llbench-dataset
收藏Hugging Face2026-05-09 更新2026-05-10 收录
下载链接:
https://huggingface.co/datasets/anonymousllbench/llbench-dataset
下载链接
链接失效反馈官方服务:
资源简介:
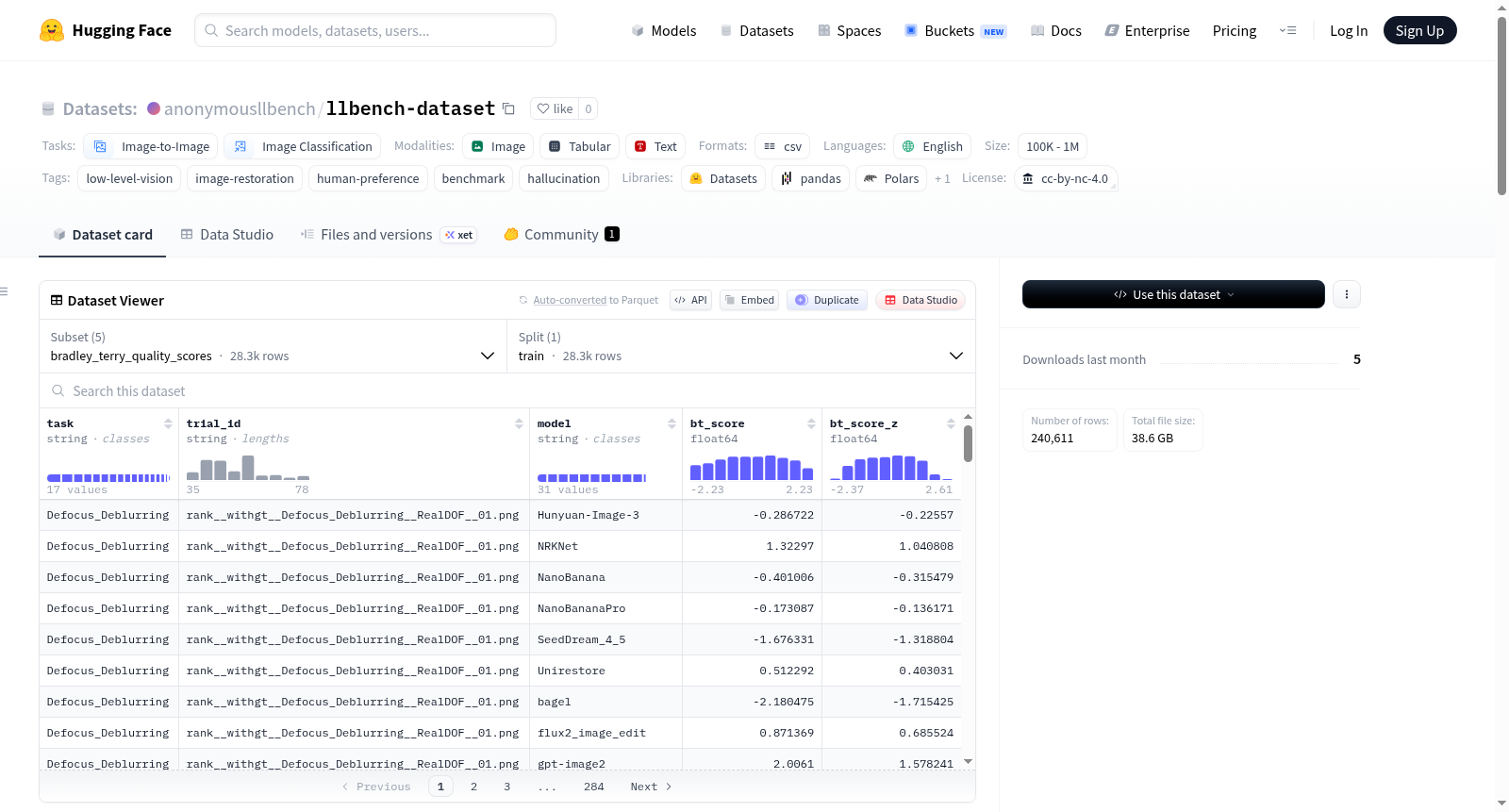
LL-Bench 是一个大规模的人类偏好基准数据集,旨在评估大型生成模型(LGMs)时代的低层次视觉恢复任务。该数据集比较了10种大型生成模型、16种专业模型和5种全能模型在16种低层次视觉任务上的表现,并附带了密集的人类标注数据,包括成对质量偏好、Bradley-Terry分数和每张图像的幻觉标签。数据集包含28,919个(试验×模型)恢复图像记录,组织结构包括元数据、人类偏好数据、源图像和恢复图像。适用于图像到图像、图像分类等任务,特别关注低层次视觉和图像恢复领域。数据集采用CC BY-NC 4.0许可,仅供非商业研究使用。
LL-Bench is a large-scale human preference benchmark dataset developed to evaluate low-level visual restoration tasks in the era of Large Generative Models (LGMs). This dataset compares the performance of 10 large generative models, 16 specialized models and 5 general-purpose models across 16 low-level visual tasks, and is accompanied by dense human annotation data including pairwise quality preferences, Bradley-Terry scores and hallucination labels for each individual image. The dataset contains 28,919 (trial × model) restored image records, with its organizational structure covering metadata, human preference data, source images and restored images. It is applicable to tasks such as image-to-image and image classification, with a particular focus on the fields of low-level vision and image restoration. The dataset is licensed under CC BY-NC 4.0 and is for non-commercial research use only.
