vpt_data_8xx_shard0011
收藏Hugging Face2025-06-14 更新2025-06-15 收录
下载链接:
https://huggingface.co/datasets/BarryFutureman/vpt_data_8xx_shard0011
下载链接
链接失效反馈官方服务:
资源简介:
该数据集与机器人学相关,包含视频及其相关数据,数据以.parquet格式存储。数据集共有66个视频,总帧数为344028,分为1个任务。数据集按照Apache-2.0许可证发布,但README中未提供数据集的具体用途或内容描述。
This dataset pertains to the field of robotics, encompassing videos and their associated data, with all data stored in .parquet format. The dataset comprises 66 videos with a total of 344,028 frames and is organized into one single task. It is released under the Apache-2.0 license, but no specific usage or content description of the dataset is provided in the README.
创建时间:
2025-06-14
搜集汇总
数据集介绍
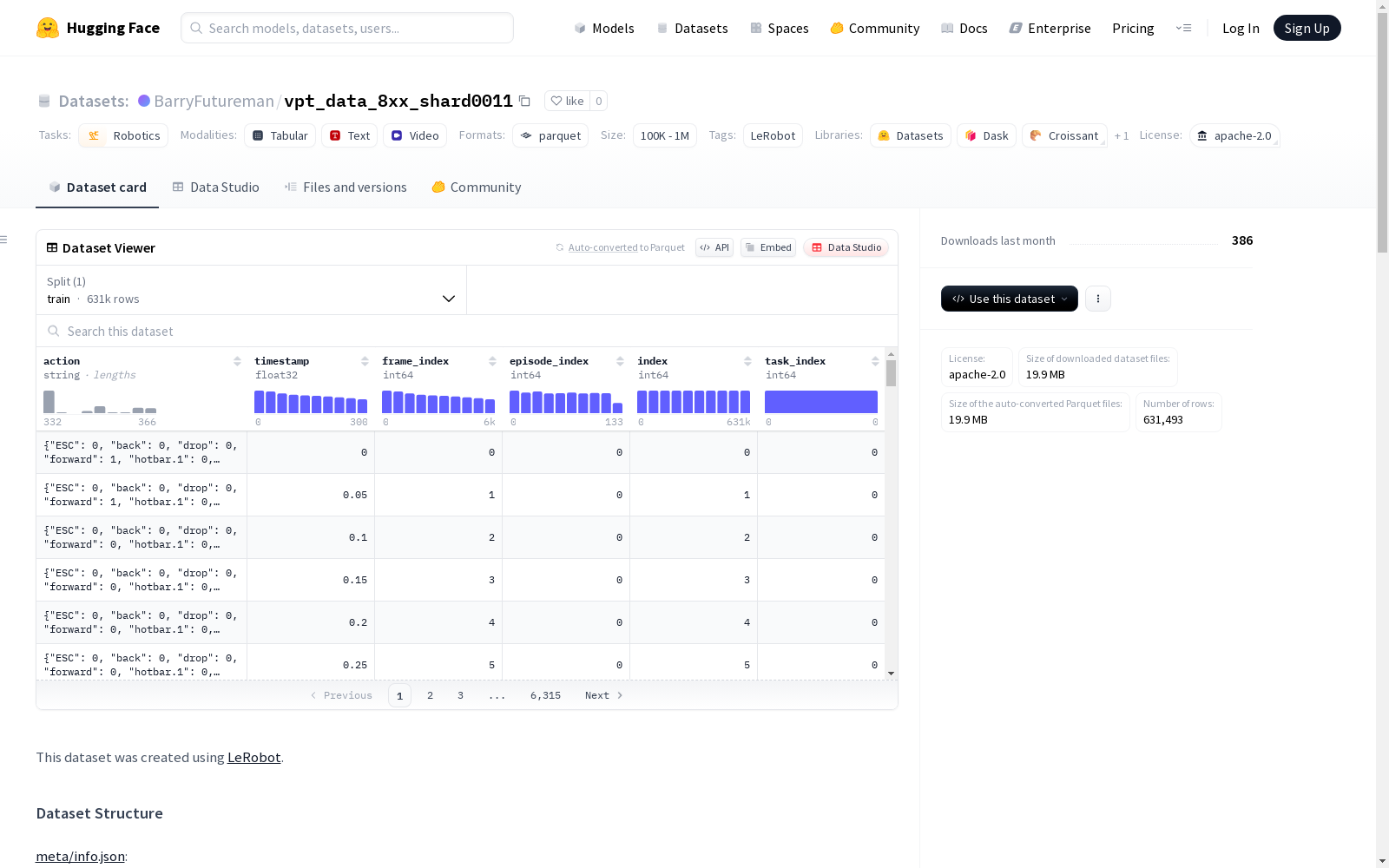
构建方式
在机器人技术领域,高质量的数据采集对于算法训练至关重要。vpt_data_8xx_shard0011数据集通过LeRobot平台构建,采用分布式数据采集策略,将66个完整操作序列以20fps的帧率记录为344028帧视频数据。数据以分块形式存储,每个数据块包含1000帧,采用AV1编码的360p视频流,并以Parquet格式高效组织观测图像、动作指令及时间戳等多模态信息。
特点
该数据集展现出鲜明的机器人操作任务特性,其三维视觉观测数据(3×360×640)精确捕捉了操作场景的空间信息。时间维度上,每帧数据均附带精确到毫秒级的时间戳和帧索引,实现了动作指令与视觉观测的严格对齐。值得注意的是,数据集采用无压缩的YUV420p像素格式保存原始视频数据,为机器人视觉研究提供了高质量的基准数据源。
使用方法
研究者可通过解析Parquet文件获取结构化数据流,其中observation.image字段对应视频帧的字节流,需配合AV1解码器使用。数据按episode_index自然分块,支持按任务片段加载。建议采用帧间差分法处理连续视频帧,结合timestamp字段实现时域分析。对于动作学习任务,action字段提供了字符串格式的指令标注,可与视觉观测联合建模。
