fdp-662-grape-ultrachat-sft-Olmo-3-1025-7B
收藏Hugging Face2026-05-10 更新2026-05-11 收录
下载链接:
https://huggingface.co/datasets/ryanaswift7/fdp-662-grape-ultrachat-sft-Olmo-3-1025-7B
下载链接
链接失效反馈官方服务:
资源简介:
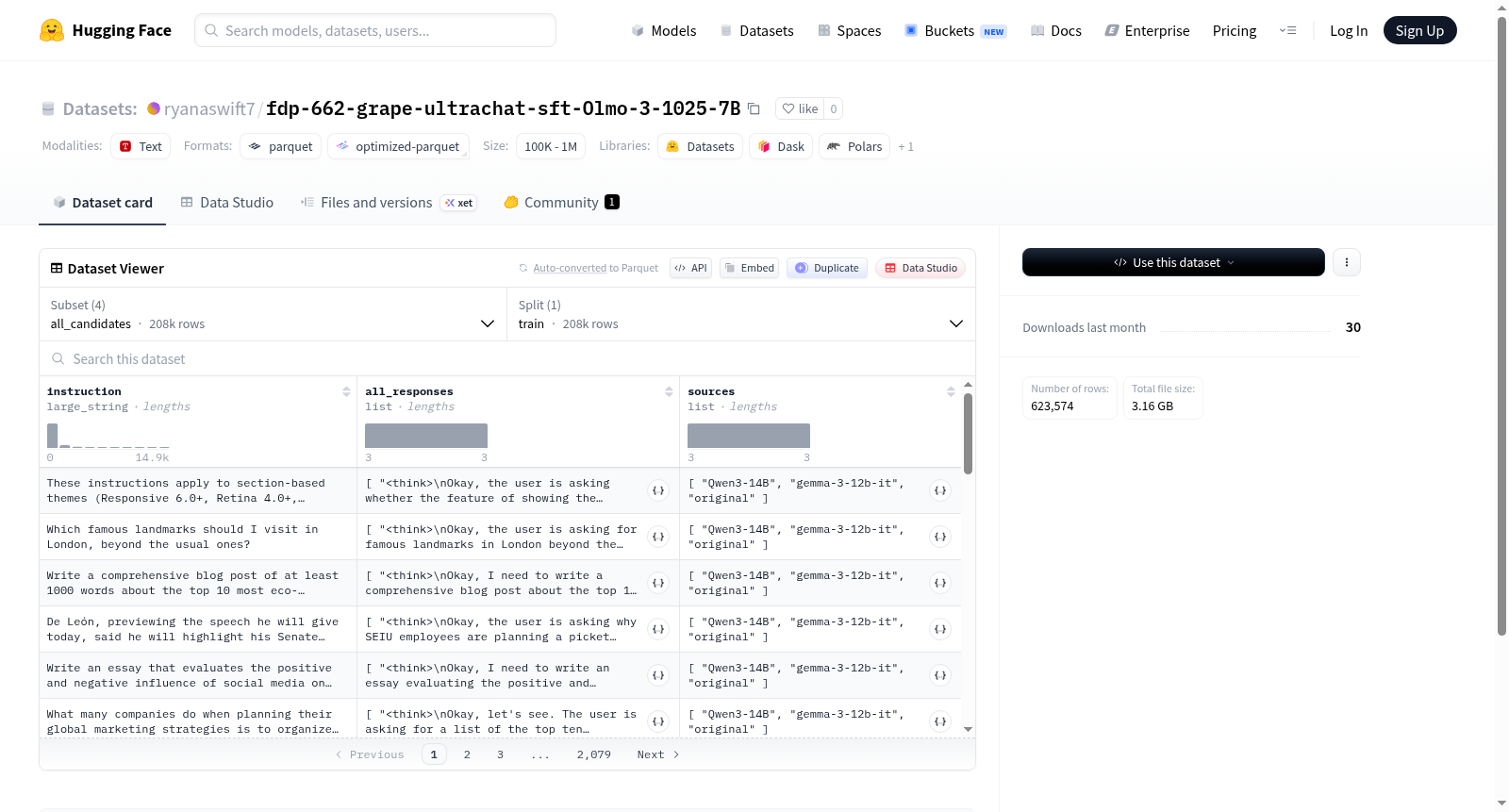
该数据集包含四种配置:all_candidates、teacher_Qwen3-14B、teacher_gemma-3-12b-it和teacher_original。all_candidates配置包含指令-响应对及数据来源,具体特征包括指令文本(instruction)、所有响应列表(all_responses)和来源列表(sources)。其他三种教师模型配置均采用对话消息格式,由角色(role)和内容(content)组成的消息列表(messages)构成。所有配置均仅包含训练集(train),样本量在207,844至207,865之间,数据规模从525MB到1.43GB不等。该数据集适用于对话系统训练、响应生成评估等自然语言处理任务。
This dataset includes four configurations: all_candidates, teacher_Qwen3-14B, teacher_gemma-3-12b-it, and teacher_original. The all_candidates configuration contains instruction-response pairs and data sources, with specific features including the instruction text field (`instruction`), list of all responses (`all_responses`), and list of sources (`sources`). The other three teacher model configurations adopt the conversational message format, which consists of a list of messages (`messages`) each composed of a role (`role`) and content (`content`). All configurations only include the training split (`train`), with the number of samples ranging from 207,844 to 207,865, and the data size varying between 525 MB and 1.43 GB. This dataset is suitable for natural language processing tasks such as conversational system training and response generation evaluation.
