Oxford-IIIT Pet Dataset
收藏Papers with Code2024-05-15 收录
下载链接:
https://paperswithcode.com/dataset/oxford-iiit-pets
下载链接
链接失效反馈资源简介:
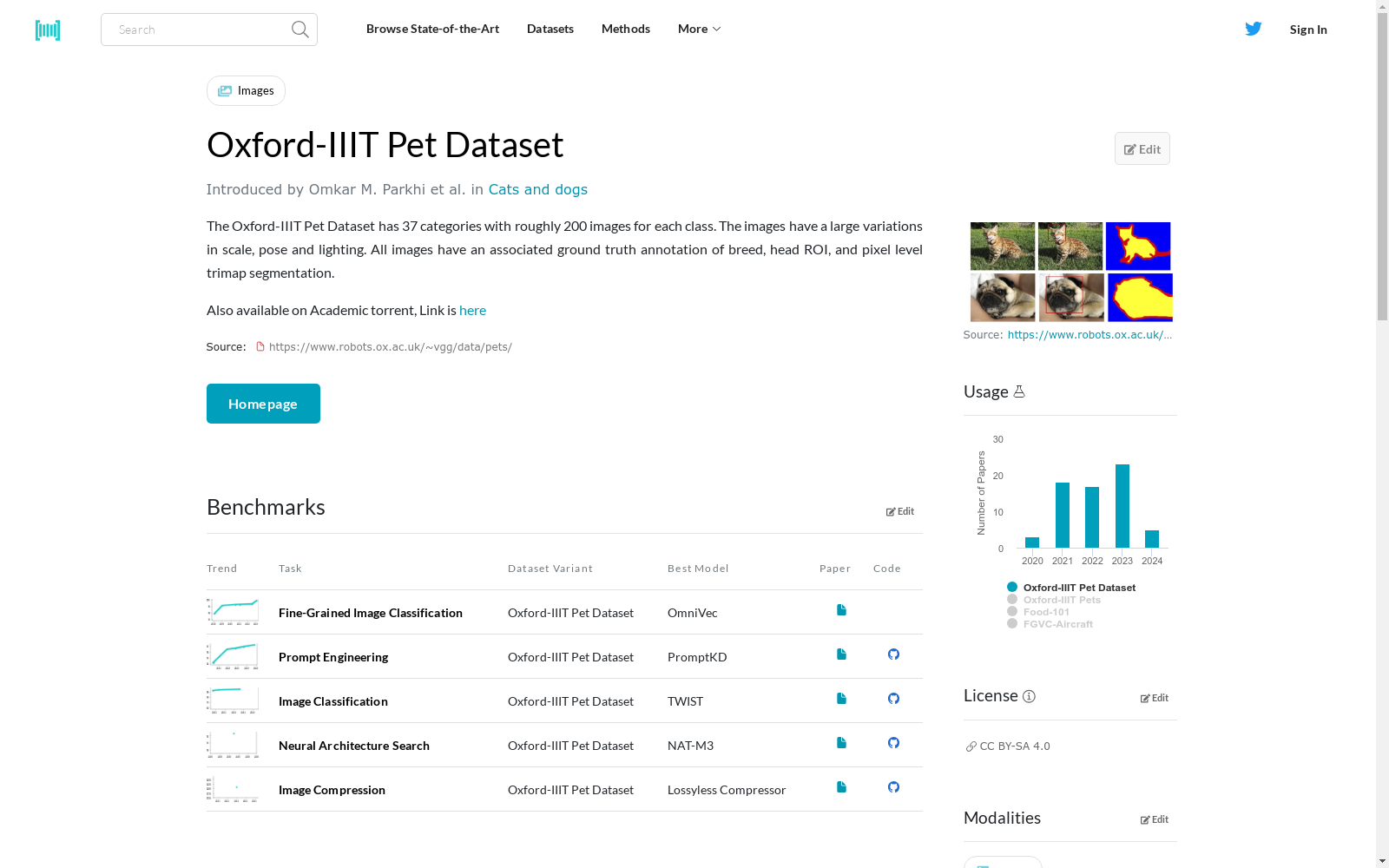
The Oxford-IIIT Pet Dataset has 37 categories with roughly 200 images for each class. The images have a large variations in scale, pose and lighting. All images have an associated ground truth annotation of breed, head ROI, and pixel level trimap segmentation.
