TCM-Vision-Benchmark
收藏Hugging Face2025-11-13 更新2025-11-14 收录
下载链接:
https://huggingface.co/datasets/FreedomIntelligence/TCM-Vision-Benchmark
下载链接
链接失效反馈官方服务:
资源简介:
这是一个用于中医领域多模态语言模型ShizhenGPT的基准数据集,包含7个部分:TCM专利、TCM材料、TCM草药、舌诊、掌诊、整体观、推拿和眼科,每个部分都由权威中医图谱编译而成,用于训练和评估模型在中医领域的表现。
This is a benchmark dataset for the multimodal language model ShizhenGPT in the field of Traditional Chinese Medicine (TCM). It contains 7 sections: TCM patents, TCM materials, TCM herbs, tongue diagnosis, palm diagnosis, holistic view, tuina, and ophthalmology. Each section is compiled from authoritative TCM medical atlases and is used for training and evaluating the model's performance in the TCM domain.
提供机构:
FreedomAI
创建时间:
2025-11-13
原始信息汇总
TCM-Vision-Benchmark 数据集概述
数据集简介
- 数据集名称:TCM-Vision-Benchmark
- 用途:为ShizhenGPT(中医多模态大语言模型)构建的文本基准测试
- 领域:传统中医(TCM)
- 数据类型:多模态数据
基准测试结构
基准测试包含8个组成部分,每个部分均来自不同的权威中医图解书籍:
| 类别 | 样本数量 |
|---|---|
| TCM Patent | 1119 |
| TCM Material | 1020 |
| TCM Herb | 1100 |
| Tongue | 768 |
| Palm | 640 |
| Holism | 1011 |
| Tuina | 831 |
| Eye | 715 |
数据格式
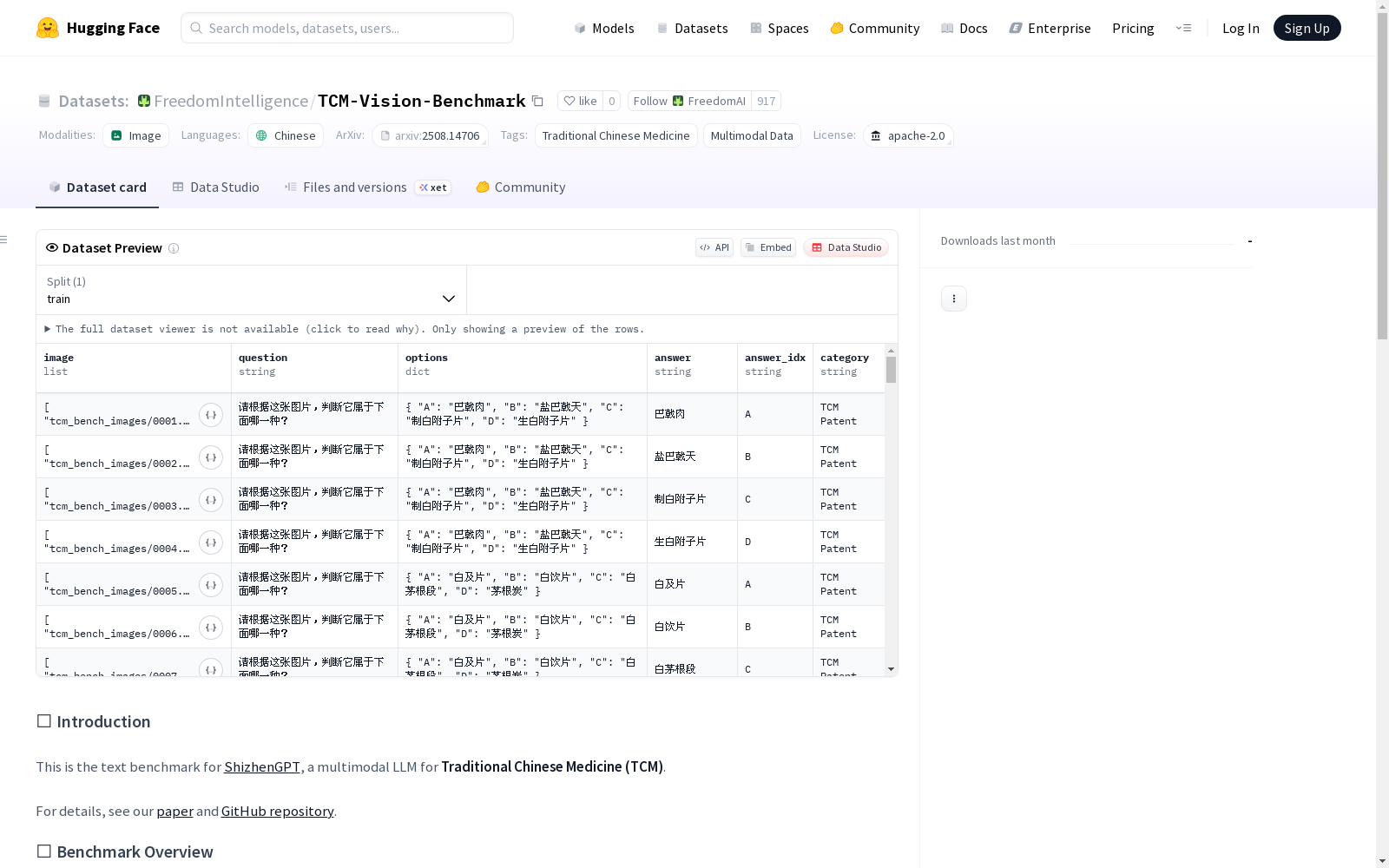
数据采用JSON格式构建,包含以下字段:
- image:图像文件路径(如"tcm_bench_images/0001.jpg")
- question:基于图片的问题描述
- options:选择题选项(A、B、C、D)
- answer:正确答案文本
- answer_idx:正确答案索引
- category:所属类别
许可证信息
- 许可证类型:Apache-2.0
相关资源
- 论文地址:https://arxiv.org/abs/2508.14706
- GitHub仓库:https://github.com/FreedomIntelligence/ShizhenGPT
引用信息
bibtex @misc{chen2025shizhengptmultimodalllmstraditional, title={ShizhenGPT: Towards Multimodal LLMs for Traditional Chinese Medicine}, author={Junying Chen and Zhenyang Cai and Zhiheng Liu and Yunjin Yang and Rongsheng Wang and Qingying Xiao and Xiangyi Feng and Zhan Su and Jing Guo and Xiang Wan and Guangjun Yu and Haizhou Li and Benyou Wang}, year={2025}, eprint={2508.14706}, archivePrefix={arXiv}, primaryClass={cs.CL}, url={https://arxiv.org/abs/2508.14706}, }
