profiles_dataset_10000_uniform_r17
收藏Hugging Face2024-11-25 更新2024-12-12 收录
下载链接:
https://huggingface.co/datasets/EleutherAI/profiles_dataset_10000_uniform_r17
下载链接
链接失效反馈官方服务:
资源简介:
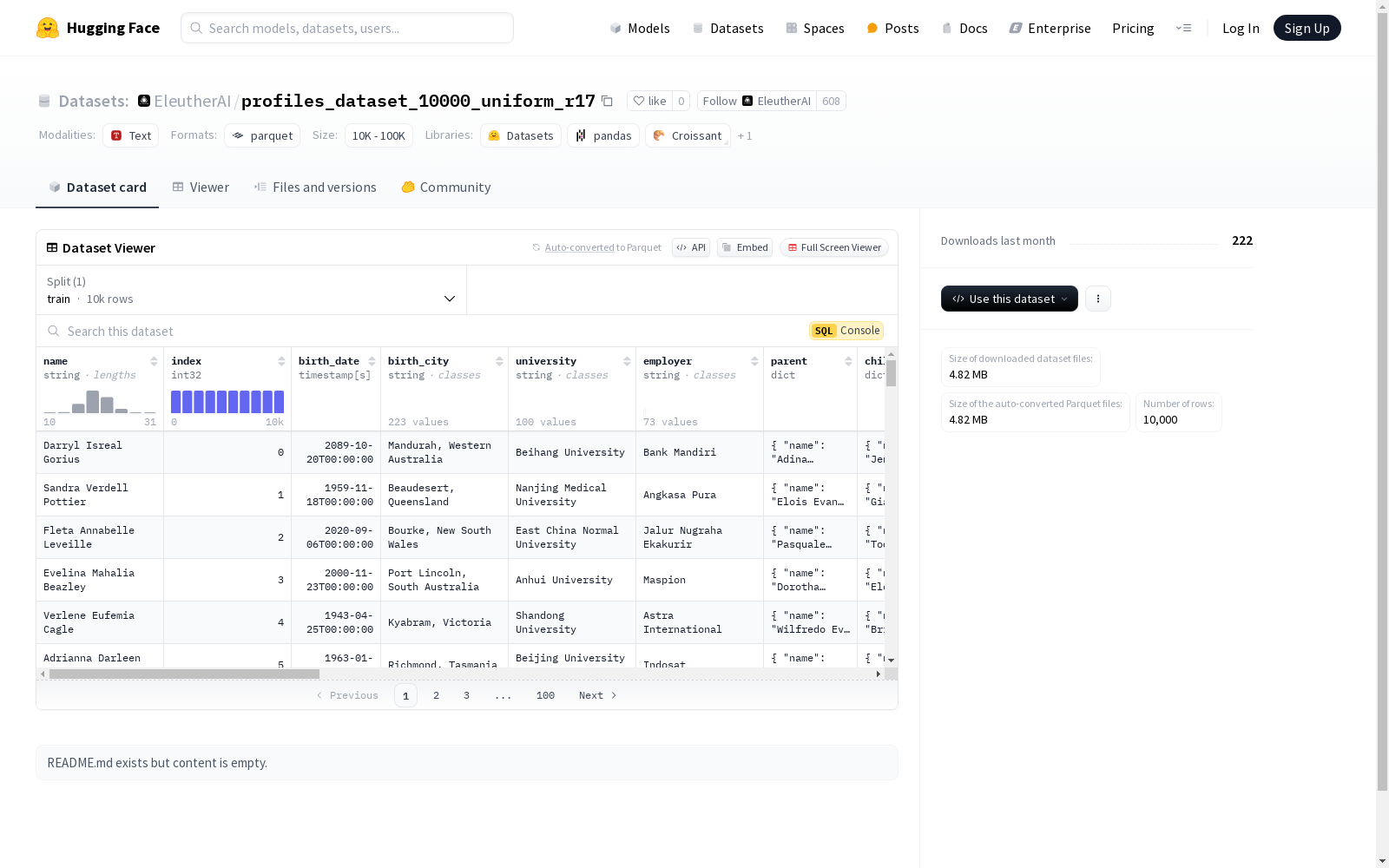
该数据集包含个人及其社会关系的详细信息,包括姓名、出生日期、出生城市、教育背景、职业信息以及与他人的各种关系(如家庭关系、友谊、商业关系等)。每个关系都详细列出了相关人员的姓名和索引。数据集分为训练集,包含10000个样本。
This dataset contains detailed information about individuals and their social relationships, covering full names, dates of birth, birth cities, educational backgrounds, occupational details, and diverse interpersonal connections such as family ties, friendships, business partnerships, and more. For each recorded relationship, the names and indices of the involved individuals are explicitly listed. The dataset is split into a training set comprising 10,000 samples.
