tabilab/biosses
收藏Hugging Face2024-01-10 更新2024-05-25 收录
下载链接:
https://hf-mirror.com/datasets/tabilab/biosses
下载链接
链接失效反馈官方服务:
资源简介:
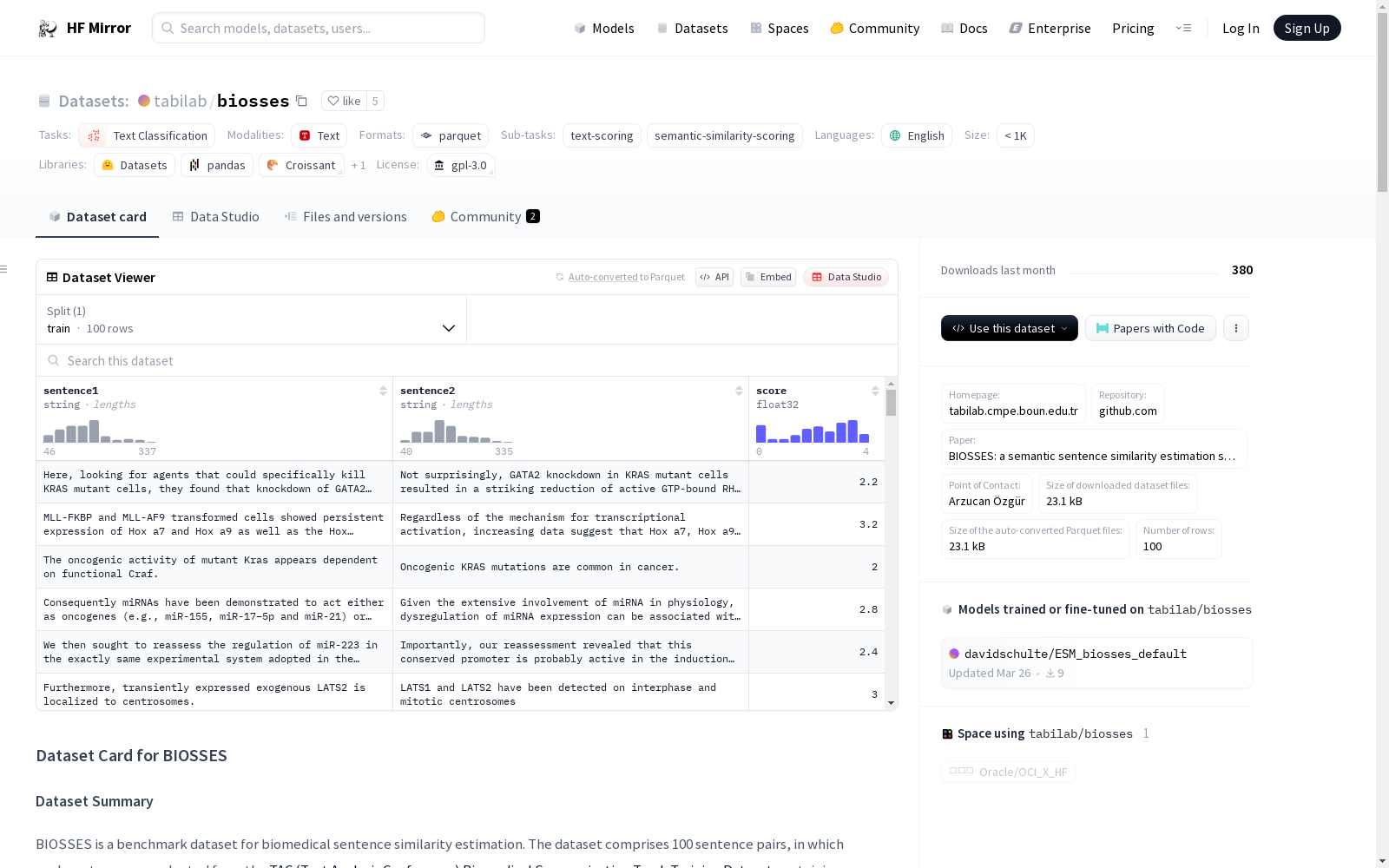
BIOSSES是一个用于生物医学句子相似性估计的基准数据集。该数据集包含100个句子对,每个句子对选自TAC(文本分析会议)生物医学摘要跟踪训练数据集中的生物医学领域文章。句子对由五位不同的人类专家评估其相似性,并给出0(无关系)到4(等价)的评分。在原始论文中,五位人类注释者评分的平均值被作为黄金标准。使用Pearson相关系数作为评估指标,评估模型估计的评分与黄金标准评分之间的相关性。
BIOSSES is a benchmark dataset for biomedical sentence similarity estimation. This dataset contains 100 sentence pairs, each selected from biomedical articles in the training dataset of the TAC (Text Analysis Conference) biomedical summarization track. Each sentence pair was evaluated for similarity by five distinct human experts, with scores ranging from 0 (no relation) to 4 (equivalent). In the original paper, the average of the five human annotators' scores was used as the gold standard. The Pearson correlation coefficient is employed as the evaluation metric to assess the correlation between the scores estimated by the model and the gold standard scores.