创建时间:
2026-05-09
原始信息汇总
数据集概述:LL-Bench
LL-Bench 是一个面向大规模生成模型(LGM)时代的大规模、基于人类偏好的低层视觉恢复基准数据集。
核心任务与规模
- 评估内容:比较 10个大型生成模型、16个专业模型和5个全能模型在 16个低层视觉任务上的表现。
- 任务列表:运动去模糊、阴影去除、去雪、去雨、超分辨率、HDR成像、低光增强、旧照片修复、压缩伪影去除、雨滴去除、水下增强、去雾、去噪、散焦去模糊、眩光去除、反射去除。
- 数据规模:包含 28,919行(每行对应一个“试验×模型”的恢复图像),以及 10K到100K 条样本。
关键特性
- 人类偏好标注:提供密集的人工标注,包括:
- 成对质量偏好(pairwise quality preferences)
- Bradley-Terry 分数(Bradley-Terry quality scores)
- 每图像幻觉标签(hallucination labels)
- 试验质量排名(trial quality rankings)
- 独立标注:标注者被要求将“过度处理/幻觉”与偏好排名分开标注,两者相互独立。
数据组成
数据集包含以下配置(Config):
| 配置名称 | 说明 |
|---|---|
images |
每行一个(试验×模型)的恢复图像,包含试验级字段(28,919行)。 |
pairwise_quality_preferences |
成对质量偏好数据。 |
bradley_terry_quality_scores |
Bradley-Terry 质量分数。 |
hallucination_labels |
幻觉标签。 |
trial_quality_rankings |
试验质量排名。 |
目录结构
数据集目录布局如下:
metadata/:包含images.csv元数据文件。human_preference/:包含所有偏好和标签的 CSV 文件。source_images/:原始图像,分为有Ground Truth (with_gt)和无Ground Truth (wo_gt)。restored_images_lgm/:大型生成模型的输出图像。restored_images_sp_aio/:专业和全能模型的输出图像。
使用方式
- 快速加载:可使用
pandas.read_csv()直接加载各 CSV 文件,所有表通过trial_id进行连接。 - 图像解析:可通过
PIL.Image.open()读取restored_image_path字段指定的图像文件(路径相对于数据集根目录)。 - 连接成对数据:通过
trial_id和model字段,可从images表中查找对应成对比较中的图像。
许可与引用
- 许可证:CC BY-NC 4.0,仅供非商业研究使用。原始图像继承原数据集的许可证,商业使用前需查阅原来源。
- 引用:匿名提交的论文(NeurIPS 2026 评审)。
注意事项
- 无 Ground Truth(
wo_gt)的试验中,gt_image_path为空,读取前需检查has_gt字段。 - 某些
任务×数据集组合仅包含模型子集,精确覆盖情况记录在images.csv中。
搜集汇总
数据集介绍
构建方式
LL-Bench数据集旨在重新审视大规模生成模型时代下低层视觉评估的范式,通过整合人类偏好构建了一套全面基准。该数据集系统收集了10种大规模生成模型、16种专用模型及5种全能模型在16种低层视觉任务上的恢复结果,包括去模糊、去雾、超分辨率等。构建过程中,研究者精细组织了图像元数据与人类偏好标注,通过成对质量偏好、Bradley-Terry评分及逐图像幻觉标签等多维度标注,形成了对模型性能的密集人类评估。数据源自公开数据集,并区分了有真实参考图像与无真实参考图像两类场景,确保评估的广泛性和适用性。
特点
该数据集的核心特色在于其大规模人类偏好基准的定位,提供了跨16种低层视觉任务的密集人类标注,涵盖10种先进生成模型与21种传统模型的对比。其独到之处在于独立标注了过处理与幻觉现象,与质量偏好排名形成互补,揭示了生成模型在视觉恢复中的潜在问题。数据集包含近三万个图像-模型条目,并附有完整的元数据表,方便研究者进行多维度分析。此外,其结构化目录清晰分离原始图像与恢复结果,支持灵活的评估协议设计。