背景与挑战
背景概述
vpt_data_8xx_shard0011数据集是机器人学领域的重要资源,由LeRobot项目团队基于Apache 2.0许可协议构建。该数据集包含66个完整任务片段,总计344028帧视频数据,帧率为20fps,分辨率为360×640。数据以标准化parquet格式存储,涵盖多维观测图像、动作指令及时间戳等关键特征。作为机器人视觉-动作协同学习的基础设施,该数据集为模仿学习与强化学习算法提供了高质量的仿真训练环境,其模块化存储结构和元数据规范体现了现代机器人数据集设计的工程化思维。
当前挑战
该数据集面临的核心挑战体现在算法与应用两个维度。在算法层面,跨模态数据对齐要求精确处理高维视觉观测(3×360×640)与离散动作指令的时序匹配问题,这对模仿学习的策略泛化能力构成严峻考验。在工程实现上,大规模视频数据的存储与检索效率受限于parquet格式的序列化开销,344028帧数据的实时加载对内存管理提出苛刻要求。此外,未明确的机器人本体类型限制了迁移学习的适用性,而单一任务场景(total_tasks=1)的局限性也制约了数据集的学术价值。
常用场景
经典使用场景
在机器人学领域,vpt_data_8xx_shard0011数据集以其丰富的视频帧序列和动作记录,成为研究机器人视觉感知与行为决策的重要资源。该数据集通过捕捉66个完整任务执行过程的34万帧高分辨率图像,为模仿学习、强化学习等算法提供了真实世界的训练样本,特别适用于需要复杂环境交互的机器人任务仿真。
衍生相关工作
基于该数据集的特性,已衍生出多个机器人学习领域的创新研究。典型工作包括基于时空注意力机制的行为克隆框架、多任务分层强化学习系统,以及利用帧间连续性进行自监督表征学习的算法,这些成果显著推动了视觉-动作联合建模的技术前沿。
数据集最近研究
最新研究方向
在机器人学习领域,vpt_data_8xx_shard0011数据集以其丰富的视频帧序列和动作记录为特色,为模仿学习与强化学习算法的训练提供了高质量的真实世界数据。当前研究聚焦于如何利用该数据集中的多模态观察信息,特别是高维视觉输入与低维动作空间的映射关系,以提升机器人任务执行的泛化能力。随着LeRobot等开源平台的普及,基于此类数据集的端到端策略学习成为热点,研究者们正探索如何结合Transformer等先进架构,从海量视频数据中提取更具鲁棒性的特征表示。这一方向不仅推动了家庭服务机器人等实用场景的算法进步,也为跨任务迁移学习提供了新的基准。
以上内容由遇见数据集搜集并总结生成


