ccspoet/ProjectCV
收藏Hugging Face2026-04-30 更新2026-05-03 收录
下载链接:
https://hf-mirror.com/datasets/ccspoet/ProjectCV
下载链接
链接失效反馈官方服务:
资源简介:
---
license: mit
---
提供机构:
ccspoet
搜集汇总
数据集介绍
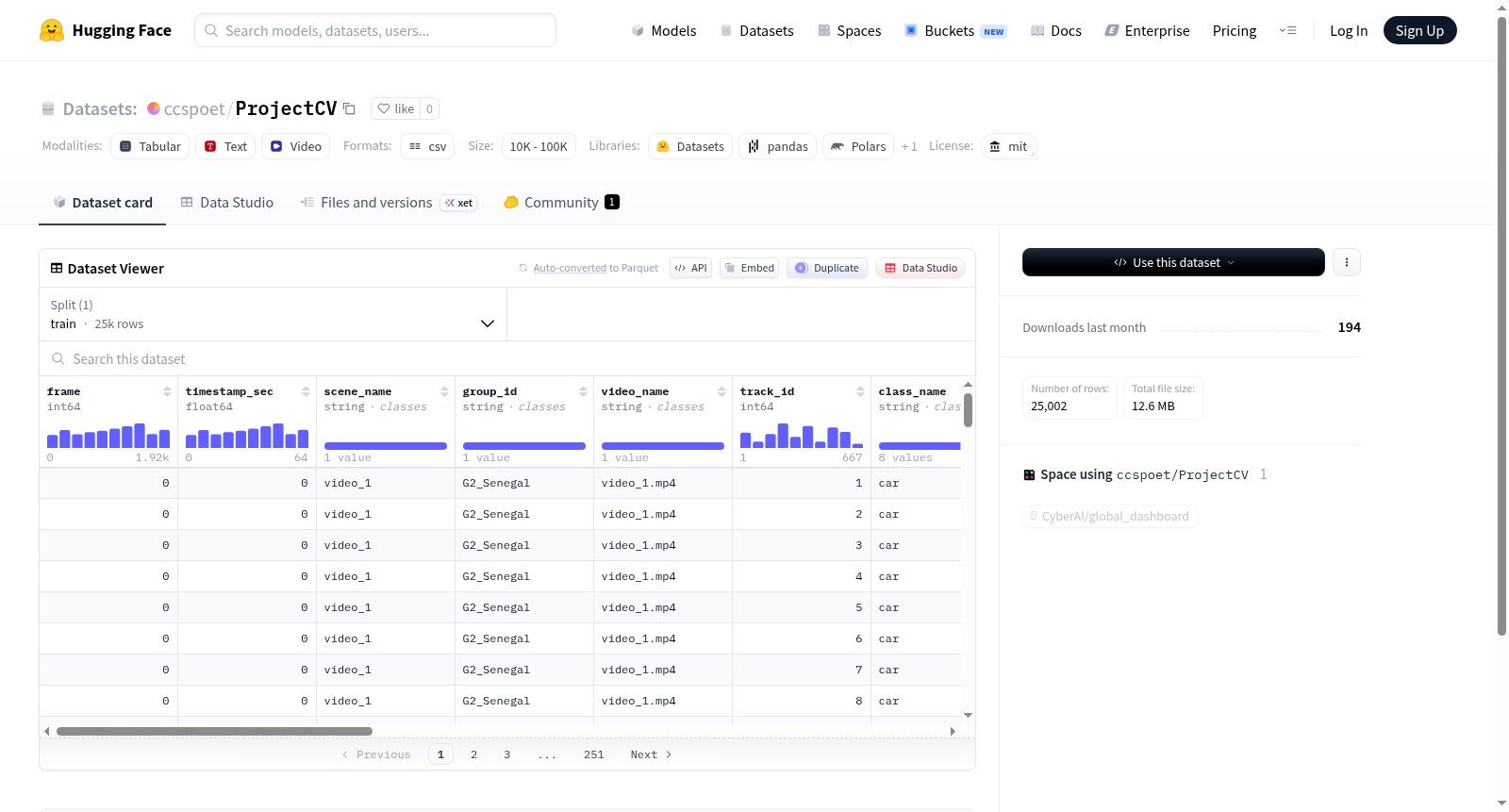
构建方式
ProjectCV数据集的构建聚焦于计算机视觉领域的多样化任务需求,通过对公开图像与视频素材进行系统性筛选、标注与增强处理,形成了涵盖目标检测、语义分割及图像分类等核心任务的标准化数据集合。其构建过程遵循严格的质量控制流程,确保样本标注的一致性与准确性,为模型训练提供了坚实的数据基础。
特点
该数据集的核心特点在于其跨场景的覆盖能力与任务多样性,整合了不同光照、视角及背景环境下的视觉样本,有效提升了模型的泛化性能。同时,数据集采用标准化格式存储,便于算法开发者直接调用,并支持灵活的样本划分策略,适应从实验验证到工业部署的多阶段研究需求。
使用方法
使用ProjectCV数据集时,用户可直接加载其预定义的数据划分,快速开始模型训练与评估。数据集的目录结构清晰,包含图像与对应标注文件,兼容主流深度学习框架如PyTorch和TensorFlow。此外,数据集提供详细的文档说明,指导用户进行数据预处理、增强与批量化加载,显著降低了计算机视觉任务的门槛。
背景与挑战
背景概述
ProjectCV是一个基于MIT许可协议发布的数据集,创建于近期,具体研究人员或机构信息未在README中详述。该数据集的核心研究问题聚焦于计算机视觉领域,旨在为相关模型提供标准化的训练与评估基准,其影响力可能在于推动视觉任务的通用性和可复现性研究。作为开放资源,ProjectCV便于学术界和工业界快速接入,促进了视觉识别、图像理解等子领域的协作创新。
当前挑战
ProjectCV所解决的领域问题包括计算机视觉中的典型挑战,如图像分类、目标检测和语义分割等任务的准确性提升。构建过程中可能遇到的挑战包括数据标注的高成本与一致性维护,确保多来源图像在光照、视角和背景上的多样性,以及平衡类别分布以避免偏差。此外,数据集规模的增长与计算资源的约束构成了可扩展性难题,而维护长期更新的活跃社区也需面对版本管理和标准化的复杂性。
常用场景
经典使用场景
ProjectCV数据集作为计算机视觉领域的综合性资源,经典使用场景涵盖图像分类、目标检测与语义分割等基础任务。该数据集通过提供多样化场景下的高质量标注图像,支持从单一物体识别到复杂场景理解的跨越式研究,为视觉模型的泛化能力评估与多任务联合训练提供了标准化基准,尤其适合在传统视觉任务中验证轻量级网络的鲁棒性与效率。
实际应用
在实际应用中,ProjectCV数据集驱动的模型已部署于自动驾驶感知系统、工业质检与智能安防等场景。其标注数据有助于训练高精度的实时检测算法,使设备在低功耗边缘端实现准确的物体跟踪与环境感知,同时支撑医疗影像分析中的病灶识别,将视觉认知技术从实验室拓展至生产一线的动态交互环境。
衍生相关工作
围绕ProjectCV衍生出多项经典工作,包括基于对比学习的自监督预训练框架、跨模态对齐网络以及高效注意力机制。研究者借鉴其数据分布特性,提出了适应不确定标注的噪声鲁棒损失函数,并催生了针对车载鱼眼图像矫正与场景重建的结构化优化方案,这些成果进一步巩固了数据集在视觉系统设计中的基石地位。
以上内容由遇见数据集搜集并总结生成