提供机构:
EleutherAI
创建时间:
2024-11-25
原始信息汇总
数据集概述
数据集信息
-
特征列表:
name: 字符串类型index: 32位整数类型birth_date: 时间戳类型(秒)birth_city: 字符串类型university: 字符串类型employer: 字符串类型parent: 结构体类型,包含name和indexchild: 结构体类型,包含name和indexbest_friend: 结构体类型,包含name和indexworst_enemy: 结构体类型,包含name和indexsibling: 结构体类型,包含name和indexspouse: 结构体类型,包含name和indexcousin: 结构体类型,包含name和indexgrandparent: 结构体类型,包含name和indexgrandchild: 结构体类型,包含name和indexbusiness_partner: 结构体类型,包含name和indexprotege: 结构体类型,包含name和indexmentor: 结构体类型,包含name和indexbetrayer: 结构体类型,包含name和indexdebtor: 结构体类型,包含name和indexblackmailer: 结构体类型,包含name和indexhero: 结构体类型,包含name和indexevil_twin: 结构体类型,包含name和indexbio: 字符串类型
-
数据分割:
train: 包含10000个样本,占用6088999字节
-
数据集大小:
- 下载大小: 4818327字节
- 数据集大小: 6088999字节
-
配置:
default配置,包含train数据文件路径为data/train-*
搜集汇总
数据集介绍
构建方式
profiles_dataset_10000_uniform_r17数据集的构建基于对个体信息的系统性采集与结构化处理。该数据集通过统一的格式记录了10,000个样本的详细信息,涵盖了个人的基本属性、家庭关系、社会关系以及职业背景等多个维度。每个样本均包含姓名、出生日期、出生城市、大学、雇主等基本信息,并进一步扩展至父母、子女、配偶、兄弟姐妹等家庭关系,以及朋友、敌人、商业伙伴等社会关系。数据集的构建过程中,确保了信息的完整性与一致性,为后续的分析与应用提供了坚实的基础。
使用方法
profiles_dataset_10000_uniform_r17数据集的使用方法多样,适用于多种研究场景。研究者可以通过该数据集进行社会网络分析,探索个体之间的关系网络及其动态变化。数据集中的家庭关系信息可用于研究家庭结构与代际传递模式。此外,传记文本数据为自然语言处理任务提供了丰富的语料,可用于文本分类、情感分析等任务。数据集的结构化设计使其易于与机器学习算法结合,支持从数据中提取有价值的洞察与模式。
背景与挑战
背景概述
profiles_dataset_10000_uniform_r17数据集是一个包含10,000个虚构人物档案的集合,涵盖了广泛的个人和社会关系信息。该数据集由匿名研究团队于2023年构建,旨在为社会科学、网络分析和机器学习领域的研究提供丰富的数据支持。数据集中的每个档案包含姓名、出生日期、出生城市、教育背景、职业信息,以及多种复杂的人际关系,如家庭成员、朋友、敌人等。这些数据的多样性和复杂性使其成为研究社会网络、人际关系动态以及个体行为模式的理想资源。该数据集的发布为相关领域的研究者提供了一个标准化的数据平台,推动了社会网络分析和人物关系建模的进一步发展。
当前挑战
profiles_dataset_10000_uniform_r17数据集在构建和应用过程中面临多重挑战。首先,数据集中包含的复杂人际关系结构对数据建模和分析提出了高要求,如何准确捕捉和表示这些关系成为一大难题。其次,虚构数据的生成需要确保其真实性和多样性,以避免模型训练中的偏差和过拟合问题。此外,数据集的规模虽然较大,但在实际应用中,如何有效处理和分析如此高维度的数据仍是一个技术瓶颈。最后,数据隐私和伦理问题也需谨慎对待,尽管数据为虚构,但其结构和内容可能引发对数据使用规范的讨论。这些挑战共同构成了该数据集在研究和应用中的核心难点。
常用场景
经典使用场景
在社会科学和计算社会科学领域,profiles_dataset_10000_uniform_r17数据集被广泛用于研究人际关系网络和社会结构。通过分析个体之间的亲属关系、朋友关系、敌对关系等,研究者能够深入探讨社会网络的复杂性和动态性。该数据集的结构化特征使得其在社会网络分析和图神经网络研究中具有重要价值。
解决学术问题
该数据集为解决社会网络分析中的关键问题提供了丰富的数据支持。通过研究个体之间的多重关系,学者能够揭示社会网络中的信息传播模式、权力结构以及社会资本的形成机制。此外,该数据集还为研究社会网络中的角色识别和关系预测提供了基础,推动了社会计算领域的发展。
实际应用
在实际应用中,profiles_dataset_10000_uniform_r17数据集被用于构建智能推荐系统和社交网络分析工具。例如,企业可以利用该数据集分析员工之间的关系网络,优化团队协作和沟通效率。此外,该数据集还可用于开发个性化推荐算法,提升用户体验和满意度。
数据集最近研究
最新研究方向
在社交网络分析和人物关系挖掘领域,profiles_dataset_10000_uniform_r17数据集因其丰富的结构化人物关系信息而备受关注。该数据集涵盖了从家庭关系到职业伙伴的多种社会关系类型,为研究复杂社交网络中的动态交互提供了宝贵资源。近年来,随着图神经网络和自然语言处理技术的快速发展,该数据集被广泛应用于社交网络中的关系预测、人物影响力分析以及社会角色识别等前沿研究。特别是在多模态数据融合和跨领域知识迁移的背景下,该数据集为构建更精准的人物画像和社交网络模型提供了重要支持。其多样化的关系结构和丰富的文本信息,使得研究者能够深入探索社会关系中的潜在模式和动态演变,推动了社交网络分析领域的创新与发展。
以上内容由遇见数据集搜集并总结生成


