S-MedQA
收藏arXiv2025-05-15 更新2025-05-17 收录
下载链接:
https://anonymous.4open.science/r/S-MedQA-85FD/
下载链接
链接失效反馈官方服务:
资源简介:
S-MedQA是一个英文医疗问答数据集,旨在为细粒度临床专科领域的大语言模型提供基准测试。该数据集基于MedQA和MedMCQA构建,并由GPT-3.5和医疗专家标注。S-MedQA包含15个专科,每个专科有成百上千个样本。数据集的创建过程包括使用GPT-3.5进行单专科标注,并使用一致性预测技术进行多专科标注。该数据集可用于研究知识注入在医疗问答中的适用性,以及不同专科数据对模型性能的影响。
S-MedQA is an English medical question answering dataset designed to provide a benchmark for large language models in fine-grained clinical specialty domains. It is constructed based on MedQA and MedMCQA, and annotated by GPT-3.5 and medical experts. S-MedQA covers 15 medical specialties, with hundreds to thousands of samples per specialty. The dataset creation process involves single-specialty annotation using GPT-3.5, and multi-specialty annotation via consistency prediction techniques. This dataset can be utilized to investigate the applicability of knowledge injection in medical question answering, as well as the influence of different specialty datasets on model performance.
提供机构:
阿姆斯特丹大学医学中心医学信息系,阿姆斯特丹大学
创建时间:
2025-05-15
原始信息汇总
S-MedQA数据集概述
数据集基本信息
- 名称: S-MedQA
- 类型: 临床专业标注的医学多选题问答(QA)数据集
- 来源: 基于MedQA数据集进行临床专业标注
- 标注工具: GPT-3.5
- 更新时间: 2024年6月30日
数据集特点
- 首个临床专业标注的医学QA数据集
- 提供不同准确率/覆盖率的多个版本
- 包含训练集/验证集/测试集划分
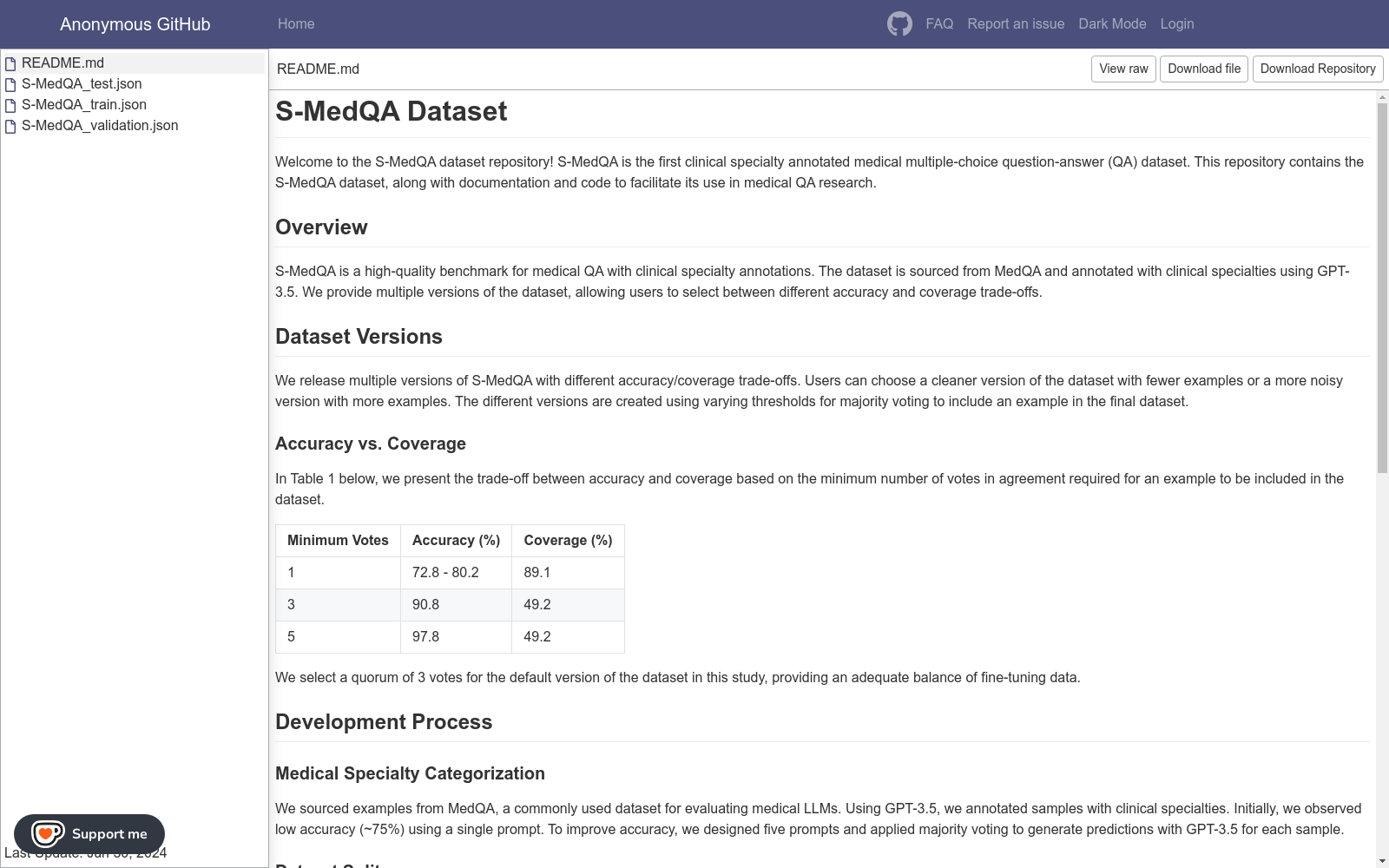
数据集版本
| 最小投票数 | 准确率(%) | 覆盖率(%) |
|---|---|---|
| 1 | 72.8-80.2 | 89.1 |
| 3 | 90.8 | 49.2 |
| 5 | 97.8 | 49.2 |
- 默认版本: 采用3票多数表决的版本
数据集规模
- 训练集: 7,125个样本
- 验证集: 899个样本
- 测试集: 893个样本
开发过程
- 从MedQA获取原始样本
- 使用GPT-3.5进行临床专业标注
- 采用5种提示词进行多数表决
- 排除无多数表决样本(1,324个)和"其他"类别样本(308个)
- 保留样本量超过200的15个专业类别