AI搜集汇总
数据集介绍
构建方式
Oxford-IIIT Pet Dataset的构建基于对宠物图像的广泛收集与标注。该数据集由牛津大学计算机科学系与IIIT Hyderabad合作完成,涵盖了37种不同品种的宠物,包括猫和狗。每种品种的图像数量大致均匀,确保了数据集的多样性和代表性。图像的标注包括宠物品种、个体识别以及关键点标注,这些标注为后续的图像识别和分析提供了丰富的信息基础。
特点
Oxford-IIIT Pet Dataset以其高质量的图像和详尽的标注著称。数据集中的每张图像都经过精心挑选,确保清晰度和分辨率,适合用于各种计算机视觉任务。此外,该数据集的标注不仅包括基本的品种分类,还涵盖了个体识别和关键点定位,这使得它在研究个性化识别和姿态估计等领域具有独特的优势。
使用方法
Oxford-IIIT Pet Dataset广泛应用于计算机视觉领域的研究与开发,特别是在图像分类、目标检测和姿态估计等任务中。研究人员可以通过该数据集训练和验证自己的模型,利用其丰富的标注信息提升模型的准确性和鲁棒性。此外,该数据集也适用于教育目的,帮助学生和初学者理解并实践计算机视觉的基本概念和技术。
背景与挑战
背景概述
Oxford-IIIT Pet Dataset,由牛津大学、印度理工学院和微软研究院于2012年联合发布,是一个专注于宠物图像分类和分割的高质量数据集。该数据集包含了37种不同品种的宠物猫和狗,共计7393张图像,每张图像均附有详细的标注信息,包括品种、姿态和部分遮挡情况。这一数据集的发布,极大地推动了计算机视觉领域在细粒度图像分类和实例分割方面的研究进展,尤其在宠物识别和医疗诊断领域产生了深远影响。
当前挑战
尽管Oxford-IIIT Pet Dataset在宠物图像分类和分割方面提供了丰富的资源,但其构建过程中仍面临诸多挑战。首先,不同品种的宠物在外观上存在显著差异,这要求数据集必须具备高度的多样性和代表性。其次,宠物图像中常出现的遮挡、光照变化和姿态多样性,增加了图像标注和分类的复杂性。此外,数据集的规模和标注质量也是一大挑战,确保每张图像的标注准确无误,需要大量的人力和时间投入。
发展历史
创建时间与更新
Oxford-IIIT Pet Dataset由牛津大学、印度理工学院和微软研究院于2012年共同创建,旨在为计算机视觉领域的研究提供高质量的宠物图像数据。该数据集在2019年进行了更新,增加了更多的图像和类别,以适应日益增长的深度学习研究需求。
重要里程碑
Oxford-IIIT Pet Dataset的创建标志着宠物图像识别研究进入了一个新的阶段。其首次引入的37个宠物品种和每个品种的200张图像,为研究人员提供了丰富的数据资源。2019年的更新不仅增加了图像数量,还引入了新的品种,进一步提升了数据集的多样性和实用性。这一里程碑事件极大地推动了计算机视觉和深度学习在宠物识别和分类领域的应用。
当前发展情况
当前,Oxford-IIIT Pet Dataset已成为计算机视觉领域的重要基准数据集之一。它不仅被广泛用于图像分类、目标检测和语义分割等任务的研究,还为跨学科研究提供了宝贵的数据支持。随着人工智能技术的不断进步,该数据集的应用范围也在不断扩展,从基础研究到实际应用,如宠物健康监测和宠物品种识别等,都展现了其巨大的潜力和价值。
发展历程
- Oxford-IIIT Pet Dataset首次发表,由牛津大学、IIIT Hyderabad和微软研究院共同创建,旨在为计算机视觉研究提供高质量的宠物图像数据集。
- 该数据集首次应用于图像分割和分类任务,展示了其在计算机视觉领域的潜力。
- Oxford-IIIT Pet Dataset被广泛用于深度学习模型的训练和评估,特别是在卷积神经网络(CNN)的研究中。
- 数据集的版本更新,增加了更多的图像和标注,提升了数据集的多样性和覆盖范围。
- 该数据集成为多个国际计算机视觉竞赛的标准基准数据集,进一步推动了相关研究的发展。
- Oxford-IIIT Pet Dataset被用于开发和测试新的图像处理算法,特别是在宠物识别和分类领域。
常用场景
经典使用场景
在计算机视觉领域,Oxford-IIIT Pet Dataset 被广泛用于图像分类和目标检测任务。该数据集包含了37种不同品种的宠物图像,每种品种约有200张图像,总计约7390张图像。这些图像不仅涵盖了不同品种的猫和狗,还包括了不同姿态、光照条件和背景的图像,为研究人员提供了一个多样化的数据集,用于训练和评估模型在复杂环境下的表现。
衍生相关工作
基于 Oxford-IIIT Pet Dataset,许多研究工作得以展开,其中包括改进的图像分类算法、深度学习模型的优化以及多模态数据融合技术的应用。例如,一些研究通过引入注意力机制和迁移学习,显著提升了宠物图像识别的准确率。此外,该数据集还激发了关于数据增强和数据集扩展的研究,以应对实际应用中的多样性和复杂性挑战。
数据集最近研究
最新研究方向
在计算机视觉领域,Oxford-IIIT Pet Dataset 作为评估图像分类和分割任务的标准数据集,近年来吸引了众多研究者的关注。最新研究方向主要集中在利用深度学习技术提升宠物图像的识别精度,特别是在复杂背景和光照条件下的表现。此外,研究者们还探索了数据增强和迁移学习方法,以解决数据集类别不平衡和样本量有限的问题。这些研究不仅推动了宠物识别技术的进步,也为其他领域的图像处理研究提供了宝贵的参考。
相关研究论文
- 1The Oxford-IIIT Pet Dataset: A Resource for Benchmarking Fine-Grained Image ClassificationUniversity of Oxford · 2012年
- 2Fine-Grained Visual Classification of Animals: A SurveyUniversity of Adelaide · 2020年
- 3Deep Learning for Fine-Grained Image Analysis: A SurveyUniversity of Chinese Academy of Sciences · 2019年
- 4A Survey on Deep Learning Techniques for Fine-Grained Image ClassificationUniversity of Science and Technology of China · 2021年
- 5Fine-Grained Visual Classification: A Survey of Recent AdvancesUniversity of Technology Sydney · 2021年
以上内容由AI搜集并总结生成