创建时间:
2026-05-09
原始信息汇总
根据您提供的Hugging Face数据集页面信息,以下是对该数据集的结构化总结:
数据集名称
ryanaswift7/fdp-662-grape-ultrachat-sft-Olmo-3-1025-7B
数据集概述
该数据集是一个用于监督微调(SFT)的多教师对话数据集,包含多个配置(config),每个配置对应不同的教师模型生成的对话数据。所有数据仅包含训练集(train split)。
数据集配置与详情
1. 配置:all_candidates
- 目的:存储所有候选响应和来源信息。
- 特征:
instruction(字符串):指令文本。all_responses(字符串列表):所有候选响应。sources(字符串列表):响应来源。
- 数据规模:
- 训练样本数:207,844
- 数据集大小:1.43 GB
- 下载大小:1.36 GB
2. 配置:teacher_Qwen3-14B
- 目的:使用Qwen3-14B模型作为教师生成的对话数据。
- 特征:
messages(列表):包含role(角色)和content(内容)的对话消息。
- 数据规模:
- 训练样本数:207,865
- 数据集大小:691 MB
- 下载大小:690 MB
3. 配置:teacher_gemma-3-12b-it
- 目的:使用Gemma-3-12B-it模型作为教师生成的对话数据。
- 特征:
messages(列表):包含role和content的对话消息。
- 数据规模:
- 训练样本数:207,865
- 数据集大小:582 MB
- 下载大小:581 MB
4. 配置:teacher_original
- 目的:原始教师模型的对话数据。
- 特征:
messages(列表):包含role和content的对话消息。
- 数据规模:
- 训练样本数:207,844
- 数据集大小:526 MB
- 下载大小:525 MB
数据文件结构
数据集以Parquet格式按配置分目录存储,路径规则如下:
all_candidates/train-*teacher_Qwen3-14B/train-*teacher_gemma-3-12b-it/train-*teacher_original/train-*
关键统计
- 总样本数:每个配置约20.7万条训练样本。
- 总下载大小:所有配置合计约3.16 GB。
- 总数据集大小:所有配置合计约3.33 GB。
搜集汇总
数据集介绍
构建方式
该数据集源于对大规模对话数据的精细加工,旨在提升语言模型的指令遵循能力。其构建过程首先从原始语料中提取指令及其对应的多源响应,形成`all_candidates`配置,其中每条样本包含一条指令、多个候选回答及对应的来源标识。随后,基于教师蒸馏策略,分别利用`Qwen3-14B`与`gemma-3-12b-it`等高性能模型对原始指令进行重新回答,生成新的对话序列,从而构成`teacher_Qwen3-14B`和`teacher_gemma-3-12b-it`两个配置,同时保留了原始的`teacher_original`配置作为基准。所有配置均以对话消息格式存储,便于直接用于序列到序列的训练。
使用方法
使用该数据集时,研究人员可根据任务需求灵活选择配置。如需进行多源对比学习,可加载`all_candidates`配置,利用其指令与多候选结构进行偏好排序或对比训练。若侧重于知识蒸馏,则可选取`teacher_Qwen3-14B`或`teacher_gemma-3-12b-it`配置,将教师模型的完整对话作为监督信号,指导学生模型的生成。所有数据均以Parquet格式分片存储,通过HuggingFace Datasets库的`load_dataset`函数即可按配置名称直接加载训练集。数据字段遵循标准对话格式,无需额外预处理即可适配常见的聊天模型训练流程。