质量验证
- 医学专家标注了验证集和测试集所有样本
- 验证了训练集中的1,000个随机样本
- 专家与3名医学硕士生的标注一致率达83.6%(95% CI [69.0%,93.9%])
文件列表
README.md: 数据集说明文档S-MedQA_train.json: 训练集数据S-MedQA_validation.json: 验证集数据S-MedQA_test.json: 测试集数据
搜集汇总
数据集介绍
构建方式
S-MedQA数据集的构建基于广泛使用的MedQA和MedMCQA数据集,通过GPT-3.5和医学专家的协作,将样本映射到临床专科。采用五组不同的提示生成单专科预测,并通过多数投票机制筛选一致的结果,确保标注的准确性。此外,通过适应性预测方法扩展至多专科标注,保证覆盖率和置信度。
特点
S-MedQA作为首个带有多个临床专科标注的英文医学问答数据集,覆盖15个专科,每个专科包含数百至数千个样本。其独特之处在于通过精细的标注流程和验证机制,确保数据的高质量和专科特异性,同时提供不同准确性与覆盖率的版本以满足不同研究需求。
使用方法
S-MedQA适用于评估大型语言模型在细粒度临床专科中的表现,支持跨专科知识迁移研究。用户可根据需求选择不同版本的数据集,通过微调模型并评估其在各专科测试集上的表现,探索领域适应与知识注入的效果。数据集还提供详细的术语重叠分析,助力模型性能的深入解析。
背景与挑战
背景概述
S-MedQA数据集由阿姆斯特丹大学医学信息学系和阿姆斯特丹大学的研究团队于2025年推出,旨在填补医学问答领域在临床专科细粒度评估方面的空白。该数据集基于广泛使用的MedQA和MedMCQA数据集构建,通过GPT-3.5和医学专家标注,覆盖15个临床专科,每个专科包含数百至数千个样本。S-MedQA的创建为研究跨临床专科的知识转移提供了重要资源,并挑战了关于知识注入在医学大语言模型中的传统假设。
当前挑战
S-MedQA面临的挑战主要体现在两个方面:领域问题的挑战和构建过程的挑战。在领域问题方面,该数据集旨在解决医学问答中临床专科细粒度评估的难题,但研究发现专科数据的训练并不一定带来最佳性能,性能提升更多来自领域迁移而非知识注入。在构建过程中,临床专科标注面临高昂的人工成本和时间消耗,尽管通过多提示和多数投票策略将标注准确率提升至97.8%,但在处理跨专科复杂案例时仍存在模糊性。此外,将单专科标签扩展到多专科标注时,需要在覆盖率和准确性之间进行权衡,这进一步增加了数据集的构建难度。
常用场景
经典使用场景
S-MedQA数据集在医学问答领域具有广泛的应用场景,特别是在评估大型语言模型(LLMs)在细粒度临床专业中的表现。该数据集通过标注15个不同的临床专业,为研究者提供了一个标准化的基准,用于测试模型在特定医学领域的知识掌握和推理能力。例如,在心脏病学、神经学和传染病学等专业中,S-MedQA能够帮助研究者评估模型在复杂医学问题上的准确性和可靠性。
实际应用
在实际应用中,S-MedQA可用于开发针对特定临床专业的智能辅助诊断工具。例如,在专科医院中,该数据集可以用于训练和优化针对心脏病学或神经学的问答系统,帮助医生快速获取准确的医学知识。此外,S-MedQA还可用于医学教育,为学生和实习医生提供一个模拟临床环境的问答平台,提升其专业知识和诊断能力。
衍生相关工作
S-MedQA的推出激发了多项相关研究,特别是在医学大型语言模型的优化和评估方面。例如,基于S-MedQA的研究探讨了不同预训练模型在跨专业知识迁移中的表现差异,为模型选择提供了实证依据。此外,该数据集还被用于研究医学术语的分布和重叠,进一步推动了医学自然语言处理领域的发展。
以上内容由遇见数据集搜集并总结生成