搜集汇总
数据集介绍
构建方式
在中医药多模态研究领域,TCM-Vision-Benchmark的构建体现了严谨的学术规范。该数据集源自七类权威中医药图谱文献,涵盖中药专利、药材、舌诊等专业领域,通过结构化采集流程形成标准化样本。每项数据包含图像路径、多选问题及标准答案,采用人工标注与专家验证相结合的方式,确保数据与临床知识的准确对应。这种分层构建策略既保留了传统医学的系统性,又契合现代人工智能技术的处理需求。
使用方法
对于研究者和开发者而言,该数据集为评估多模态大语言模型在中医药领域的性能提供了标准范式。使用时需加载图像与对应JSON格式的标注文件,通过解析问题、选项和标准答案构建预测任务。典型应用场景包括跨模态检索、视觉问答和专业知识推理等方向。使用者可参照提供的论文和代码库实现基准测试,该设计既支持端到端模型训练,也适用于零样本评估框架,为中医药智能化研究奠定了可复现的实验基础。
背景与挑战
背景概述
随着人工智能技术在医疗领域的深入应用,传统中医药学的多模态数据整合成为新兴研究方向。TCM-Vision-Benchmark数据集由香港中文大学(深圳)与新加坡国立大学等机构于2025年联合构建,旨在通过图文对照形式系统化整理中医药知识。该数据集涵盖中药药材、舌诊、掌纹等七个子类,共计六千余条样本,为开发面向中医药的多模态大语言模型提供了标准化评估基准,显著推动了传统医学知识与现代人工智能技术的交叉融合。
当前挑战
中医药多模态数据集构建面临双重挑战:在领域问题层面,需解决中医诊断中舌象、掌纹等视觉特征的细粒度分类难题,以及药材性状的跨模态语义对齐问题;在数据构建过程中,需克服古籍插图质量参差不齐的标注困难,同时确保来自《本草纲目》等典籍的权威知识与图像样本的精准匹配,这对专业领域知识的标注一致性提出了极高要求。
常用场景
经典使用场景
在中医药智能化研究领域,TCM-Vision-Benchmark作为多模态评估基准,主要用于测试模型对中医图像与文本的跨模态理解能力。该数据集通过整合舌诊、掌纹、药材鉴定等七类权威图示资料,为算法提供了标准化的中医视觉问答任务,成为验证多模态大语言模型在专业领域适应性的重要工具。
解决学术问题
该数据集有效解决了传统中医知识数字化过程中的多模态对齐难题,通过构建结构化问答对,为研究界提供了检验模型中医诊断推理能力的评估体系。其意义在于建立了传统经验医学与人工智能技术的桥梁,推动了中医知识表示、跨模态检索等核心学术问题的方法创新,对传承非物质文化遗产具有深远影响。
实际应用
在实际医疗场景中,该数据集支撑的智能系统可辅助医师进行远程舌象分析、药材真伪鉴别等临床决策。通过标准化视觉诊断流程,既提升了基层医疗机构的诊疗效率,又为个人健康管理提供了便携式中医自诊工具,显著促进了中医诊断技术的普惠化发展。
数据集最近研究
最新研究方向
在传统医学数字化浪潮中,TCM-Vision-Benchmark作为首个融合多模态数据的中医药视觉基准,正推动领域研究向智能诊断系统演进。该数据集整合舌诊、掌纹及药材图像等七类权威资料,为构建如ShizhenGPT的多模态大语言模型提供核心支撑。当前研究聚焦于跨模态语义对齐与病理特征提取,通过视觉问答任务探索中医辨证的量化表征,相关技术已延伸至智能舌诊仪与中药溯源系统等应用场景。这一突破不仅加速了中医知识的结构化进程,更为传统医学与现代人工智能的深度融合开辟了新路径。
以上内容由遇见数据集搜集并总结生成