背景与挑战
背景概述
fdp-662-grape-ultrachat-sft-Olmo-3-1025-7B数据集由相关研究机构构建,旨在为大型语言模型的指令微调提供高质量的训练语料。该数据集以UltraChat为基础,通过引入多个教师模型(如Qwen3-14B、Gemma-3-12b-it)生成多样化响应,并保留原始指令来源,形成一个包含约20.8万条样本的多候选者指令微调集合。其核心研究问题在于探索如何利用不同规模的教师模型知识蒸馏与对比学习,提升小参数模型(如Olmo-3-1025-7B)的对话生成能力。该数据集的发布对指令微调领域的知识迁移与模型压缩研究具有重要参考价值,推动了高效语言模型训练范式的演进。
当前挑战
该数据集所解决的领域问题在于指令微调中响应质量与多样性的平衡挑战。传统单教师蒸馏易导致模型输出同质化,而该数据集体通过整合多个教师模型的不同风格响应,增加了训练数据的信息熵,促使学生模型学习更丰富的对话策略。在构建过程中,面临多源响应一致性控制、噪声过滤以及跨模型输出格式对齐等难题,例如不同教师模型的输出长度、语气与事实准确性差异需通过精细的清洗策略进行协调。此外,如何在保持原始指令完整性的前提下,高效存储与管理超过13亿字节的多候选数据结构,也对数据处理流水线的鲁棒性与扩展性提出了较高要求。
常用场景
经典使用场景
fdp-662-grape-ultrachat-sft-Olmo-3-1025-7B数据集在大型语言模型的监督微调(SFT)流程中扮演着关键角色。该数据集汇集了多个教师模型(如Qwen3-14B、Gemma-3-12b-it及原版UltraChat模型)对同一组指令生成的多样化响应,构成了一个跨模型、多视角的训练语料库。经典的使用方式是将其作为微调基座模型(如OLMo-3)的指令跟随数据,通过纳入不同规模与架构的教师输出,增强学生模型对指令理解与回应的鲁棒性,从而在对话质量、知识准确性与生成多样性上取得显著提升,是构建高质量对话代理的重要数据基石。
解决学术问题
该数据集致力于解决大语言模型在对齐训练中因依赖单一教师模型而导致的响应风格固化与知识偏差问题。在学术研究中,利用多个教师模型(包括14B级别与12B级别的先进模型)的输出作为训练信号,能够有效探索模型集成的知识蒸馏路径,缓解单一教师可能带来的偏好偏见。同时,通过对比不同教师对相同指令的回应差异,研究者可以深入分析模型能力边界与知识分布差异,为理解大规模语言模型的容量扩展、对齐策略与泛化能力提供了宝贵的实验素材与基准平台。
实际应用
实际应用中,fdp-662-grape-ultrachat-sft-Olmo-3-1025-7B数据集主要服务于对话系统、智能客服与教育辅导等需要高质量人机交互的领域。开发者可基于不同教师配置的响应集合,训练出更善于处理开放域对话、复杂知识问答及多轮交互的聊天机器人,提升其在用户意图捕捉、逻辑连贯性与回答可信度上的表现。此外,该数据集也可用于生成个性化对话模型,通过选择特定风格或领域的教师输出作为蓝本,使微调后的模型在特定场景下的回应更加贴合人类期待。
数据集最近研究
最新研究方向
在大型语言模型的演进浪潮中,该数据集聚焦于知识蒸馏与多教师协同的精妙融合,代表了指令微调领域的前沿探索。研究的热点在于如何借助 Qwen3-14B、Gemma-3-12B 等高级教师模型,对 Olmo-3 系列基础模型进行深度对齐与性能提升。通过构建包含多源候选响应与原始指令的丰富语料,数据集为对比学习与偏好优化提供了肥沃土壤,推动了从单一教师向多视角知识迁移的范式转变。这一工作不仅显著降低了模型训练成本,更在推理效率和生成质量之间取得了优雅平衡,对于构建更轻量、更强大的开放语言模型具有里程碑式的意义。
以上内容由遇见数据集搜集并总结生成