提供机构:
tabilab
原始信息汇总
数据集概述
数据集名称
- 名称: BIOSSES
- 别名: BIOSSES
数据集基本信息
- 语言: 英语
- 许可证: GPL-3.0
- 多语言性: 单语
- 大小类别: 小于1K
- 源数据集: 原始
- 任务类别: 文本分类
- 任务ID: 文本评分, 语义相似度评分
数据集结构
- 特征:
- sentence1: 字符串
- sentence2: 字符串
- score: 浮点数(32位)
- 数据分割:
- 训练集: 100个样本, 32775字节
数据集创建
- 来源数据: TAC (Text Analysis Conference) Biomedical Summarization Track Training Dataset
- 注释: 由五位不同的人类专家评估句子对相似性并给出评分,评分范围从0(无关)到4(等同)。
使用数据集的注意事项
-
许可证: 根据GNU通用公共许可证v.3.0提供
-
引用信息:
@article{souganciouglu2017biosses, title={BIOSSES: a semantic sentence similarity estimation system for the biomedical domain}, author={So{u{g}}anc{i}o{u{g}}lu, Gizem and {"O}zt{"u}rk, Hakime and {"O}zg{"u}r, Arzucan}, journal={Bioinformatics}, volume={33}, number={14}, pages={i49--i58}, year={2017}, publisher={Oxford University Press} }
搜集汇总
数据集介绍
构建方式
BIOSSES数据集的构建基于TAC (Text Analysis Conference) Biomedical Summarization Track Training Dataset,该数据集包含了来自生物医学领域的文章。数据集由100对句子组成,每对句子均来自引用同一篇参考文章的句子。这些句子对由五位专家进行相似度评估,并给出0至4的评分。评分过程依据SemEval 2012 Task 6的指南进行,并提供了生物医学文献中的示例句子以辅助评分者理解不同相似度等级的标准。
特点
BIOSSES数据集的特点在于其专注于生物医学领域的句子语义相似度评估,提供了一个专家生成的评分标准。数据集的单语性确保了研究者在特定领域内的语义相似度评估任务中能够获得一致和准确的结果。此外,数据集的构建考虑了不同专家评分间的高度一致性,增强了评分的可信度。
使用方法
使用BIOSSES数据集时,研究者可以将其作为基准数据集来评估和比较不同模型的生物医学句子语义相似度评分性能。数据集提供的句子对和相应的相似度评分可以直接用于训练和测试模型。用户需要遵循GNU通用公共许可证v.3.0的条款使用此数据集,并在研究中正确引用数据集来源。
背景与挑战
背景概述
BIOSSES数据集,全称为Biomedical Sentence Semantic Similarity Estimation System,是由土耳其博阿兹奇大学的研究团队创建的,旨在为生物医学领域的句子语义相似度估计提供基准。该数据集的创建时间是2017年,由Gizem Soğancıoğlu、Hakime Öztürk和Arzucan Özgür等研究人员负责。核心研究问题是评估和比较不同模型在生物医学文献中句子对的语义相似度。该数据集对生物医学文本挖掘、信息检索和自然语言处理领域产生了显著影响,为相关任务提供了评价标准。
当前挑战
BIOSSES数据集面临的挑战主要包括:1)领域专有名词和复杂句子结构的处理,这要求模型具有较高的语义理解能力;2)数据集规模较小,包含的句子对只有100对,这限制了模型的训练和评估;3)人类标注的主观性,尽管标注者之间的相关性较高,但仍然存在一定偏差;4)构建过程中,如何确保所选句子对具有代表性,且覆盖生物医学领域的多样性,是一个难点。
常用场景
经典使用场景
在生物医药领域中,BIOSSES数据集被广泛用于评估句子间的语义相似度。其经典的使用场景在于,研究人员通过该数据集对模型进行训练和测试,以判断模型在理解生物医药文献中句子间相似度的能力,进而提高模型在生物医学文本挖掘任务中的表现。
实际应用
实际应用中,BIOSSES数据集可以被应用于生物医学文献的检索、摘要以及知识发现等任务。通过利用数据集训练出的模型,可以更准确地识别和提取生物医学研究中的关键信息,从而促进医学研究的进展和医疗决策的优化。
衍生相关工作
基于BIOSSES数据集,研究者们衍生出了一系列相关工作,包括开发新的语义相似度计算模型、构建基于深度学习的相似度评估框架,以及探索在多语言环境下生物医学文本的语义相似度计算方法,这些工作进一步推动了生物医学自然语言处理领域的发展。
以上内容由遇见数据集搜集并总结生成


