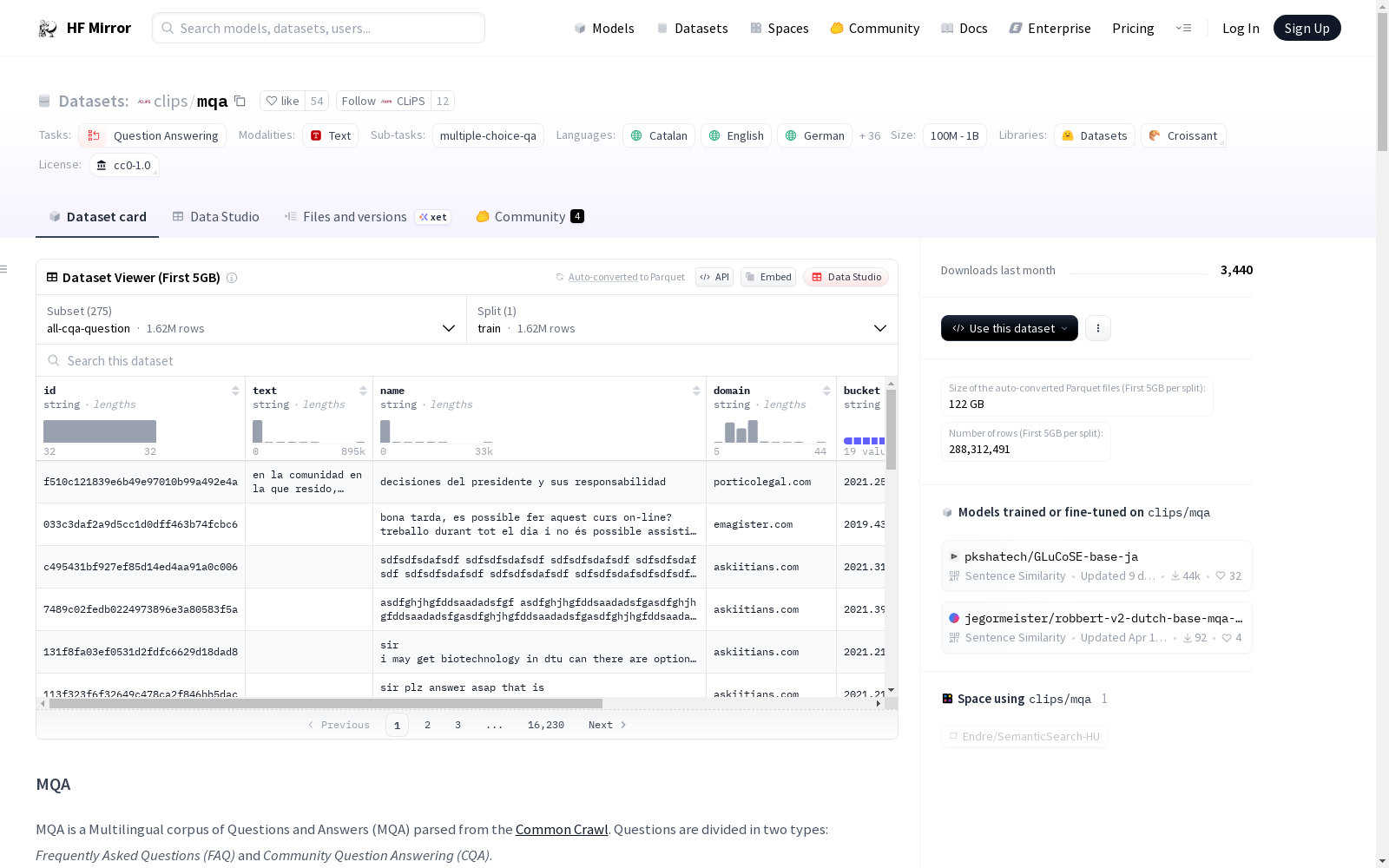
数据集概述
名称: MQA - a Multilingual FAQ and CQA Dataset
语言: 包含39种语言,包括但不限于英语(en)、德语(de)、西班牙语(es)、法语(fr)、俄语(ru)、日语(ja)、中文(zh)等。
许可证: 数据集遵循CC0-1.0许可证。
多语言性: 支持多语言。
数据集大小: 数据集大小未明确,但包含约234M对问题和答案。
源数据: 数据集来源于Common Crawl的WARC文件。
任务类型: 主要用于问答任务,包括多选题问答(multiple-choice-qa)。
数据集结构
问题类型: 数据集分为两种类型:
- Frequently Asked Questions (FAQ): 通常只有一个答案。
- Community Question Answering (CQA): 可以有多个答案。
数据字段:
- name: 问题的标题(如果有)。
- text: 问题的正文(如果有)。
- answers: 答案列表,每个答案包含:
- text: 答案的文本。
- is_accepted: 布尔值,表示答案是否被接受。
下载和使用
下载方式: 可以通过指定语言和问题类型(FAQ或CQA)来下载数据集的子集。例如: python load_dataset("clips/mqa", language="en", scope="faq")
数据集层次: 数据集支持三种不同的嵌套级别:
- question: 默认级别,提供单个问题的详细信息。
- page: 提供同一页上的问题列表。
- domain: 提供同一域名下的页面列表。
语言分布
数据集在不同语言中的问题和答案分布如下:
| Language | FAQ | CQA |
|---|---|---|
| en | 174,696,414 | 14,082,180 |
| de | 17,796,992 | 1,094,606 |
| es | 14,967,582 | 845,836 |
| fr | 13,096,727 | 1,299,359 |
| ... | ... | ... |
此表格展示了每种语言在FAQ和CQA中的数据量。
搜集汇总
数据集介绍
构建方式
MQA数据集的构建是基于Common Crawl的非营利组织所提供的丰富的网络爬取数据。研究者们从Common Crawl的WARC文件中提取出多语种的问答对,将其分为常见问题解答(FAQ)和社区问题解答(CQA)两大类,形成了这一多元化的多语言问答数据集。
使用方法