使用方法
使用LL-Bench数据集时,用户可通过加载CSV元数据文件快速访问图像路径与标注信息。示例代码展示了如何利用Pandas读取图像元数据、偏好评分、Bradley-Terry分数及幻觉标签,并通过trial_id与model字段进行表间关联。恢复图像路径可直接用于PIL等库加载图像。对于成对偏好分析,可通过trial_id与model1/model2字段从图像表中检索对应图像路径。数据集以CC-BY-NC 4.0许可发布,适合非商业研究用途,尤其在评估生成模型在低层视觉任务中的人类感知质量方面具有重要价值。
背景与挑战
背景概述
在大型生成模型(LGM)蓬勃发展的时代,低层视觉任务(如图像去模糊、超分辨率、去噪等)的评估体系正面临根本性变革。传统基于像素级误差(如PSNR、SSIM)的客观指标难以捕捉人类对图像质量的细腻感知,尤其是生成模型引入的幻觉与过度处理问题。为此,LL-Bench数据集于2026年匿名发布于NeurIPS,由匿名研究团队构建,旨在系统性地重新审视低层视觉的评估范式。该Benchmark汇聚了10种大型生成模型、16种专用模型和5种全能型模型,覆盖16项低层视觉任务,并大规模采集了人类偏好标签(成对质量偏好、Bradley–Terry评分、幻觉注释),以提供更符合人类主观评价的基准。其影响力在于推动低层视觉评测从客观指标向人本化评估转型,为生成模型的可靠性研究奠定数据基础。
当前挑战
该数据集应对的核心挑战在于解决低层视觉评估中长期存在的‘指标-感知’错位问题:传统客观指标无法反映生成模型带来的视觉幻觉与不自然感,而现有数据集缺乏跨任务、跨模型的大规模人类偏好数据。构建过程中,团队面临多重困难:需统一来自不同原始数据集(如with_gt/wo_gt)的图像格式与许可协议;确保16种任务下模型输出的可比性,同时记录每行模型覆盖范围的细粒度信息;在众包标注中,区分偏好评分与幻觉标记两个独立维度,避免标注逻辑混淆;以及处理无真实参考(wo_gt)图像的基准缺失问题,通过设计无参考偏好比较流程加以克服。这些挑战的解决使得LL-Bench成为一个高质量、多维度的评测资源。
常用场景
经典使用场景
在底层视觉任务中,LL-Bench被广泛用于评估图像恢复模型的真实表现,特别针对大模型在去模糊、去雾、超分辨率等16类任务中的输出质量。研究者利用其提供的人眼偏好对比数据、Bradley-Terry得分及幻觉标签,进行模型间的系统对比与排序,从而精准量化不同模型在感知质量上的优劣差异。该数据集以大规模成对偏好判断为基础,取代了传统PSNR或SSIM等客观指标,为LGM时代的底层视觉评估提供了更为可靠且贴近人类感知的基准,是当前低层视觉大模型评测领域不可或缺的标准工具。
衍生相关工作
围绕LL-Bench催生了一系列富有影响力的衍生研究。基于其成对偏好数据,涌现出多种可微的感知损失函数,试图将Bradley-Terry标度直接嵌入网络训练目标,从而替代传统的L1或VGG损失。在模型评估层面,部分工作利用该数据集的幻觉标签训练幻觉检测分类器,实现了对图像生成过度处理的自动化预警。此外,LL-Bench的偏好标注体系被多篇后续论文引用,用以构建跨任务的多模态评估框架,拓展至视频恢复与生成领域。其公开的人眼注释数据亦被用于研究不同任务间偏好一致性的统计规律,为底层视觉的统一建模提供了实验依据。
数据集最近研究
最新研究方向
在大规模生成模型(LGMs)蓬勃发展的背景下,低层视觉(low-level vision)评估正经历一场深刻的范式革新。LL-Bench作为前沿基准数据集,首次系统性地引入人类偏好(human preference)作为核心评价准则,突破了传统基于像素级或感知度量的局限。其横跨16种任务、涵盖10种LGM与21种专家模型及全能模型的架构,精准回应了生成模型常伴的幻觉(hallucination)与过处理(over-processing)等新兴挑战。通过Bradley-Terry评分与逐图像幻觉标注等密集人工标注,该研究为辨析生成式复原的质量优劣提供了更具生态效度的标尺,对引导未来低层视觉模型向人类感知对齐方向演进具有里程碑式意义。
以上内容由遇见数据集搜集并总结生成


