Zarakun/speakers_ua_test
收藏Hugging Face2024-01-18 更新2024-03-04 收录
下载链接:
https://hf-mirror.com/datasets/Zarakun/speakers_ua_test
下载链接
链接失效反馈官方服务:
资源简介:
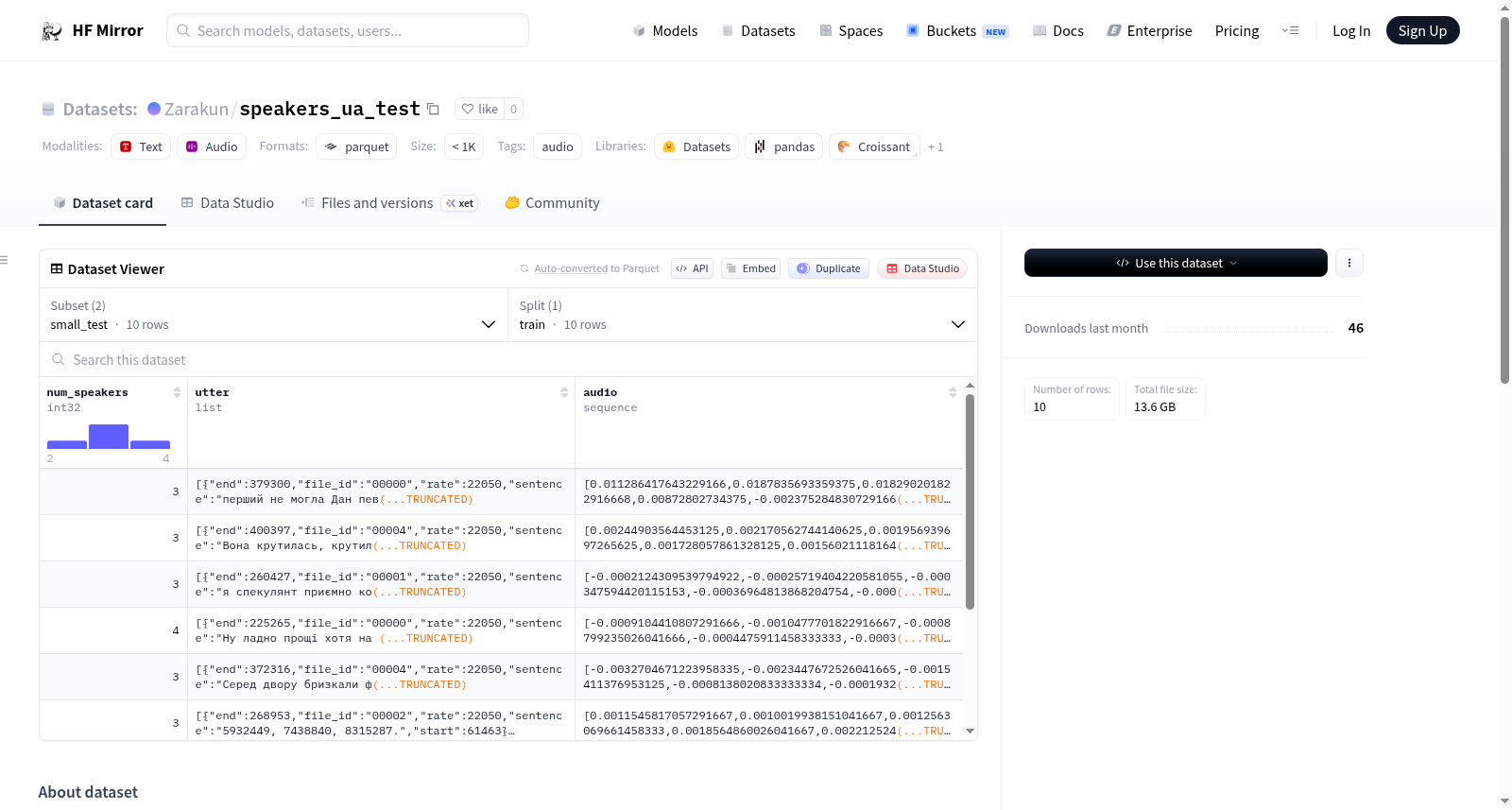
这是一个多说话者带噪声的语音数据集,每个样本最多30秒。每个样本包含说话者数量、话语数据和音频波形等信息。话语数据进一步细分为开始位置、结束位置、说话者标识符、转录文本和采样率。
这是一个多说话者带噪声的语音数据集,每个样本最多30秒。每个样本包含说话者数量、话语数据和音频波形等信息。话语数据进一步细分为开始位置、结束位置、说话者标识符、转录文本和采样率。
提供机构:
Zarakun
原始信息汇总
数据集概述
数据集描述
这是一个包含多说话者语音及噪声的数据集,每个样本时长最多为30秒。
数据加载脚本
python data_files = {"train": "data/<your_subset>.parquet"} data = load_dataset("Zarakun/speakers_ua_test", data_files=data_files)
加载后的数据结构如下: python DatasetDict({ test: Dataset({ features: [num_speakers, utter, audio], num_rows: <some_number> }) })
数据集结构
每个样本包含以下特征:
- num_speakers:说话者数量
- utter:话语数据列表
- audio:音频波形
utter 列表中的每个条目是一个字典,包含以下结构:
- start:说话者音频在 audio 中的起始位置
- end:说话者音频在 audio 中的结束位置
- file_id:说话者的标识符
- sentence:转录文本
- rate:采样率,所有样本中应保持一致
搜集汇总
数据集介绍
背景与挑战
背景概述
该数据集是一个多说话者语音数据集,包含噪声,每个音频样本最长30秒。数据集提供了音频波形和对应的文本转录,适用于语音处理任务,如说话者识别或语音识别。数据以parquet格式存储,总大小为13.6 GB,包含10行示例,结构清晰,包括说话者数量、话语列表和音频波形等特征。
以上内容由遇见数据集搜集并总结生成