用户可以通过指定语言和问题类型(FAQ或CQA)来下载数据集的子集。数据集支持三种不同的嵌套级别:问题级别、页面级别和域级别,用户可以根据自己的研究需求选择合适的数据结构。通过HuggingFace的datasets库,可以轻松加载和利用这些数据进行多种问答任务的训练和评估。
背景与挑战
背景概述
MQA数据集,全称为Multilingual FAQ and CQA Dataset,是由Maxime De Bruyn、Ehsan Lotfi、Jeska Buhmann和Walter Daelemans等研究人员开发的多语言问答数据集。该数据集创建于2021年,基于Common Crawl的网页数据构建而成,包含大约234M对的问题和答案,覆盖39种语言。MQA数据集旨在为机器阅读理解领域提供支持,特别是针对频繁问及的问题(FAQ)和社区问答(CQA)两种类型的问题。该数据集的发布,对于促进多语言问答系统的研究和开发具有显著的影响力和价值。
当前挑战
MQA数据集在构建过程中遇到的挑战主要包括数据的多语言性质带来的处理难度,以及从非结构化数据中提取结构化问答对的复杂性。此外,数据集的质量控制也是一个挑战,需要确保从Common Crawl中提取的数据是准确和可靠的。在研究领域,该数据集面临的挑战包括如何有效地利用这些大规模数据进行模型训练,以及如何处理数据中的噪声和偏差,确保模型能够在实际应用中表现出色。
常用场景
经典使用场景
在自然语言处理与信息检索领域,MQA数据集以其多语种特性,成为研究者在进行跨语言问答系统开发时的宝贵资源。该数据集整合了常见问题解答(FAQ)与社区问题回答(CQA)两种类型的问题,为研究者提供了一个全面的问题-答案对库,以便训练和评估多语言问答模型。
解决学术问题
MQA数据集解决了多语言环境下,如何有效构建和利用大规模问题-答案对的问题。它的存在促进了多语言信息检索、自然语言理解和机器翻译等领域的学术研究,使得研究者在处理多语言数据时,能够更加精确地捕捉用户的查询意图,并给出恰当的回答。
实际应用
在实用层面,MQA数据集可以被用于构建和优化多语言客户服务系统,如自动问答机器人,能够帮助企业在全球范围内提供更为高效和精准的客户支持服务。此外,该数据集还能助力教育领域,为多语言学习提供丰富的语料资源。
数据集最近研究
最新研究方向
MQA数据集作为多语言的问题与答案语料库,近期在自然语言处理领域的研究方向主要集中在多语言问答系统的构建与优化。该数据集的多样性和规模为研究提供了丰富的资源,特别是在处理跨语言信息检索和机器翻译任务中展现出显著的优势。当前研究的热点事件包括如何利用MQA数据集进行端到端的多语言问答系统开发,以及如何在保持高准确率的同时,提升系统的响应速度和可解释性。这些研究对于推动全球化背景下的智能信息检索技术的发展具有重要的意义和影响。
以上内容由遇见数据集搜集并总结生成


